
触发器功能介绍
触发器功能介绍
首先得提一下触发器函数,触发器函数与用户自定义函数类似,也是用户自定义的“函数”,不同的是触发器函数不需要在 sql 中显示调用执行,而是由数据库系统在特定事件发生时自动去执行的(例如表/视图上的增删改等)。因此,用户的在创建触发器函数这一特殊“函数”时,除了定义函数体之外,还需要指定该“函数”的执行时机,即指定”哪些事件“(增/删/该)发生在”哪个对象“(表/视图)之前/后时执行触发器函数,这样以来,一个完整的触发器就创建出来了。
所以触发器共包含两部分内容:1、触发器函数;2、触发器的定义(即定义触发器函数的执行时机)。
触发器的特性使其成为数据审计、保证数据一致性的强大工具,例如可以使用触发器自动记录表上的增删改操作,使用触发器实现跨越多个表的约束检查或者实现多个表的级联更新等等。另外一个有意思的地方,PG的外键便是基于触发器实现的。
目前,大部分成熟的数据库产品都提供了触发器的功能,Klustron 自然也不例外(版本 1.2 开始支持)。本文将详细介绍触发器的实现原理,帮助用户更好地使用触发器。
原理
Klustron 支持行级和语句级两种级别的触发器。
- 行(row)级的触发器。针对每行修改的元组调用一次函数;
- 语句(statement)级触发器。针对每条增删改语句调用一次函数;
一、行级触发器
行触发器又分为前触发器和后触发器,分别在修改某一行元组的前后执行,其大致的处理逻辑如下面的流程图所示。可以看到前触发器在修改具体的行前立即执行,而后触发器并没有立即执行,而是将其缓存起来(包括执行所需要的信息,例如行修改前后的状态等),当所有元组都更新完毕之后,这些缓存的后触发器才会执行。
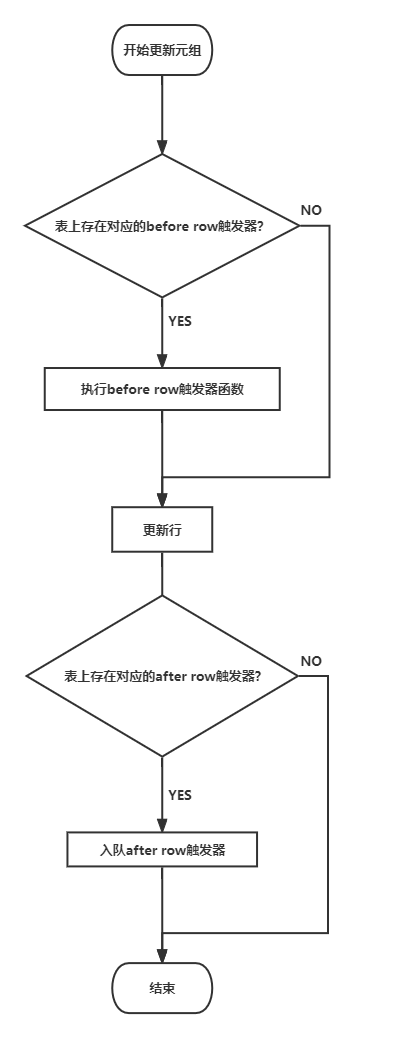
二、语句级触发器
行级触发器类似,语句级触发器也分为前触发器和后触发器,其中前触发器在 DML 执行之前会执行,而后触发器在 DML 执行完之后才会执行。和行后触发器类似,语句级后触发器也是先被加入到触发器缓冲队列中的,然后再由数据库系统统一遍历并执行触发器队列中缓存的所有after触发器(包括行级和语句级的触发器)。其大致的处理逻辑如下图所示。
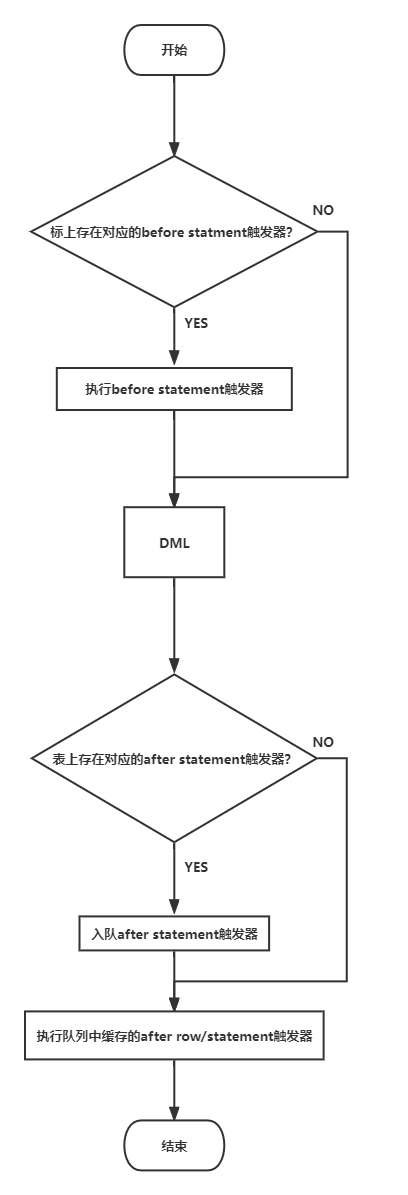
