
KunlunBase 单 shard 功能介绍
KunlunBase 单 shard 功能介绍
1 Klustron 单 shard 集群的应用场景
对于中小规模的应用, 可以使用 Klustron 单 shard 架构,降低系统软件和硬件的成本,相对与 MySQL 主从的架构,Klustron 单 shard 架构不但可以提高系统的可靠性,而且还可以利用 Klustron 强大的计算分析能力, 在一个系统内同时满足 OLTP & OLAP 负载的需求,关于使用 Klustron 单 shard 集群的优势,特别是kunlun_proxysql的重要作用,详见这篇文章。
2 Klustron 单 shard 架构
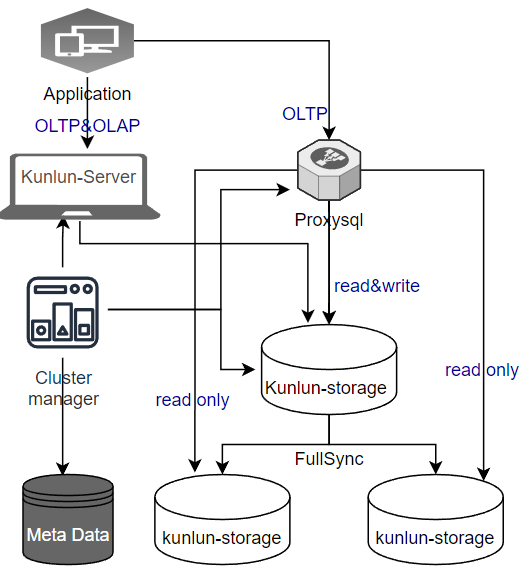
3 配置使用
3.1 使用 cluster_mgr api 安装单 shard 集群
curl -d '
{
"version":"1.0",
"job_id":"",
"job_type":"create_cluster",
"timestamp":"1435749309",
"user_name":"kunlun_test",
"paras":{
"nick_name":"my_nick_name",
"ha_mode":"mgr",
"shards":"1",
"nodes":"3",
"comps":"1",
"max_storage_size":"20",
"max_connections":"6",
"cpu_cores":"8",
"innodb_size":"1024",
"dbcfg":"1",
"fullsync_level":"1",
"install_proxysql":"1",
"computer_user":"abc",
"computer_password":"abc"
}
}
' -X POST http://127.0.0.1:35001/HttpService/Emit
传入 install_proxysql 参数为 1,则 cluster_mgr 自动按照单 shard 模式安装集群。
3.2 使用 Xpanel 界面安装单 shard 集群
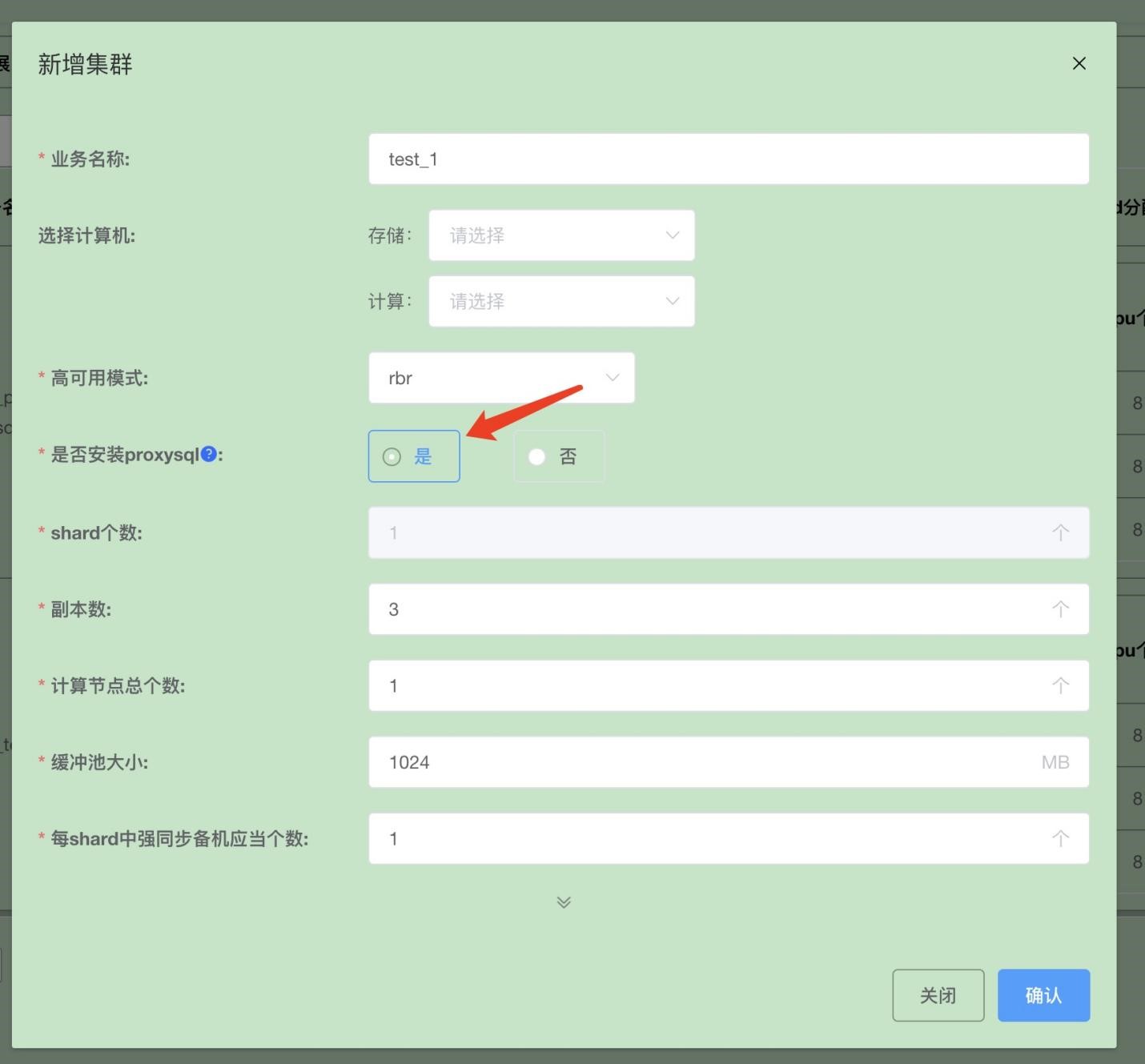
选择安装 kunlun-proxysql 即可。
注意事项
- 选择安装 kunlun-proxysql,则该集群为单 shard 模式,在 Klustron-1.1 版本中不支持增加/删除 shard 操作。未来版本中可以按需增加更多存储 shard,前提条件是:
- 用户在使用单shard模式期间,一直使用计算节点(Klustron-server)来执行DDL语句;或者从1.3.2版本开始,如果通过kunlun_proxy来执行了DDL,那么需要手动通过计算节点再次执行DDL语句,按照下文第8条的方法。
- 用户自行确保在集群有多于一个 shard 后就不再使用 kunlun-proxysql,如果使用的话,会有部分数据无法访问到。
安装时候传入 computer_user/computer_password 为登录 kunlun-proxysql 的账号/密码
安装成功后,登录元数据集群 kunlun_metadata_db/proxysql_nodes 查看当前集群 kunlun-proxysql 的机器和端口
通过 Klustron 的计算节点(Klustron-server)执行 DDL 语句,不要通过 kunlun-proxysql 执行 DDL 语句。这样,计算节点才知道用户定义的表,从而后续对这些表执行 OLTP 和 OLAP SQL 语句。如果 DDL 是 MySQL 语法,Klustron-1.2版本开始可以直接用MySQL协议连接计算节点,来执行MySQL的DDL语法;在Klustron-1.2之前,需要使用 [老办法处理]](ddl2_kunlun.md);
