
Klustron Table Group 应用范例
Klustron Table Group 应用范例
注意:
如无特别说明,文中的版本号可以使用任何已发布版本的版本号代替。所有已发布版本详见:Release_notes
概述
表组(TABLE GROUP)是Klustron作为分布式数据库的一个特色功能,表组是表的属性,影响表分配在Shard上的具体分布。文中介绍表组的用途,语法和具体的案例,体现出使用表组的优点,最后通过XPanel演示表组整体搬迁到另一个Shard的具体过程。
**01 **表组介绍
现实场景中有些相关联的表会经常join或者常常在同一个事务中进行更新。因此Klustron支持用户把这些关联表放在同一个Shard,以便得到更好的查询性能和事务处理性能。
当这些关联表进行Join时,可以将表的Join下推到存储Shard中执行,从而获取到更好的查询性能;当同一个事务中更新关联表时,可以避免两阶段提交,从而获得更好的事务处理性能。
表组中的一个表不可以单独搬迁到另一个Shard,如果要搬迁必须做整个表组中所有表的整体搬迁。
02 测试环境
由于测试是在虚拟机上进行的,文章中的执行时间只能用作在相同环境下不同场景之间的对比参考。测试集群相关虚拟机的配置信息如下:
| 节点类别 | 名称 | IP | CPU | 内存 |
|---|---|---|---|---|
| 计算节点 | 192.168.40.152 | 2C Intel i9 2.4 GHz | 6G | |
| 存储主节点 | shard_1 | 192.168.40.151 | 2C Intel i9 2.4 GHz | 6G |
| 存储主节点 | shard_2 | 192.168.40.153 | 2C Intel i9 2.4 GHz | 6G |
03 表组语法
创建表组的语法如下:
CREATE TABLEGROUP tablegroup_name
[ OWNER { new_owner | CURRENT_USER | SESSION_USER } ]
[ WITH (SHARD = shardid) ]
创建表的时候,可以指定表组名。
CREATE TABLE table_name … WITH (TABLEGROUP tablegroup_name);
也可以在创建表之后,通过下面的语句指定表组。
ALTER TABLE table_name SET (TABLEGROUP tablegroup_name);
04 具体案例
首先通过psql客户端登录计算节点192.168.40.152,创建用户和数据,并查看集群中shard的信息。
