
Klustron使用oracle_fdw访问Oracle
Klustron使用oracle_fdw访问Oracle
注意:
如无特别说明,文中的版本号可以使用任何已发布版本的版本号代替。所有已发布版本详见 Release_notes:
概述
Klustron提供FDW(Foreign Data Wrappers) 作为访问各种外部数据源的机制。本文介绍如何在Klustron配置oracle_fdw 访问Oracle 数据库的表,然后展示来自不同数据源多表连接的场景。
01 oracle_fdw 介绍
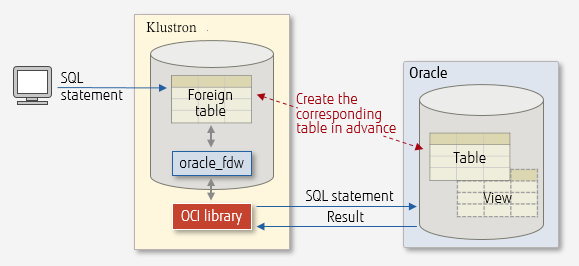
oracle_fdw 扩展是一个FDW,允许用户通过外部表访问 Oracle 表和视图(包括物化视图)。
当 PostgreSQL 客户端访问外部表时,oracle_fdw 通过 PostgreSQL 服务器上的 Oracle 调用接口 (OCI) 库访问外部 Oracle 数据库中的相应数据。
具体oracle_fdw的工作流程见下图:
02 具体配置过程
下文中操作用户如无特别注明,则都是Klustron的安装用户kunlun。
2.1 下载 oracle_fdw 软件包
具体下载地址为:https://github.com/laurenz/oracle_fdw ,下载到路径
/kunlun/fdw/oracle,并解压
cd /kunlun/fdw/oracle
unzip oracle_fdw-master.zip
2.2 安装 Oracle 客户端软件
在所有的计算节点安装Oracle 11.2.0.4的客户端,选择”Administator”版本的客户端。安装过程略。客户端具体安装路径为
/kunlun/fdw/oracle/11.2.0/client_1
并且在kunlun 用户的/home/kunlun/.bash_profile下面增加了下面的环境变量:
export ORACLE_HOME=/kunlun/fdw/oracle/11.2.0/client_1
export PATH=$ORACLE_HOME/bin:$PATH
export LD_LIBRARY_PATH=$ORACLE_HOME/lib:$LD_LIBRARY_PATH
2.3 Oracle 客户端配置
将ORACLE_HOME环境变量配置到Klustron计算节点的服务器进程中(如果有多个计算节点,则每个节点都需要做下面的配置)。修改文件 /kunlun/kunlun-node-manager-1.3.1/bin/extra.env
在文件末尾增加下面的环境变量:
ORACLE_HOME=/kunlun/fdw/oracle/11.2.0/client_1; #KUNLUN_SET_ENV
LD_LIBRARY_PATH=$ORACLE_HOME/lib:$LD_LIBRARY_PATH
export ORACLE_HOME; #KUNLUN_SET_ENV
export LD_LIBRARY_PATH
并重启计算节点的node manager服务。
ORACLE_HOME=/kunlun/fdw/oracle/11.2.0/client_1; #KUNLUN_SET_ENV
LD_LIBRARY_PATH=$ORACLE_HOME/lib:$LD_LIBRARY_PATH
