
在Klustron中管理JSON数据类型
在Klustron中管理JSON数据类型
从Klustron-1.3版本开始,Klustron全面支持JSON数据管理,包括创建和使用JSON路径索引,把计算节点中大多数JSON函数和运算符下推到存储节点执行,以存储节点内部二进制格式来在计算节点和存储节点之间交换数据,等等。 首先介绍Klustron中JSON数据类型,然后介绍如何将JSON格式的数据导入到Klustron中,并展示JSON格式数据的查询和过滤,创建和使用JSON路径索引,以及使用JSON对象内部的字段和其他普通表字段进行连接的案例。
01 JSON 数据类型
JSON(JavaScript Object Notation、JavaScript 对象表示法)是一种轻量级的数据交换格式,采用完全独立于编程语言的文本格式来存储和表示数据。JSON 易于阅读和编写,同时也方便机器解析和生成,并且能够有效地提升网络传输效率。在网络数据传输领域,JSON 已成为了 XML 强有力的替代者。
Klustron提供了两种 JSON 数据类型:JSON 以及 JSONB。这两种类型主要的区别在于数据存储格式,JSONB 使用二进制格式存储数据,更易于处理。
下表描述了两种数据类型之间的区别:
| 功能 | JSON | JSONB |
|---|---|---|
| 存储格式 | 字符串原文存储 | 解析后的二进制 |
| 全文索引 | 不支持 | 支持 (1.3版本支持) |
| 保留空白符 | 保留 | 不保留 |
| 保留键的顺序 | 保留 | 不保留 |
| 保留重复键 | 保留 | 不保留 |
由于存储格式的不同,JSONB 插入时稍微慢一些(需要转换),但是查询时快很多。文章接下来的内容主要使用 JSONB 数据类型,但是大部分功能也可以使用 JSON 数据类型。
02 数据库中使用 JSON 字段
创建一个产品表product
CREATE TABLE product (
id INT NOT NULL PRIMARY KEY,
product_code VARCHAR(10),
product_name VARCHAR(100),
attributes JSONB
);
产品表 product 中包含一个 JSONB 类型的字段 attributes,用于存储产品的属性。
JSON 字段赋值我们可以直接使用字符串为JSON字段赋值,但是要求数据必须是有效的 JSON 格式,否则将会返回错误。执行以下语句插入一条产品记录:
INSERT INTO product (id, product_code, product_name, attributes)
VALUES (1, '101','椅子','{"color":"棕色", "material":"实木", "height":"60cm"}');
接下来我们插入一条不符合 JSON 格式的数据:
INSERT INTO product (id, product_code, product_name, attributes)
VALUES (2, '102','沙发椅', '"color":"白色:50cm}');

以上插入JSON数据的方法虽然使用简单,但是输入比较麻烦。为此,Klustron还提供了一些方便生产 JSON 数据的函数。jsonb_build_object 函数可以通过一系列输入创建二进制的 JSON 对象,例如:
INSERT INTO product (id,product_code,product_name, attributes)
VALUES (3,'103','小型桌子', JSONB_BUILD_OBJECT('color', '黑色', 'material', '塑料'));
其他常用的构建 JSON 数据的函数如下:
- json_build_object
- to_json
- to_jsonbarray_
- to_json
- row_to_json
- json_build_array
- jsonb_build_array
- json_object
- jsonb_object
JSON 字段的查询和普通字段没有什么区别,例如:

我们不仅可以查询整个 JSON 字段,也可以提取 JSON 数据中指定节点的属性值。例如:
_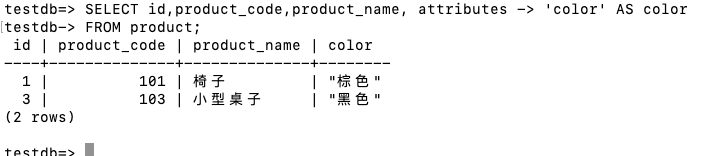
运算符 -> 可以通过指定节点的键获取相应的数据。这种方法返回的数据仍然是 JSON 类型,使用双引号包含。如果想要以字符串形式返回节点中的数据值,可以使用运算符 ->>。例如:

关于Klustron的JSON数据类型的其他用法请查看链接:
https://downloads.kunlunbase.com/docs_cn/html_cn/datatype-json.html
03 JSON 数据类型进行复杂查询的案例
首先创建两张表sales_order和product
create table sales_order
(
order_number INT NOT NULL AUTO_INCREMENT,
customer_number INT NOT NULL,
product_code INT NOT NULL,
order_date DATETIME NOT NULL,
entry_date DATETIME NOT NULL,
order_amount DECIMAL(18,2) NOT NULL,
primary key(order_number)
);
create table product
(
product_code INT NOT NULL AUTO_INCREMENT,
product_name VARCHAR(128) NOT NULL,
product_category VARCHAR(256) NOT NULL,
PRIMARY KEY (product_code)
) ;
给sales_order插入1000000行数据,同时向product中插入1000行数据。
create or replace procedure generate_order_data()
AS $$
DECLARE
v_customer_number integer;
v_product_code integer;
v_order_date date;
v_amount integer;
start_date date := to_date('2021-01-01','yyyy-mm-dd');
i integer :=1;
BEGIN
while i<=1000000 loop
v_customer_number := FLOOR(1+RANDOM()*6);
v_product_code := FLOOR(1+RANDOM()*500);
v_order_date := to_date('2021-01-01','yyyy-mm-dd') + CAST(FLOOR(RANDOM()*365) AS INT);
v_amount := FLOOR(1000+RANDOM()*9000);
insert into sales_order VALUES (i,v_customer_number,v_product_code,v_order_date,v_order_date,v_amount);
commit;
i := i+1;
end loop;
END; $$
LANGUAGE plpgsql;
create or replace procedure generate_product_data()
AS $$
DECLARE
v_product_name varchar(128);
i integer :=1;
BEGIN
while i<=1000 loop
case mod(i,3)
when 0 then
v_product_name := 'Hard Disk '||i;
INSERT INTO product VALUES (i,v_product_name,'Storage');
when 1 then
v_product_name := 'LCD '||i;
INSERT INTO product VALUES (i,v_product_name,'Monitor');
when 2 then
v_product_name := 'Paper'||i;
INSERT INTO product VALUES (i,v_product_name,'Paper');
end case;
commit;
i := i+1;
end loop;
END; $$
LANGUAGE plpgsql;
set statement_timeout=0;
call generate_order_data();
call generate_product_data();
然后将sales_order中的数据转化为JSONB类型,并最终插入到sales_order_json表中,数据量同样也是1000000行。
create table sales_order_json_seed (
order_detail jsonb);
insert into sales_order_json_seed SELECT row_to_json("sales_order") FROM sales_order;
create table sales_order_json (
order_number int NOT NULL,
order_detail jsonb,
primary key(order_number));
insert into sales_order_json select (order_detail->'order_number')::integer, order_detail from sales_order_json_seed;
3.1 单表涉及 JSON 字段的查询
查询2021年一月份的销售总额,可以用下面的SQL进行查询。这里取得JSON字段对应order_date属性的值(order_detail->>’order_date’),由于取出的属性值为字符串,还需要通过::DATETIME的方式将其映射为时间类型。
select sum((order_detail->>'order_amount')::DECIMAL(18,2)) from sales_order_json where
(order_detail->>'order_date')::DATETIME between '2021-01-01' and '2021-01-31';

可以在普通sales_order表上运行相同的SQL去印证汇总的结果。
select sum(order_amount) from sales_order where order_date between '2021-01-01' and '2021-01-31';

3.2 在 JSON 对象字段进行两表连接
查询2021年1月份所有LCD品类的销售总额。具体查询的SQL如下:
select sum((order_detail->>'order_amount')::DECIMAL(18,2)) from sales_order_json t1,product t2 where
(order_detail->>'product_code')::integer = t2.product_code and (order_detail->>'order_date')::DATETIME between '2021-01-01' and '2021-01-31' and t2.product_name like 'LCD%';
查询结果如下:

同样也可以在普通的sales_order表上进行验证
select sum(order_amount) from sales_order t1,product t2 where t1.product_code = t2.product_code
and t1.order_date between '2021-01-01' and '2021-01-31'
and t2.product_name like 'LCD%';
结果和使用sales_order_json表一致