psql -h 192.168.40.152 -p 47001 postgres
create user kunlun_test with password 'kunlun';
create database testdb owner kunlun_test;
grant all privileges on database testdb to kunlun_test;
alter user kunlun_test superuser;

以用户kunlun_test登录testdb,创建测试表sales_order ,product和customer。
其中指定customer和product存放于shard_2, sales_order存放于shard_1
psql -h 192.168.40.152 -p 47001 -U kunlun_test testdb
CREATE TABLE customer
(
customer_number INT NOT NULL,
customer_name VARCHAR(128) NOT NULL,
customer_street_address VARCHAR(256) NOT NULL,
customer_zip_code INT NOT NULL,
customer_city VARCHAR(32) NOT NULL,
customer_state VARCHAR(32) NOT NULL,
PRIMARY KEY (customer_number)
)
with(shard=1);
CREATE TABLE product
(
product_code INT NOT NULL,
product_name VARCHAR(128) NOT NULL,
product_category VARCHAR(256) NOT NULL,
PRIMARY KEY (product_code)
)
with (shard=1);
CREATE TABLE sales_order
(
order_number INT NOT NULL,
customer_number INT NOT NULL,
product_code INT NOT NULL,
order_date DATETIME NOT NULL,
entry_date DATETIME NOT NULL,
order_amount DECIMAL(18,2) NOT NULL,
PRIMARY KEY (order_number)
) with (shard=2);
插入测试数据