export ORACLE_HOME; #KUNLUN_SET_ENV
export LD_LIBRARY_PATH
2.4 安装 oracle_fdw
确保kunlun用户能直接运行pg_config命令。
执行下面的命令安装oracle_fdw
cd /kunlun/fdw/oracle/oracle_fdw-master/
make
make install
2.5 装载 oracle_fdw 扩展
首先创建Klustron用户和数据库
psql -h 192.168.40.152 -p 47001 postgres
create user kunlun_test with superuser password 'kunlun';
create database testdb owner kunlun_test;
grant all privileges on database testdb to kunlun_test;
\q
以用户kunlun_test登陆testdb,然后装载oracle_fdw扩展
psql -h 192.168.40.152 -p 47001 -U kunlun_test testdb
CREATE EXTENSION oracle_fdw;
检查oracle_fdw是否安装成功

2.6 Oracle 数据库准备
在Oracle数据库中执行下面的SQL:
sqlplus / as sysdba
create user orauser identified by oracle;
grant dba to orauser;
con orauser/oracle
create table employee ( id int primary key, name varchar2(10));
insert into employee values(1,'Jack');
insert into employee values(2,'Tom');
commit;
Oracle 版本为11.2.0.4,服务器IP为192.168.40.163,监听端口1521,服务名为testdb
2.7 在 Klustron 中使用 oracle_fdw
创建外部服务器server,配置到Oracle数据库的连接
CREATE SERVER oradb FOREIGN DATA WRAPPER oracle_fdw OPTIONS (dbserver
'//192.168.40.163:1521/testdb');
-- oradb: 自定义一个 SERVER NAME
-- OPTIONS: 有3个参数--dbserver、isolation_level、nchar
-- dbserver(必需):定义连接 Oracle 数据库的连接字符串。
-- isolation_level(可选,默认为 serializable): 在 Oracle 数据库中使用的事务隔离级别,可设置的参数值 serializable、read_committed、read_only。
-- nchar(可选,默认为 off): 是否开启 Oracle端的字符转换,这个参数的开启对性能有很大影响。
查看已经创建的Server

创建Klustron到Oracle之间的映射
