
Klustron Mirroy表功能应用范例
Klustron Mirroy表功能应用范例
注意:
如无特别说明,文中的版本号可以使用任何已发布版本的版本号代替。所有已发布版本详见:Release_notes
概述
介绍 Mirror 表的功能和具体使用场景,并演示如何创建 Mirror 表,以及如何使用 Mirror 表加速一个分析型的查询场景。所有的操作都通过命令行的方式进行展现。
01 Mirror表的作用
在 OLAP 的现实场景中有一些数据表具有如下特征:
- 数据量比较小,例如部门信息表、业务代码表等等。
- 数据变化不频繁。
- 这表经常会和大表(比如订单表)做 join。
对于具有上面特征的表,在 Klustron 中用户可以把他们定义为 Mirror 表(镜像表),以便实现更好的查询性能。Klustron 会确保一个集群的 Mirror 表在每一个存储节点中都有一份相同的数据。
在执行对 Mirror 表的插入、更新、删除操作时,Klustron 的计算节点会自动对 Mirror 表在每一个存储节点的数据做相应的插入、更新、删除操作,并且这些操作运行在同一个全局事务中,因而具有 ACID 特性。 也正因此,如果一个表更新非常频繁,那么在一个分布式事务中更新所有shard上这个mirror表的副本的话,就会严重影响性能,因此可能就不适合作为mirror表。这是一个比较宽泛的经验规则,用户可以根据这些考虑来自行决定。
当新增一个 Storage Shard,Klustron 会自动把系统中所有的 Mirror 表都会复制到新 Shard 上,在这个复制的过程中,这些 Mirror 表仍然可以被读写,不过新增 Mirror 表的操作会阻塞直到复制全部完成。
Mirror 表与分片存储的大表的 join 就总是可以下推到存储节点执行,同时这确保了这两个表的 join 是由多个存储节点并行执行的,从而达到更好的查询执行性能。
在 OLAP 应用中,维度表通常符合 Mirror 表的特征,适合定义为 Mirror 表。这样在一个 OLAP 的星形连接查询中,多个 Mirror 表与一个事实表的的 join,实际上也是并行地运行在多个存储节点上的,因为这个事实表会分片存储到多个存储节点上。
另外,两个或者多个 Mirror 表的 join,也总是可以下推到某一个存储节点上去执行,也可以在一定程度上提升查询性能。
02 测试环境
由于测试是在虚拟机上进行的,文章中的执行时间只能用作在相同环境下不同场景之间的对比参考。测试集群相关虚拟机的配置信息如下:

03 具体案例
首先通过 pgsql 客户端登录计算节点 192.168.40.152,创建用户和数据库
psql -h 192.168.40.152 -p 47001 postgres
create user kunlun_test with password 'kunlun';
create database testdb owner kunlun_test;
grant all privileges on database testdb to kunlun_test;
/q
以用户 kunlun_test 登录 testdb,创建测试表 sales_order 和 product:
psql -h 192.168.40.152 -p 47001 -U kunlun_test testdb
create table sales_order
(
order_number INT NOT NULL AUTO_INCREMENT,
customer_number INT NOT NULL,
product_code INT NOT NULL,
order_date DATETIME NOT NULL,
entry_date DATETIME NOT NULL,
order_amount DECIMAL(18,2) NOT NULL
) partition by range(order_date);
create table sales_order_p0 partition of sales_order
for values from ('2021-01-01') to ('2021-04-01');
create table sales_order_p1 partition of sales_order
for values from ('2021-04-01') to ('2021-07-01');
create table sales_order_p2 partition of sales_order
for values from ('2021-07-01') to ('2021-10-01');
create table sales_order_p3 partition of sales_order
for values from ('2021-10-01') to ('2022-01-01');
create table product
(
product_code INT NOT NULL AUTO_INCREMENT,
product_name VARCHAR(128) NOT NULL,
product_category VARCHAR(256) NOT NULL,
PRIMARY KEY (product_code)
) ;
分别创建存储过程,然后使用存储过程往 sales_order 表中装载 10000 行记录,往 product 表中装载 1000 行记录。
create or replace procedure generate_order_data()
AS $$
DECLARE
v_customer_number integer;
v_product_code integer;
v_order_date date;
v_amount integer;
start_date date := to_date('2021-01-01','yyyy-mm-dd');
i integer :=1;
BEGIN
while i<=10000 loop
v_customer_number := FLOOR(1+RANDOM()*6);
v_product_code := FLOOR(1+RANDOM()*500);
v_order_date := to_date('2021-01-01','yyyy-mm-dd') + CAST(FLOOR(RANDOM()*365) AS INT);
v_amount := FLOOR(1000+RANDOM()*9000);
insert into sales_order VALUES (i,v_customer_number,v_product_code,v_order_date,v_order_date,v_amount);
commit;
i := i+1;
end loop;
END; $$
LANGUAGE plpgsql;
create or replace procedure generate_product_data()
AS $$
DECLARE
v_product_name varchar(128);
i integer :=1;
BEGIN
while i<=1000 loop
case mod(i,3)
when 0 then
v_product_name := 'Hard Disk '||i;
INSERT INTO product VALUES (i,v_product_name,'Storage');
when 1 then
v_product_name := 'LCD '||i;
INSERT INTO product VALUES (i,v_product_name,'Monitor');
when 2 then
v_product_name := 'Paper'||i;
INSERT INTO product VALUES (i,v_product_name,'Paper');
end case;
commit;
i := i+1;
end loop;
END; $$
LANGUAGE plpgsql;
set statement_timeout 0;
call generate_order_data();
call generate_product_data();
创建索引,并收集统计信息
create index sales_order_idx1 on sales_order(product_code,order_amount);
create index product_idx1 on product(product_name,product_code);
analyze sales_order;
analyze product;
查看表 product 和 sales_order 在存储节点的分布情况。
select * from pg_shard;
/d+ product