INSERT INTO customer
( customer_number
, customer_name
, customer_street_address
, customer_zip_code
, customer_city
, customer_state
)
VALUES
(1,'Big Customers', '7500 Louise Dr.', '17050','Mechanicsburg', 'PA')
, ( 2,'Small Stores', '2500 Woodland St.', '17055','Pittsburgh', 'PA')
, (3,'Medium Retailers', '1111 Ritter Rd.', '17055', 'Pittsburgh', 'PA')
, (4,'Good Companies', '9500 Scott St.', '17050','Mechanicsburg', 'PA')
, (5,'Wonderful Shops', '3333 Rossmoyne Rd.', '17050','Mechanicsburg', 'PA')
, (6,'Loyal Clients', '7070 Ritter Rd.', '17055', 'Pittsburgh', 'PA')
;
通过下面两个存储过程去给product和sales_order加载测试数据。其中给product加载1000行,sales_order加载100000行。
create or replace procedure generate_order_data()
AS $$
DECLARE
v_customer_number integer;
v_product_code integer;
v_order_date date;
v_amount integer;
start_date date := to_date('2022-01-01','yyyy-mm-dd');
i integer :=1;
BEGIN
while i<=100000 loop
v_customer_number := FLOOR(1+RANDOM()*6);
v_product_code := FLOOR(1+RANDOM()*1000);
v_order_date := to_date('2022-01-01','yyyy-mm-dd') + CAST(FLOOR(RANDOM()*365) AS INT);
v_amount := FLOOR(1000+RANDOM()*9000);