3.3 创建和使用 JSON 路径索引
准备数据
test1=# create table gears(id serial primary key, name varchar(64), size jsonb, unit text generated always as (size->'unit') virtual);
CREATE TABLE
test1=# insert into gears(name, size) values('shaft','{"height":200, "width": 100,"unit":"mm"}');
INSERT 0 1
test1=# insert into gears(name, size) values('bolt','{"height":40, "width": 10,"unit":"mm"}');
INSERT 0 1
test1=# alter table gears add column height int generated always as (int4(size->'height')) virtual;
ALTER TABLE
test1=# alter table gears add column width int generated always as (int4(size->'width')) virtual;
ALTER TABLE
test1=# select*from gears;
id | name | size | unit | height | width
----+-------+---------------------------------------------+------+--------+-------
1 | shaft | {"unit": "mm", "width": 100, "height": 200} | "mm" | 200 | 100
2 | bolt | {"unit": "mm", "width": 10, "height": 40} | "mm" | 40 | 10
(2 rows)
test1=# create index gears_h on gears(height);
CREATE INDEX
首先准备数据如上。CREATE TABLE语句中创建了virtual 产生列unit,然后在后续的两个ALTER TABLE语句中分别创建了virtual产生列height和width。这三个产生列在存储节点中不占据外存空间,在查询到的时候才计算出来。 然后用height列创建了索引gears_h,这个索引就是一个JSON路径索引。注意下面查询的时候显式指定了height=40 unit='"mm"'这两个条件,用到了被索引的虚拟列。从下面的计算节点的查询计划可以看到,这个过滤条件被下推到了存储节点执行;从下面存储节点的查询计划可以看到这个查询在存储节点执行时用到了gears_h和gears_unit这两个路径索引。
计算节点中的查询执行结果以及查询计划
test1=# explain select*from gears where height=40;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
RemotePlan (cost=102.05..102.05 rows=1 width=222)
Shard: 4 Remote SQL: SELECT gears.id,gears.name,gears.size,gears.unit,gears.height,gears.width FROM `test1_$$_public`.`gears` WHERE (gears.height = cast(? as signed))
(2 rows)
test1=# select*from gears where height=40;
id | name | size | unit | height | width
----+------+-------------------------------------------+------+--------+-------
2 | bolt | {"unit": "mm", "width": 10, "height": 40} | "mm" | 40 | 10
(1 row)
test1=# create index gears_unit on gears(unit);
CREATE INDEX
test1=# select*from gears where unit='"mm"';
id | name | size | unit | height | width
----+-------+---------------------------------------------+------+--------+-------
1 | shaft | {"unit": "mm", "width": 100, "height": 200} | "mm" | 200 | 100
2 | bolt | {"unit": "mm", "width": 10, "height": 40} | "mm" | 40 | 10
(2 rows)
test1=# explain select*from gears where unit='"mm"';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
RemotePlan (cost=102.05..102.05 rows=1 width=222)