CREATE USER MAPPING FOR kunlun_test SERVER oradb OPTIONS (user 'orauser',
password 'oracle');
-- kunlun_test:Klustron中已存在的用户
-- oradb: 已创建的 SERVER NAME
-- OPTIONS: 有2个参数--user、password
-- user(必需):Oracle用户名
-- password(必需):Oracle用户的密码
查看刚刚创建映射关系

在Klustron中创建外部表与Oracle表关联
CREATE FOREIGN TABLE ora_emp
( empno NUMERIC(4,0) OPTIONS (key 'true') NOT NULL
, ename VARCHAR(10)
)
SERVER oradb OPTIONS (schema 'ORAUSER', table 'EMPLOYEE');
请注意:
- 外部表的表名和字段名不需要与 Oracle 的表保持一致,但是字段顺序需要与 Oracle 的表保持一致
- 外部表的主键需要与 Oracle 的表保持一致
- OPTIONS 属性里的 schema 和 table 名称必须大写,不然Klustron端操作外部表会报 ‘ORA-00942: table or view does not exist’。
- OPTIONS 属性里的 schema 和 table 必须用单引号
- 必须定义 oracle_fdw 可以转换的列
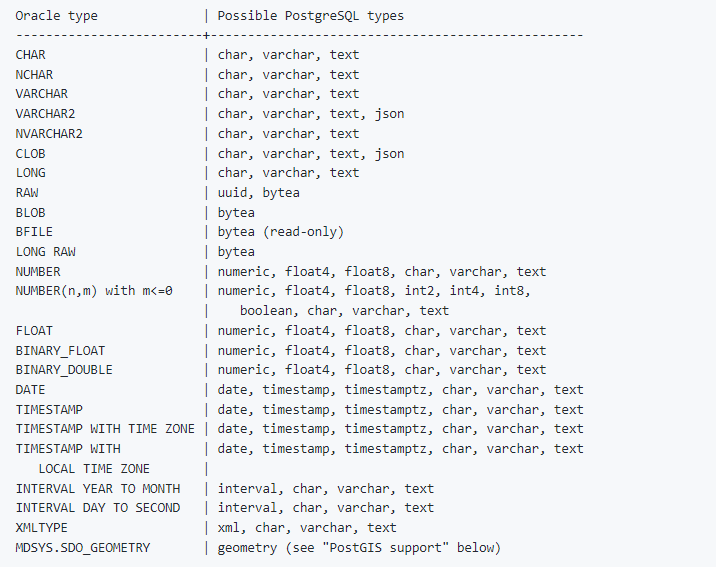
如果数据的长度超过了实际的列长度,就会出现运行时错误。另外请注意,数据类型的行为可能不同,例如浮点数据类型和日期时间数据类型中的分数舍入。
另外默认情况下,Oracle 中 CHAR 和 VARCHAR2 类型的长度以字节为单位指定,而Klustron的 CHAR、VARCHAR 和 TEXT 类型的长度以字符为单位指定。
创建外部表完毕后,可以执行查询从Klustron访问Oracle的表

在Klustron批量创建外部表
如果在Klustron中需要查询Oracle的表很多,例如需要查询orauser schema下面的所有表。那么可以通过下面的方法进行外部表批量创建:
IMPORT FOREIGN SCHEMA "ORAUSER" FROM SERVER oradb INTO public;
首先在Oracle的orauser下创建一张新表salary, 并插入数据:
create table salary (id int primary key, amount int);
insert into salary values(1,10000);
insert into salary values(2,5000);
commit;
然后在Klustron下执行:
drop foreign table ora_emp;
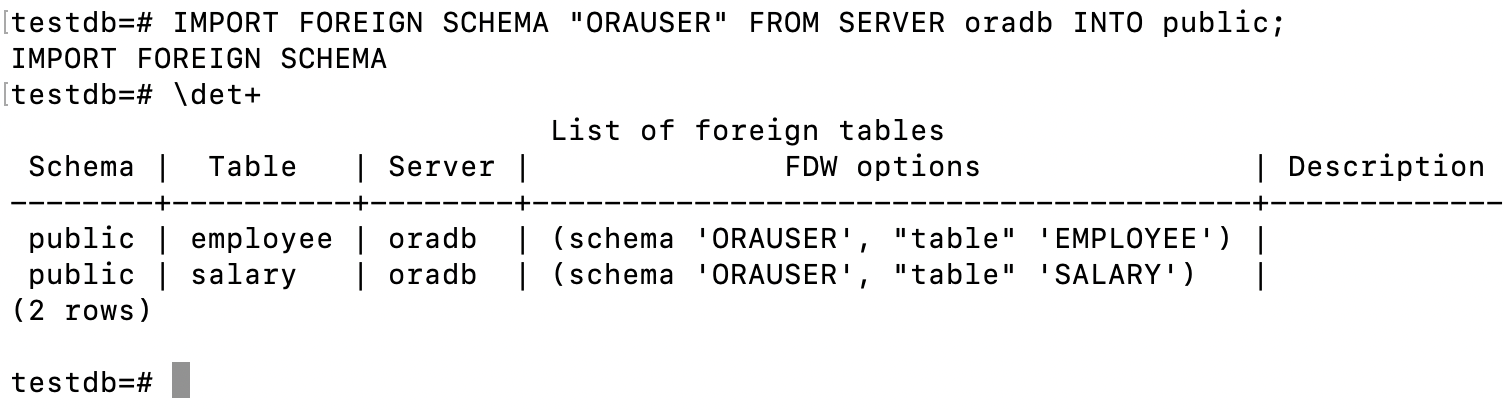
IMPORT FOREIGN SCHEMA "ORAUSER" FROM SERVER oradb INTO public;
IMPORT FOREIGN SCHEMA 需要注意的事项有:
- 这种方式不需要指定表结构,但是外部表名与Oracle表名需要一致,也就是当前Klustron的SCHEMA下不能存在同名表,否则创建失败。