INSERT INTO sales_order VALUES (i,v_customer_number,v_product_code,v_order_date,v_order_date,v_amount);
commit;
i := i+1;
end loop;
END; $$
LANGUAGE plpgsql;
create or replace procedure generate_product_data()
AS $$
DECLARE
v_product_name varchar(128);
i integer :=1;
BEGIN
while i<=1000 loop
case mod(i,3)
when 0 then
v_product_name := 'Hard Disk '||i;
INSERT INTO product VALUES (i,v_product_name,'Storage');
when 1 then
v_product_name := 'LCD '||i;
INSERT INTO product VALUES (i,v_product_name,'Monitor');
when 2 then
v_product_name := 'Paper'||i;
INSERT INTO product VALUES (i,v_product_name,'Paper');
end case;
commit;
i := i+1;
end loop;
END; $$
LANGUAGE plpgsql;
完成数据加载并给sales_order创建索引,最后收集所有表的统计信息。
set statement_timeout=0;
call generate_product_data();
call generate_order_data();
create index sales_order_idx1 on sales_order(order_date);
analyze product;
analyze sales_order;
analyze customer;
\timing on
现在业务想查看Big Customers在2022年上半年于每个产品类别所花费的金额。
具体的SQL如下:
select product_category,sum(order_amount ) from sales_order t1, product t2 ,customer t3 where
t1.product_code = t2.product_code and
t1.customer_number = t3.customer_number and