三、触发器参数
和普通的用户自定义函数不同,触发器函数是由数据库系统自动调用执行的。在调用普通的函数时,我们可以指定传入的参数,那么对于由数据库系统自动调用的触发器函数,它的参数是什么?又是如何传入的呢? 其实触发器函数被要求声明为无参数的,但是数据库系统在调用它时向它传递了一个“执行上下文”,这个上下文中包含了触发器函数调用时数据的状态变化信息以及创建触发器时事先存放传递的信息,触发器函数就是通过这个上下文执行差异化的操作的。
如下所示的TriggerData结构体便是触发器的上下文信息。
typedef struct TriggerData
{
NodeTag type;
TriggerEvent tg_event; // 事件(更新、插入或者删除事件)
Relation tg_relation; // 触发器所针对的表
HeapTuple tg_trigtuple; // 更新前的元组值
HeapTuple tg_newtuple; // 更新后的元组值
...
Tuplestorestate *tg_oldtable; // 所有被更新的元组在更新前的值
Tuplestorestate *tg_newtable; // 所有被更新的元组在更新后的值
} TriggerData;
当然,触发器函数并不是直接访问这个上下文结构体的成员,而是通过事先约定好的变量名来访问(触发器函数一般使用 plpgsql 语句来书写,简单起见,后续的讲解默认使用的是plpgsql)。例如通过OLD和NEW变量名分别表示元组更新前后的值,通过引用这两个变量就能访问上下文结构体中tg_rigtuple和tg_newtuple成员了。更多预先定义变量名及其含义可以参考文档.
另外,结构体中的tg_oldtable和tg_newtable两个成员,它们分别存储 DML 语句执行期间更新的所有元组的状态(即更新前后的值),它主要用于语句级的后触发器。根据前面介绍,行级后触发器和语句级后触发器的一样,也是在 DML 语句执行完毕之后才执行的,因此行级后触发器也能够访问这两个成员。这两个成员是以“表”的形式被触发器函数引用的,并且表名可以在创建触发器的时候自行指定。下面以例子来说明:
-- 创建UPDATE语句级触发器函数.