- Oracle SCHEMA 名称通常为大写。由于Klustron在处理之前将名称转换为小写,因此您必须用双引号保护 SCHEMA 名称(例如"ORAUSER")。
- LIMIT TO 导入括号内包含的表,多个表以逗号分隔,EXCEPT 导入不包含(排除)括号内的表,多个表以逗号分隔
这种方式可以导入指定名称的表,例如:
IMPORT FOREIGN SCHEMA "ORAUSER" limit to (SALARY) from server oradb into public;
IMPORT FOREIGN SCHEMA "ORAUSER" limit to (EMPLOYEE,SALARY) from server oradb into public;
查看已经创建的外部表:
进行相应的查询

2.8 外部表多表连接
首先在Klustron中创建kl_salary表
create table kl_salary (id int primary key, amount money);
insert into kl_salary values (1,10000.00);
insert into kl_salary values (2,8888.88);
参考《Klustron使用tds_fdw访问MSSQL》文章在MSSQL中准备下面的数据:
create table empinfo (id int primary key, firstday varchar(10));
insert into empinfo values(1,'2018-09-01');
insert into empinfo values(1,'2010-07-15');
并在Klustron中创建tds_fdw和外部表mssql_empinfo去关联MSSQL中的empinfo表。
之后用户可以执行下面的多表Join,分别从Klustron,Oracle和MSSQL中获取数据进行Join
select ora.ename,kl.amount,ms.firstday from kl_salary kl, ora_emp ora, mssql_empinfo ms
where kl.id=ora.empno and kl.id=ms.id;

查看执行计划
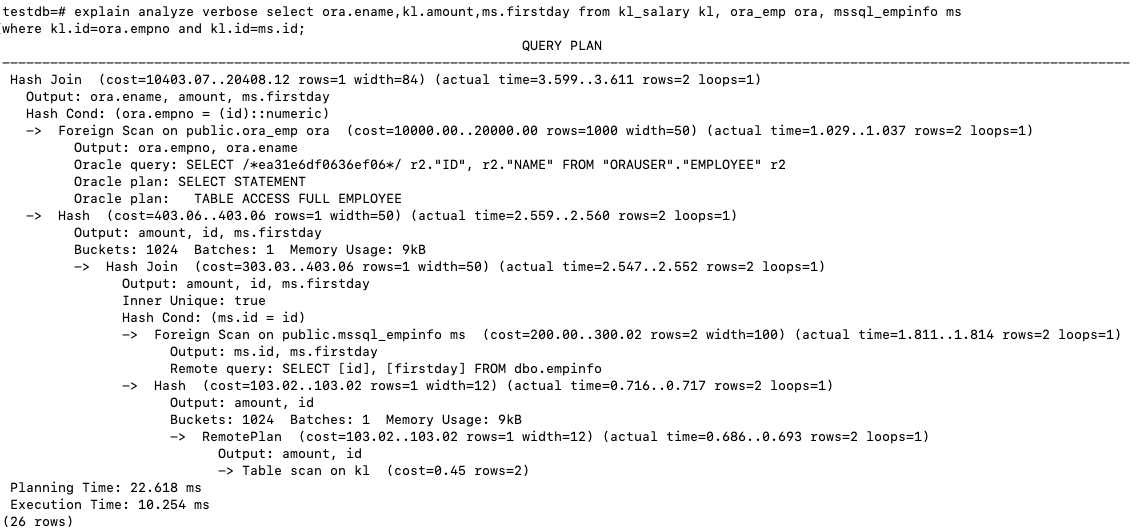
可以看到分别从Klustron, Oracle和MSSQL中获取表的数据进行Join。
03 重点说明
用户使用泽拓昆仑Klustron集群时,如果在一个事务中写入集群内部数据的同时,还使用计算节点的FDW 接口写入若干个外部数据库系统,那么那些外部数据库系统并不是这个分布式事务的事务分支,Klustron不会对外部数据库系统做两阶段提交或者故障恢复。
这样做在全局事务层面对于写入外部数据库的数据更新,没有Klustron集群层面的任何ACID保障或者数据一致性和故障恢复保障。假如做此写入时Klustron集群的计算节点或者外部数据库实例刚好意外退出(比如服务器断电),那么可能会有部分外部数据库的数据更新已经提交,另一些未提交。并且如果外部数据源自身不支持事务处理,那么在写入这样的数据源期间发生故障的话,还可能导致外部数据源的数据损坏,丢失或者不一致。