
Klustron(原KunlunBase) Sequence 功能用法和实现机制
Klustron(原KunlunBase) Sequence 功能用法和实现机制
Klustron Sequence的优势和特点
Klustron 的 Sequence 与 MySQL 的 autoincrement(自增列)相比,其功能更加强大和灵活。主要体现在以下几方面:
1. Klustron 的 Sequence 与表是多对多的关系,而 MySQL 的自增列与表是 1 对 1 关系
具体来说,Klustron 的每个表可以有任意数量的 sequence 列使用相同或者不同的sequence产生序列值;
并且每一个 sequence 可以被任意多个表的任意多个列使用来产生 ID 值。
而 MySQL 的每个表最多只能有一个自增列并且这个自增列只能被这个表使用(这是废话,但是为了内容对称还是要提一下)。
2. 可以在任何时候调整 sequence 的初始值,最大值,步长,范围等属性然后继续使用,然后 sequence 就会按照新的属性产生新序列值。
3. 不依赖索引,清空表后序列值不回绕。
Klustron的 Sequence 功能和用法
Klustron 集群多个计算节点直接或者间接使用同一个 sequence 都可以产生全局唯一的序列值
让我们看一个例子,首先创建一个表t1,t1的主键列serial类型标明它使用一个隐式创建的sequence来产生字段值,所以插入时候可以不为它指定字段值。
create table t1(a serial primary key, b int);

然后创建sequence seq_b,准备用seq_b来产生字段值。创建时可以可选地指定sequence的属性,不指定就使用默认值。
create sequence seq_b;
先执行这个语句插入 9 行,显式调用 seq_b 产生字段值。
insert into t1(b) values(nextval('seq_b'));
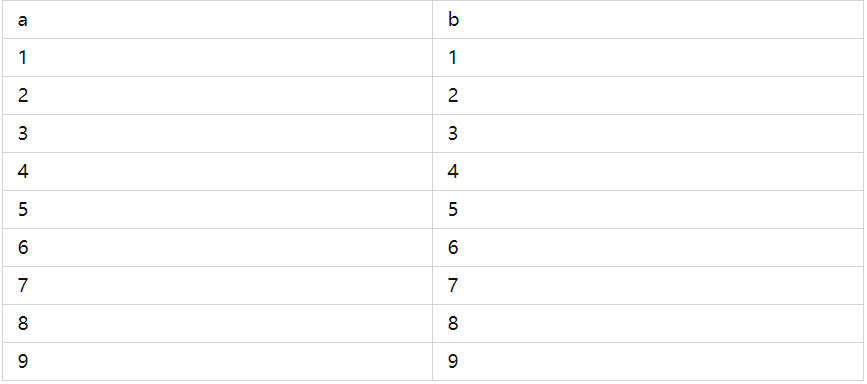
可以看到 t1 的数据如下:
select*from t1;
然后创建表 t2,它的 b 和 c 列都使用 seq_b 产生缺省字段值,并且其主键列也适用隐式 sequence 来产生字段值。
create table t2(a serial primary key, b int default nextval('seq_b'), c int default nextval('seq_b'));
由于t2的所有字段都有缺省值,所以用如下语句插入表 t2 3 行。
insert into t2 default values;
查看 t2 的数据,可以看到每行 b 和 c 字段是使用 seq_b 依次产生的字段值,并且从 seq_b 上次产生的 9 之后开始产生序列值。
select*from t2;

最后,还可以使用 select nextval('seq_b'); 这样的语句来直接产生序列值。
修改 sequence 元数据及其他
可以使用 ALTER SEQUENCE 语句来修改 sequence 的属性,也可以使用 ALTER TABLE ... ALTER COLUMN ... SET seqoptions 语句来修改列的隐式 sequence 的属性。
还可以使用上述 alter table语句restart一个sequence。并且可以使用 lastval() 函数获得 sequence 上次返回的值。

sequence 实现
Klustron 的 sequence 实现继承了 PostgreSQL 原有的 sequence 机制,并在此基础上做了如下扩展和增强:
为了使 sequence 数据具备容灾能力并且能够被任意数量的计算节点同时使用,因此 sequence 的与序列值分发有关的数值数据存储在存储节点的 kunlun_sysdb.sequences 表中,每行对应一个 sequence。
一个 sequence 的元数据具体存储在哪个存储集群中,是在创建 sequence 时由计算节点动态分配的。
sequence 的其他元数据存储在计算节点,可以使用下面的语句查看 sequence 在计算节点中的元数据
select t2.relname, t2.oid, seqstart, seqincrement, seqmax, seqmin, seqcache, seqcycle from pg_sequence t1, pg_class t2 where t1.seqrelid = t2.oid;
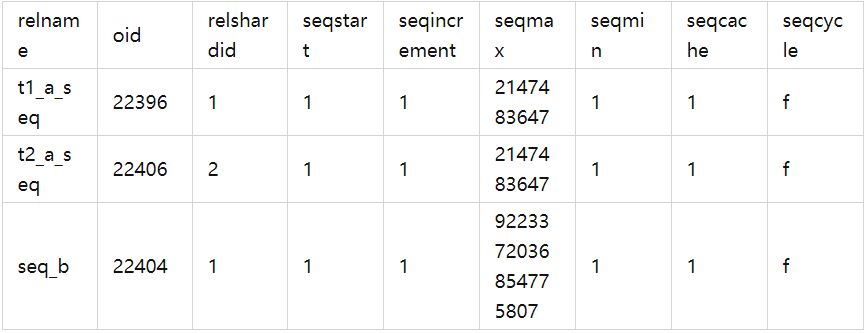
可以看到 t1 和 t2 的主键列的隐式 sequence 分别是 t1_a_seq 和 t2_a_seq ,还有显式创建的 seq_b ,这些 sequence 的数值元数据所在的存储集群shard ID 分别是 1,2,1。
同时,可以看到 sequence 的基本元数据也存储在 pg_class 元数据表中,而其特有属性存储在 pg_sequence 表中。
分别连接到shard_id 编号为 1 和 2 的 shard 查看这 3 个 sequence 在这两个存储集群的 kunlun_sysdb.sequence 表中的数值元数据,可以看到以下信息:


当首次使用一个 sequence 或者其预约的数值范围用尽时,一个计算节点 CN 就会通过其 cluster_log_applier 进程到这个 sequence 所在的存储集群中去 reserve (curval, cur_val + max(10, seqcache)) 这个范围的字段值,然后 CN 使用这个 reserve 的范围来为这个sequence 分发序列值,直到用尽后再次reserve。
这样,即使有多个计算节点使用同一个 sequence 来分发序列值,仍然可以保持高性能并且保持所有计算节点分发的序列值都唯一。