可以发现 product 存放于 shard 的 id 为6,即 shard_1 存储节点。而 sales_order 的分区则分布于 shard_1 和 shard_2 两个存储节点。
select relname table_name ,reltuples num_rows, name shard_name from pg_class t1,pg_shard t2 where t1.relshardid
= t2.id and t1.reltype<>0 and t1.relname like 'sales%';

查看下面获取所有硬盘总销售数据 SQL 的执行计划
explain select sum(order_amount) from sales_order t1, product t2 where t1.product_code = t2.product_code and
product_name like 'Hard Disk%' ;
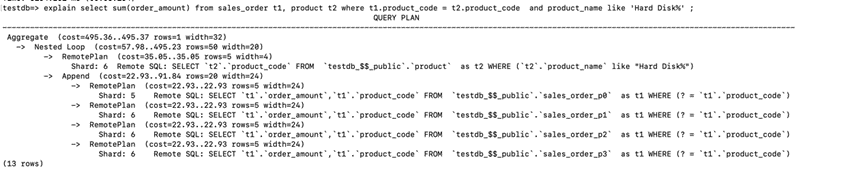
首先在计算节点查询优化器选择 Nested Loop 方式进行 join, 选择 product 表为驱动表,计算节点发送下面的 Remote SQL 到驱动表所在的shard_1上获取满足条件的记录到计算节点。
SELECT `t2`.`product_code` FROM `testdb_$$_public`.`product` as t2 WHERE (`t2`.`product_name` like
"Hard Disk%")
然后将获取到驱动表满足条件记录的 product_code 组成下面的 Remote SQL
SELECT `t1`.`order_amount`,`t1`.`product_code` FROM `testdb_$$_public`.`sales_order_p0` as t1 WHERE (?= `t1`.`product_code`)
分别发送到 sales_order 4 个分区所在的 shard_1 和 shard_2 执行,最后将每个分区的返回的 order_mount 进行汇总。
SQL的执行时间为4.59s
testdb=>/timing on
testdb=> select sum(order_amount) from sales_order t1, product t2 where t1.product_code = t2.product_code and product_name like 'Hard Disk%' ;
sum
-------------
17975514.00
(1 row)
Time: 4590.807 ms (00:04.591)
将 product 设置为 Mirror 表,装载数据库重新进行测试。
其中 with (shard=all) 的子句说明将表创建为 Mirror 表,顾名思义其会存放在所有的存储节点上。
drop table product;
create table product
(
product_code INT NOT NULL AUTO_INCREMENT,
product_name VARCHAR(128) NOT NULL,
product_category VARCHAR(256) NOT NULL,
PRIMARY KEY (product_code)
) with (shard=all);
call generate_product_data();
create index product_idx1 on product(product_name,product_code);
analyze product;
Product 表对应的 shard id 是一个很大的值,说明其是 Mirror 表

重新查看测试 SQL 的执行计划
explain select sum(order_amount) from sales_order t1, product t2 where t1.product_code = t2.product_code and
product_name like 'Hard Disk%' ;
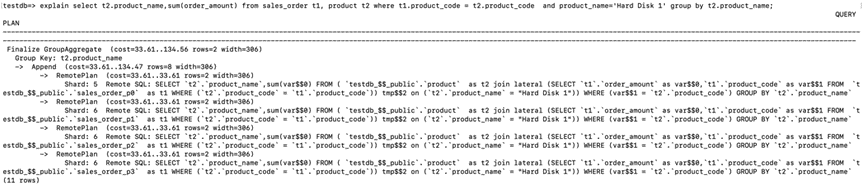
可以看到下面的 Remote SQL 被推送到 sales_order 所有分区的存储节点执行。
SELECT sum(var$$0) FROM ( `testdb_$$_public`.`product` as t2 join lateral (SELECT `t1`.`order_amount` as
var$$0,`t1`.`product_code` as var$$1 FROM `testdb_$$_public`.`sales_order_p0` as t1 WHERE (`t2`.`product_code` = `t1`.`product_code`)) tmp$$2 on (`t2`.`product_name` like "Hard Disk%")) WHERE (var$$1 = `t2`.`product_code`)
最后的结果才在计算节点汇总(Finalize Aggregate)。相应的 SQL 执行也变快了,从之前的 4.59 秒降低到 1.46 秒。说明了 Mirror 表合理的使用,能够提升某些分析型场景的性能。
testdb=>/timing on
testdb=> select sum(order_amount) from sales_order t1, product t2 where t1.product_code = t2.product_code and product_name like 'Hard Disk%' ;
sum
-------------
17975514.00
(1 row)
Time: 1459.327 ms (00:01.459)