-- 其中oldtable/newtable用来引用上下文中的tg_oldtable/tg_newtable;
-- 功能:将UPDATE语句执行前后的元组的变化打印出来.
create function dump_update() returns trigger as $$
begin
raise notice 'trigger = %, old table = %, new table = %',
TG_NAME, -- 触发器名称
(select string_agg((a,b)::text, ', ' order by a) from oldtable),
(select string_agg((a,b)::text, ', ' order by a) from newtable);
return null;
end;
$$ language plpgsql;
-- 创建语句级触发器
create trigger update_dump_trigger AFTER UPDATE ON t -- 触发器名称以及触发的时机(更新表t之后)
REFERENCING OLD TABLE AS oldtable -- 触发器函数使用oldtable引用tg_oldtable
NEW TABLE AS newtable -- 触发器函数使用newtable引用tg_newtable
FOR EACH STATEMENT -- 触发器级别(语句级触发器)
EXECUTE PROCEDURE dump_update(); -- 触发器函数
-- 执行UPDATE
postgres=# update t set b=10+b where b=2;
NOTICE: trigger = update_dump_trigger, old table = (AAA,2), (BBB,2), new table = (AAA,12), (BBB,12)
UPDATE 2
然而,这些变量/引用表并不是总是有效。例如,在语句级前触发器中是无法读取上下文中tg_oldtable或tg_newtable,因为此时 DML 语句尚未执行;而INSERT事件触发的行级触发器也无法通过OLD变量去获取元组变更前的状态,因为它只有插入的新值。所幸是,这并不会成为困扰我们使用触发器的难题,结合前面介绍的行、语句级触发器的处理流程,我们可以非常准确地“猜测”出哪些变量在这些触发器中是可用的。
四、触发器返回值
在前面的例子,可以看到触发器函数的返回值类型是TRIGGER,但这只是个伪类型,用来表示标记这个函数只能作为触发器函数来使用。触发器函数真实的返回类型其实是触发器所在的表的元组类型,并且只有行级前触发器的返回值才有意义,其他触发器的返回都会被系统忽略。那么行级前触发器的返回值有什么作用呢?
前面介绍行级触发器的处理流程时为了简单故意跳过,实质上当行级前触发器函数返回nul时,是会直接跳过后续步骤的。如果返回值不为NULL,且事件是INSERT或UPDATE,那么返回值将作为最终新值被存入到表中,这也意味着我们可以干预用户对数据修改,使其符合业务约束(如果没有这种需求,返回NEW即可);对于DELETE事件,只关心返回值是否为null,如果是null则不会执行后续操作(包括删除数据,以及行级后触发器的处理),如果非null则继续往下执行。
五、触发器的创建
更具前面的介绍,我们可以已经触发器函数的与普通函数的区别:借助预定义的变量名来引用上下文中数据变化信息;特殊的返回值类型。除此之外,和其他的普通函数没什么太大区别。这里主要介绍的是触发器的创建,下面是创建触发器的语法规则:
CREATE [ CONSTRAINT ] TRIGGER name -- 触发器名称
{ BEFORE | AFTER | INSTEAD OF } { event [ OR ... ] } -- 触发的时机(BEFORE/AFTER)和触发事件(例如增删改等)
ON table_name -- 触发器针对的表
[ NOT DEFERRABLE | [ DEFERRABLE ] [ INITIALLY IMMEDIATE | INITIALLY DEFERRED ] ] -- 是否延迟执行
[ REFERENCING { { OLD | NEW } TABLE [ AS ] name } [ ... ] ] -- 见上文的'触发器参数'
[ FOR [ EACH ] { ROW | STATEMENT } ] -- 触发器的级别
[ WHEN ( condition ) ] -- 触发器时需要额外满足的条件
EXECUTE { FUNCTION | PROCEDURE } function_name ( arguments ) -- 触发器函数
where event can be one of:
INSERT
UPDATE [ OF column_name [, ... ] ]
DELETE
语法规则中的添加备注信息已经非常详细了,读者可以参考讲解触发器参数时给的例子来体会。这里再补充以下要点:
目前 Klustron 不支持延迟执行触发器(即提交事务时再执行触发器函数)
虽然创建触发器时可以为触发器函数指定的''参数',但触发器函数仍然要求是一个无参数的函数;而这些这些传入的“参数”其实韩式存放在上面提到的上下文中,并且通过系统约定好的名称
TG_ARGV来引用。在更新操作并发量很高或者修改的数据量很大时,行触发器对性能的影响是非常明显的。它不仅阻止了 DML 语句的下推,也使得触发器函数被大量执行。如果我们只关心部分数据的修改,可以在创建触发器时指定