Shard: 4 Remote SQL: SELECT gears.id,gears.name,gears.size,gears.unit,gears.height,gears.width FROM `test1_$$_public`.`gears` WHERE (gears.unit = cast(? as char) collate `utf8mb4_0900_bin`)
(2 rows)
对应于上述查询的发送到存储节点中的查询计划
mysql> explain SELECT gears.id,gears.name,gears.size,gears.unit,gears.height,gears.width FROM `test1_$$_public`.`gears` WHERE (gears.height = cast(40 as signed));
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | gears | NULL | ref | gears_h | gears_h | 5 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> explain SELECT gears.id,gears.name,gears.size,gears.unit,gears.height,gears.width FROM `test1_$$_public`.`gears` WHERE (gears.unit = cast("\"mm\"" as char) collate `utf8mb4_0900_bin`);
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | gears | NULL | ref | gears_unit | gears_unit | 259 | const | 2 | 100.00 | Using where |
+----+-------------+-------+------------+------+---------------+------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
3.4 JSON 对象在 InnoDB 和 RocksDB 两种存储引擎下的比较
将从互联网上获取的大的JSON对象导入到Klustron中,注意需要将其转换为NDJSON的格式才能导入到Klustron中。
create table temp(data jsonb);
\COPY temp (data) FROM '/home/kunlun/json/1.json';
\COPY temp (data) FROM '/home/kunlun/json/2.json';
一共导入了10000个JSON对象,查询JSON对象中的id字段。测试导入是否正常。
_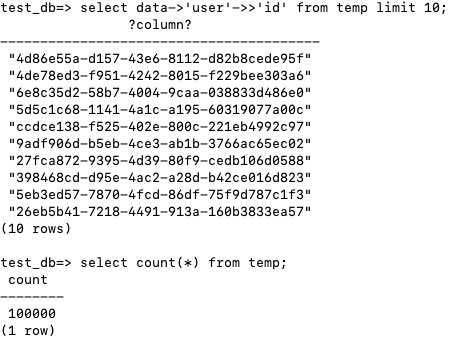
检查temp表的大小为787.52M。
_
创建RocksDB存储引擎的表,检查所占用的存储空间大小。
create table temp_rdb(data jsonb) with (engine=rocksdb);
\COPY temp (data) FROM '/home/kunlun/json/1.json';
\COPY temp (data) FROM '/home/kunlun/json/2.json';
_
数据在RocksDB存储引擎下进行了压缩存放。
3.5 JSON 对象读写性能测试
由于测试是在虚拟机上进行的,文章中的执行时间只能用作在相同环境下不同场景之间的对比参考。测试集群相关虚拟机的配置信息如下:
| 节点类别 | 名称 | IP | CPU | 内存 |
|---|---|---|---|---|
| 计算节点 | 10.37.129.6 | 2C Intel i9 2.4 GHz | 6G | |
| 存储主节点 | shard_1 | 10.37.129.5 | 2C Intel i9 2.4 GHz | 6G |
| 存储主节点 | shard_2 | 10.37.129.7 | 2C Intel i9 2.4 GHz | 6G |
通过上一节的temp表创建一个新的表test1,并灌入数据。
create table test1 (id int primary key, content jsonb);
CREATE SEQUENCE
test_id_seq
INCREMENT 1
MINVALUE 1
MAXVALUE 9223372036854775807
START WITH 1
CACHE 1;
insert into test1 select nextval('test_id_seq'),data from temp;
analyze test1;
使用pgbench工具对test1表进行读写性能测试。准备custom.sql内容如下:
\set id random(1,100000)
BEGIN;
select * from test1 where id = :id;
update test1 set content=jsonb_set(content,'{user,email}','"klustron@mail.com"') where id = :id;
END;
参数为10个连接,运行压力测试2分钟
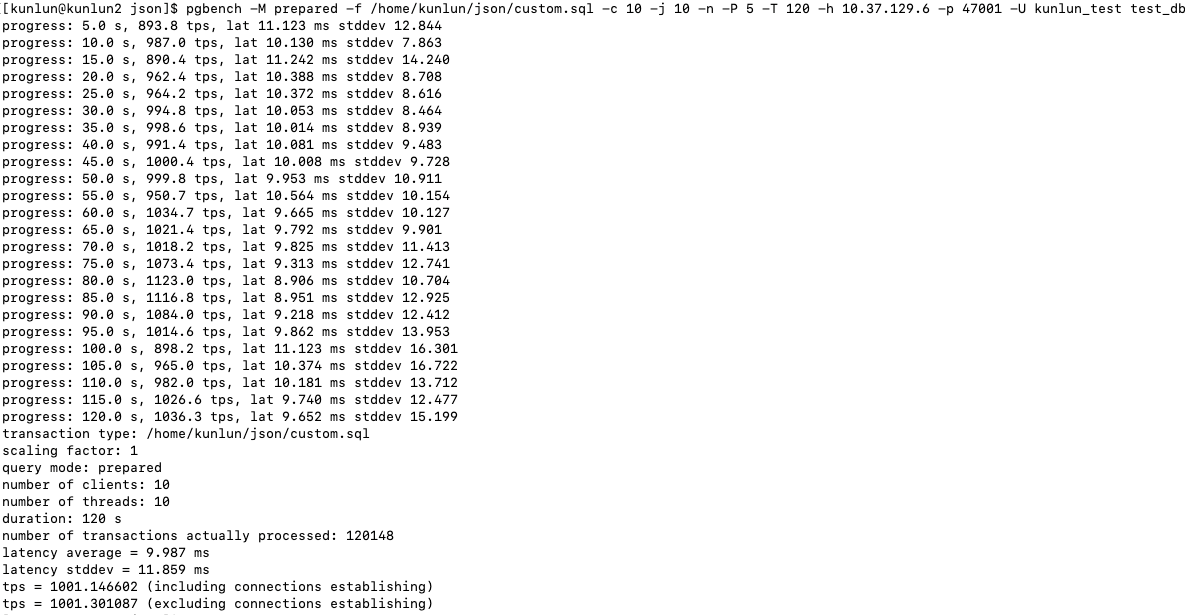
对Json对象读写的效率在当前环境下10个连接平均能达到1001 tps