通过 kunlun-proxysql 访问数据表的时候,这些表所在的 database 的名称,形如 dbname_$$_schema_name 。此时 SQL 语句要使用这样的database名称。这是因为 Klustron-server 在 Klustron-storage 节点中创建的 database 的名字都是这样的格式,其中 dbname 是 Klustron-server 中的database 名称; schema_name 是其中的 schema 的名称。
在安装集群时可以合并元数据集群shard和storage shard,使用同一个kunlun-storage shard,从而进一步降低资源开销。也就是在单shard集群配置文件中使用同一个shard作为元数据shard和storage shard。注意在此种配置情况下,禁止启用Global MVCC,并且单shard部署时,也完全不需要Global MVCC功能。
用户可以把一个Klustron 集群挂在一个现有的MySQL主节点下面作为备机运行,持续复制其数据变更,并且使用Klustron的计算节点执行OLAP数据分析SQL语句。这会比使用MySQL备机节点做分析有更好的性能。这个Klustron 集群可以是单shard集群,也可以是常规的Klustron分布式集群。具体做法详见这篇文章
从1.3.2版本开始,用户可以直接连接kunlun-proxy执行DDL语句,并且在计算节点中做一个简单设置后(设置
skip_storage_ddl=true),把DDL语句再次在计算节点中执行,以便计算节点获得相关元数据信息,这样就可以通过计算节点读写这个表了。
在skip_storage_ddl=true时,计算节点执行DDL不会像存储节点发送本应发送的DDL语句,因为存储节点中这个数据库对象(比如 表)已经存在了。
由于直接通过kunlun_proxysql创建database以及其中的数据表,用户通常会直接创建形如mydb这样的datatabse,没有考虑要通过计算节点访问存储节点而创建类似 pgdb_$$_pgschema 的database。 因此为了能够在计算节点中访问这个表,Klustron支持用户创建一个映射关系来达到此目的。为此用户需要建立一个计算节点的database, schema到存储节点的database 的映射, 方法是向计算节点的元数据表 pg_database_name_map中插入一行。以本节所述为例,插入的行应该是('pgdb', 'pgschema', 'mydb'),这样就可以把计算节点的pgdb.pgschema schema映射到存储节点的mydb数据库。然后就可以连接计算节点的pgdb 数据库,执行USE pgschema 来切换到pgschema,然后读写存储节点的mydb中的表。
例如,我们预先在存储节点的mydb这个database中创建了表t1,然后连接计算节点的pgdb 这个database,然后在连接中执行USE pgschema; 来切换当前路径到pgschema 然后向计算节点的pg_database_name_map表插入一行('pgdb', 'pgschema', 'mydb')。然后执行set skip_storage_ddl=true,并且在同一个会话中执行t1的CREATE TABLE语句。然后,就可以在计算节点的任意连接中读写t1这个表了。此后如果要ALTER TABLE t1,最好通过计算节点操作(并且在会话中务必设置skip_storage_ddl=false);如果是通过kunlun_proxysql来执行ALTER TABLE t1,那么也需要再次在设置skip_storage_ddl=true之后在计算节点中执行相同的ALTER TABLE动作,,以便保持计算节点与存储节点中的元数据一致。