t1.order_date between to_date('2022-01-01','yyyy-mm-dd') and to_date('2022-06-30','yyyy-mm-dd') and customer_name='Big Customers' group by product_category;
查看具体的执行计划:
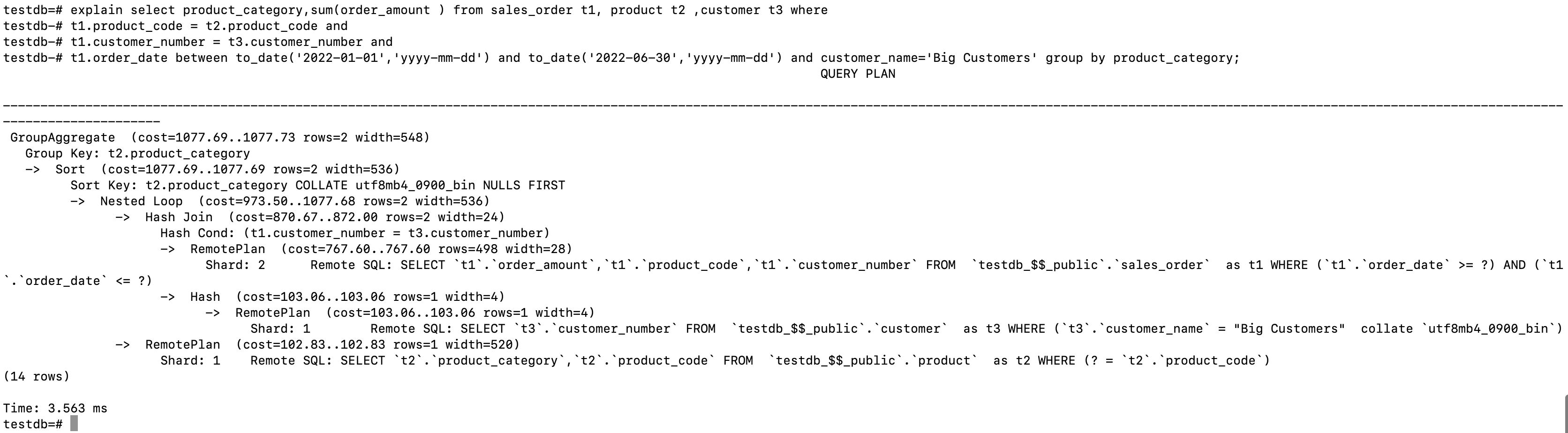
发现分别从Shard 1和2上取过滤后的数据,取到计算节点之后再分别做Join 。
相应的执行时间为168 ms

现在先创建一个表组sales_sum,其位于Shard 2。并将sales_order表置于sales_sum中。
CREATE TABLEGROUP sales_sum WITH (SHARD=2);
alter table sales_order set (tablegroup=sales_sum);
重新创建product和customer表,在创建的时候就指定表组sales_tg
drop table customer;
alter table product rename to product_old;
CREATE TABLE customer
(
customer_number INT NOT NULL,
customer_name VARCHAR(128) NOT NULL,
customer_street_address VARCHAR(256) NOT NULL,
customer_zip_code INT NOT NULL,
customer_city VARCHAR(32) NOT NULL,
customer_state VARCHAR(32) NOT NULL,
PRIMARY KEY (customer_number)
)
with (tablegroup=sales_sum);
CREATE TABLE product
(
product_code INT NOT NULL,
product_name VARCHAR(128) NOT NULL,
product_category VARCHAR(256) NOT NULL,
PRIMARY KEY (product_code)
)
with (tablegroup=sales_sum);
重新为customer和product装载数据,并收集统计信息。
INSERT INTO customer
( customer_number
, customer_name