WHEN子句,这样一来只当满足子句的条件时才会执行触发器函数,降低对性能的影响。目前 Klustron 要求创建触发器的表必须存在主键(后续版本可能去除这个限制)。
如果在分区表上创建语句级触发器,只有当用户显示更新分区表时会触发,单独更新分区表的子表不会触发;如果在分区表上创建行级触发器,当用户更新分区表或者单独更新分区表的子表时都会触发。
postgres=# create table t(a int primary key ,b int) partition by range(a); CREATE TABLE postgres=# create table tp1 partition of t for values from (0) to (100); CREATE TABLE postgres=# INSERT INTO T VALUES(1,1); INSERT 0 1 postgres=# postgres=# -- 创建简单的打印信息的触发器函数 postgres=# create or replace function dump() returns trigger as $$ postgres$# begin postgres$# raise notice 'trigger = %', TG_NAME; postgres$# return null; postgres$# end; postgres$# $$ language plpgsql; CREATE FUNCTION postgres=# postgres=# -- 在分区表t上创建DELETE语句级触发器 postgres=# create trigger trigger1 AFTER UPDATE ON t postgres-# FOR EACH STATEMENT EXECUTE PROCEDURE dump(); CREATE TRIGGER postgres=# postgres=# -- 更新分区表,触发器会执行 postgres=# UPDATE t SET b=b+1; NOTICE: trigger = trigger1 UPDATE 1 postgres=# postgres=# -- 更新分区表子表,触发器不执行 postgres=# UPDATE tp1 SET b=b+1; UPDATE 1 postgres=# postgres=# -- 将触发器改成行级触发器 postgres=# drop trigger trigger1 on t; DROP TRIGGER postgres=# create trigger trigger1 AFTER UPDATE ON t postgres-# FOR EACH ROW EXECUTE PROCEDURE dump(); CREATE TRIGGER postgres=# postgres=# -- 更新分区表,触发器会执行 postgres=# UPDATE t SET b=b+1; NOTICE: trigger = trigger1 UPDATE 1 postgres=# postgres=# -- 更新分区表子表,触发器也会执行 postgres=# UPDATE tp1 SET b=b+1; NOTICE: trigger = trigger1 UPDATE 1 postgres=#
六、视图触发器
在 Klustron 中,不仅可以为表创建触发器,还可以为视图创建触发器,是不是很神奇?在什么样的场合需要为视图创建触发器呢?
视图是数据库系统中一种“虚拟的表”,它不仅可以隐藏数据的复杂性(可能是多表连接的结果),简化用户的访问,而且也是限制用户访问数据的有效手段,例如可以将用户有权访问的那部分数据表示为视图的形式,并将视图的访问权限授权给用户,但保留用户对基表的访问权限。很显然,用户也希望能够对这部分数据具有修改权限,那么如何在用户无法直接访问基表的情况下更新这部分数据呢?一个有意思解决思路是,让用户更新视图这个“虚拟的表”来更新基表中对应的数据。很多数据库系统确实是允许用户来更新简单的视图的,例如:
abc=# create table t(a int, b int);
CREATE TABLE
abc=# create view v1 as select a from t where a<2;
CREATE VIEW
abc=# explain update v1 set a=a+1;
QUERY PLAN
------------------------------------------------------------------------------------------
Update on t (cost=21.02..21.02 rows=1 width=40)
Shard: 0 Remote SQL: update `abc_$$_public`.`t` set `a`=(t.a + 1) WHERE (t.a < 2)
(2 rows)
可以看到数据库会自动将对视图的更新转变为对基表的更新。但是对于复杂的视图,就没那么好运了,例如:
abc=# create view v2 as select t.a, count(1) as cnt from t left join t1 on t.a=t1.a where t.a<2 group by t.a;
CREATE VIEW
abc=# update v2 set a=a+1;
ERROR: cannot update view "v2"
DETAIL: Views containing GROUP BY are not automatically updatable.
HINT: To enable updating the view, provide an INSTEAD OF UPDATE trigger or an unconditional ON UPDATE DO INSTEAD rule.
此时系统会报错,拒绝更新包含了GROUP BY子句的视图 ,并建议我们在视图上创建INSTEAD OF UPDATE 类型的触发器。INSTEAD OF在前面的叙述中尚未提及,因为它是专门用来实现复杂视图的增删改的行级视图。从它的名称也能看出,这类触发器是用来“定义”视图的更新的。
例如上面的例子,可以在视图上定义如下触发器。可以看到,我们在触发器函数中除了将视图上的更新转换为对基表的更新之外,还对新数据进行约束检查,非常的简单灵活。
CREATE FUNCTION v2_update() RETURNS TRIGGER AS $$
BEGIN
-- 检查约束条件
IF NEW.a>=2 THEN
RAISE Exception 'a should be less than 2';
END IF;
-- 检查是否更新了cnt
IF NEW.cnt != OLD.cnt THEN
RAISE Exception 'cnt is not updatable';
END IF;
-- 转换为对基表t的更新
UPDATE t SET a=NEW.a WHERE a=OLD.a;
RETURN NEW;
END;
$$ LANGUAGE PLPGSQL;
-- 创建视图的INSTEAD OF函数
CREATE TRIGGER v2_update_trig
INSTEAD OF UPDATE ON v2
FOR EACH ROW EXECUTE PROCEDURE v2_update();
此外,虽然数据库允许对简单的视图直接进行更新,但是数据库系统只是进行了简单的替换,将其转换为对基表的更新,所以,我们仍然可以为其构建INSTEAD OF触发器,执行更加灵活的约束检查。例如:
create table usr(uid int primary key, level int);
create view v1 as select * from usr where level < 2;
insert into usr values(1,1), (2,2);
-- 修改用户级别
update v1 set level=2 where uid=1;
-- 创建触发器函数
create function update_v1() returns trigger as $$
begin
-- 拒绝更新为过高的级别
IF NEW.level >= 2 THEN
RAISE Exception 'level should be less than 2';
END IF;
-- 对基表进行更新
update usr set uid=NEW.uid and level = NEW.level where uid = OLD.uid;
return NEW;
end;
$$ language plpgsql;
-- 创建触发器
create trigger update_v1_trig
instead of update on v1
for each row execute procedure update_v1();
-- update会被拒绝
abc=# update v1 set level=2 where uid=1;
ERROR: level should be less than 2
CONTEXT: PL/pgSQL function update_v1() line 5 at RAISE
总结
下面列出的是目前 Klustron 对触发器的支持情况。
| When | Event | Row-level | Statement-level |
|---|---|---|---|
BEFORE | INSERT/UPDATE/DELETE | Tables | Tables, views |
AFTER | INSERT/UPDATE/DELETE | Tables | Tables, views |
INSTEAD OF | INSERT/UPDATE/DELETE | Views | — |
有了触发器的加持,数据库可以帮助用户实现很多复杂需求,例如对记录用户的增删改操作,实现跨越多表的约束检查或者级联更新,通过视图更新基表数据等等。但是触发器也会带来维护的复杂性,不可滥用。例如触发器函数中执行的 DML 语句可能会触发其他表/视图上的触发器,从而产生复杂的调用关系,不便于问题定位;再比如,触发器会是使得 DML 语句无法下推到存储节执行,对性能敏感的业务需要做好压测工作,权衡好触发器带来的利弊。