, customer_street_address
, customer_zip_code
, customer_city
, customer_state
)
VALUES
(1,'Big Customers', '7500 Louise Dr.', '17050','Mechanicsburg', 'PA')
, ( 2,'Small Stores', '2500 Woodland St.', '17055','Pittsburgh', 'PA')
, (3,'Medium Retailers', '1111 Ritter Rd.', '17055', 'Pittsburgh', 'PA')
, (4,'Good Companies', '9500 Scott St.', '17050','Mechanicsburg', 'PA')
, (5,'Wonderful Shops', '3333 Rossmoyne Rd.', '17050','Mechanicsburg', 'PA')
, (6,'Loyal Clients', '7070 Ritter Rd.', '17055', 'Pittsburgh', 'PA');
insert into product select * from product_old;
analyze product;
analyze customer;
再次查看之前SQL的执行计划,发现全部是在Shard 2上完成的。

执行时间也变快了,提升49.4ms。

05 表组迁移
可以通过下面的方式查看表位于的shard和分组相关的信息。

尝试在XPanel上,将customer表单独迁移到id为1的shard上。
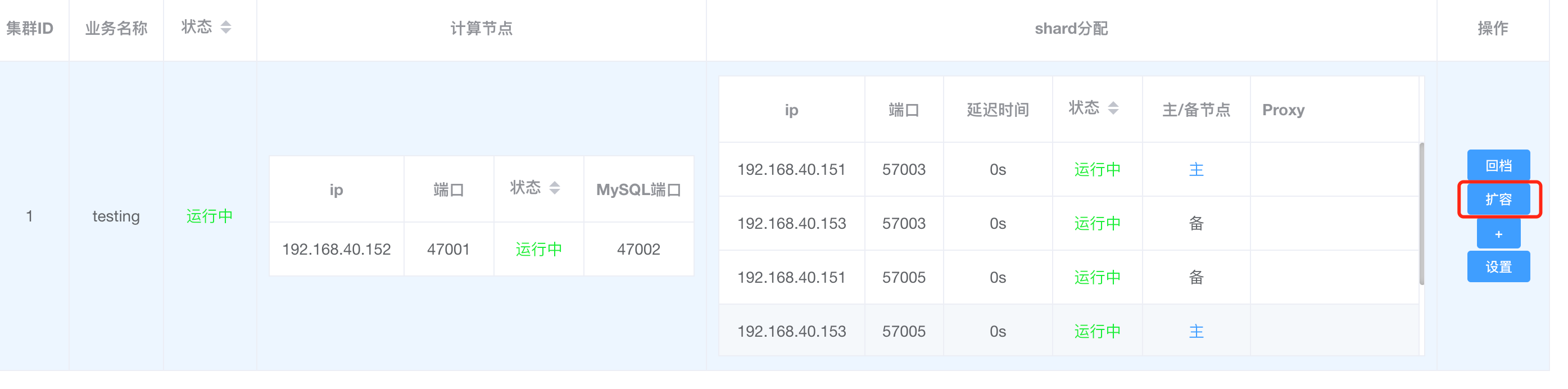
选择数据库为testdb, 然后点击确定。
首先选择customer表,“是否保留原表”勾选“否”,目标 shard选择”shard_2”, 最后点击确定。
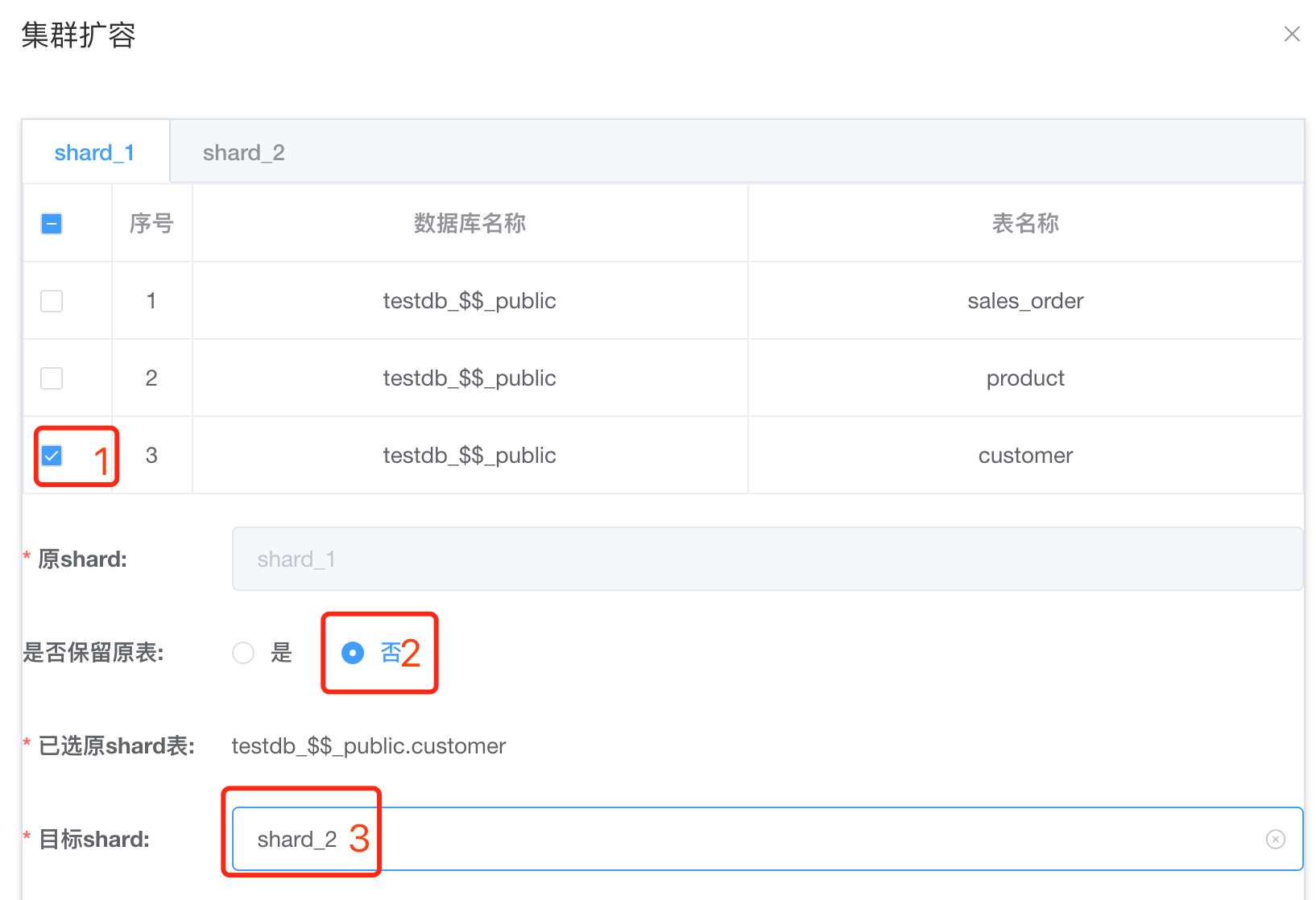
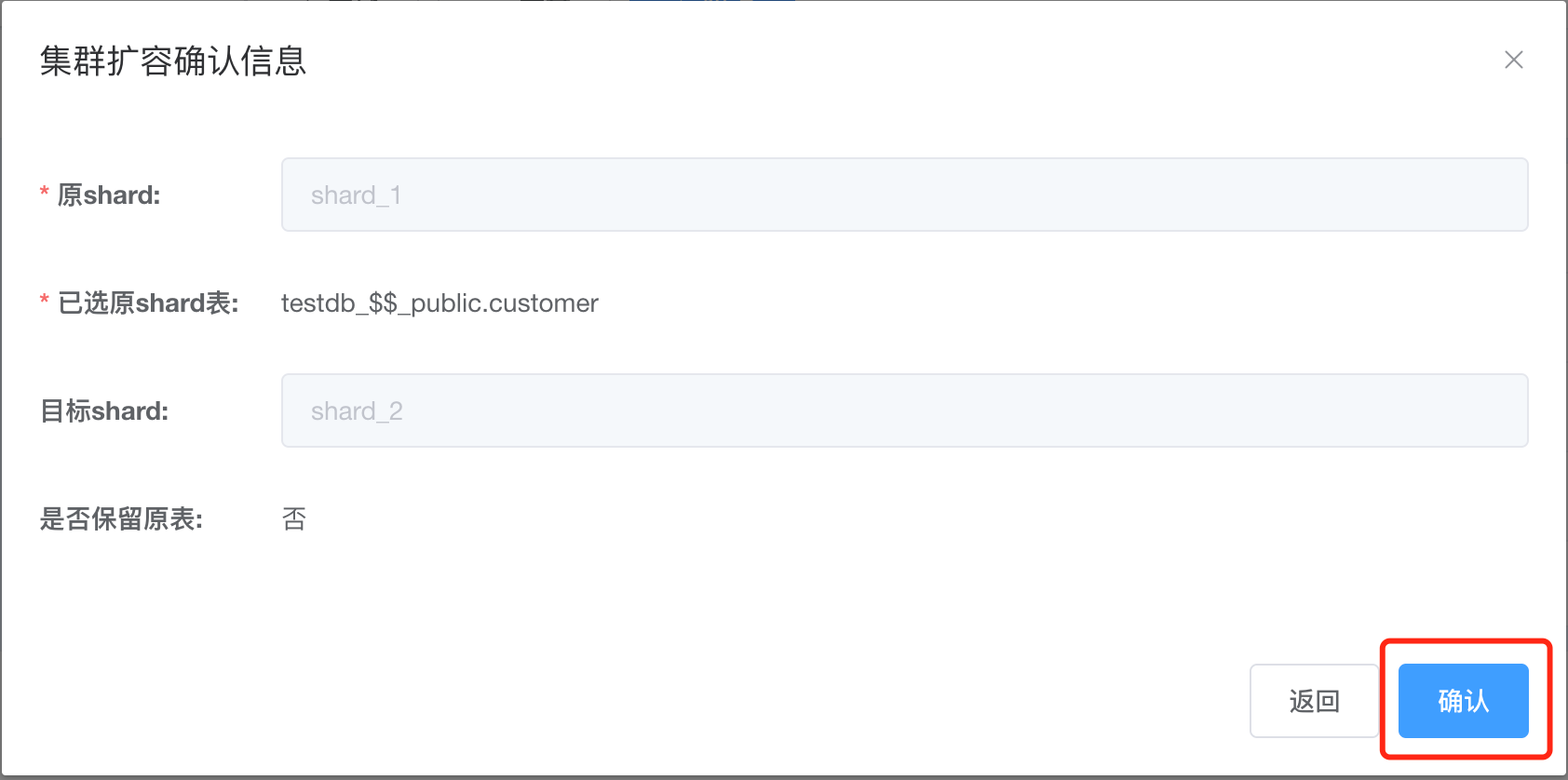
单独移动customer表会报错,不能单独移动在表组sales_sum里面的部分表

再次尝试移动表组sales_sum 中的所有表;customer, product和sales_order
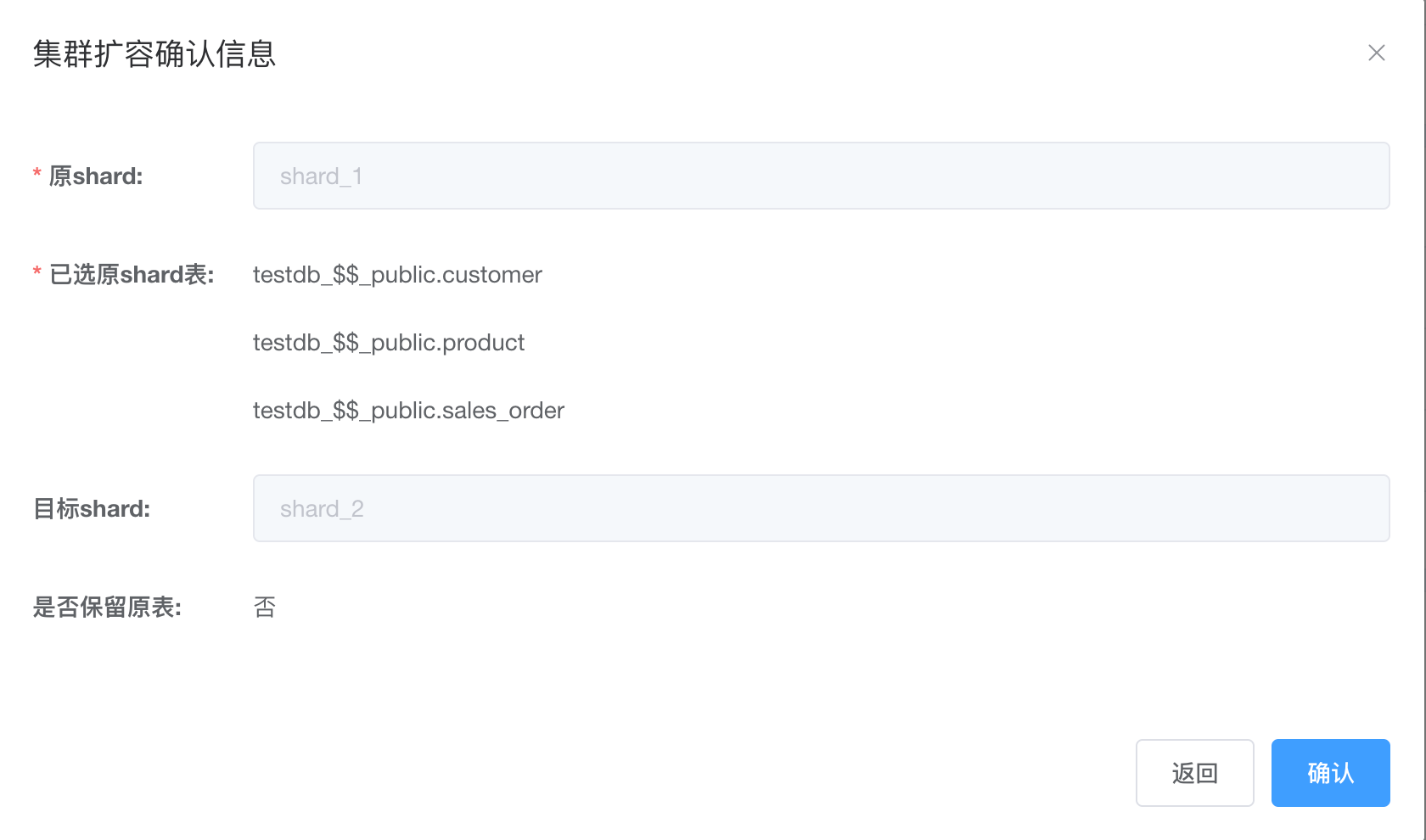
移动整个表组中的所有表任务成功。

验证移动后所有表都位于shard_2(shard id=1)
