Klustron(原KunlunBase) Online DDL 和 表重分布(repartitioning) 功能和用法
Klustron(原KunlunBase) Online DDL 和 表重分布(repartitioning) 功能和用法
1 需求背景:
用户在 Klustron 集群中创建表后在使用过程中,随着业务需求和表的数据量变化,原先创建的表可能不再适合,例如由于分区不合理导致查询和插入操作变慢,或者表数据变小不要原先那么多分区,需要增删列,修改列的数据类型,修改主键,增加索引等情况,用户希望能够在不影响业务运行情况下在线完成这些DDL 或者 重新修改该表分区。针对这种场景 Klustron 团队开发了online DDL和 在线更改表分区功能,本文简称其为表重分布(repartition)。
Repartition功能不仅支持单表到分区表,分区表到单表,修改表分区规则以及修改表分区参数。
也支持把所有的DDL操作在线化(不需要锁表,不影响业务系统运行)。用户对于无法瞬间完成的 DDL 语句,可以使用这个功能实现 online DDL --- 按照新的表定义先把表创建好,然后做一个 repartition 操作,就可以在不影响原表使用的情况下,把源表的所有数据灌入并且瞬间切换,从而避免 DDL 操作影响应用系统正常运行。所以 repartition 功能,也可以说是 Klustron 的 Online DDL 功能,适用于所有 DDL 操作。特别地,对于 MySQL 来说,这两类 alter table alter column 操作需要重建表(algorithm=copy)是反直觉的。首先是 改列的数据类型 --- 即使改宽了(例如 int 改为bigint)也如此;其次是 改列空值约束为 NULL 或者 NOT NULL。执行这两类操作都要 copy 全表数据,需要重新建表。用户可以使用Klustron repartition把这些操作在线完成。
2 实现原理:
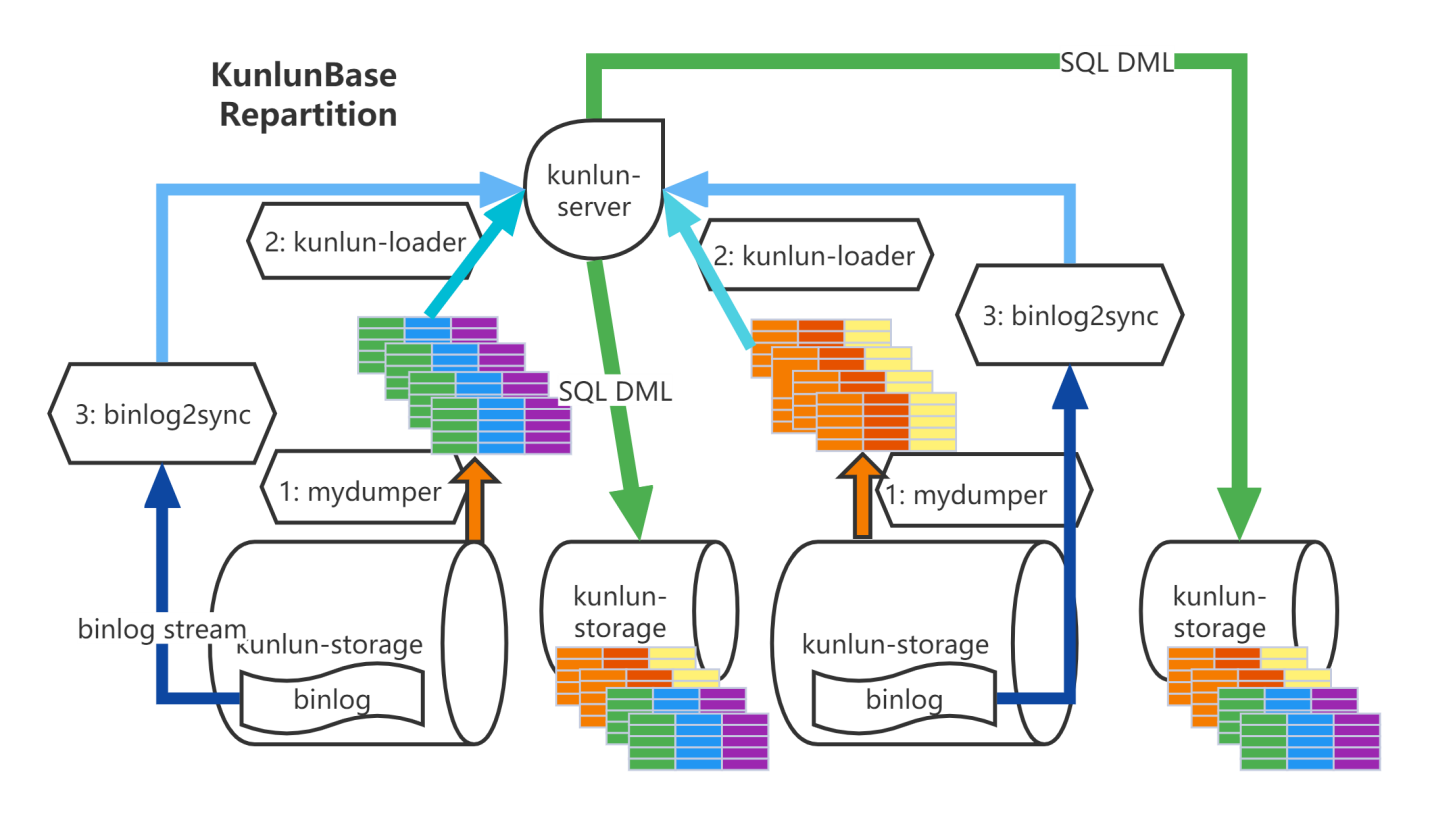
前提:用户已经用新的分区规则或者按照新的表设计创建好了目标表,例如 create table t1(like t0, including all) ,并且源和目标表表结构一致。
任务执行流程:表重分布是由cluster_mgr和node_mgr模块协作完成的,cluster_mgr接受业务请求后,解析请求内容,检查参数并将需要操作node_mgr节点规划好。发送命令给node_mgr模块来进行具体操作。
方法: 把源表数据导出并灌入目标表,然后将此期间对源表的更新导入目标表
导出表全量数据
node_mgr 调用 mydumper 将源表数据 dump 出来并传输数据文件到计算节点所在服务器
加载表全量数据
node_mgr调用kunlun_loader工具把源表dump全量数据灌入目标表中。kunlun_loader是Klustron在myloader基础上增加对库表名映射功能,调用kunlun_loader导入数据时,自动完成根据配置的库表名映射规则进行库表名转换。另外kunlun_loader使用Klustron的MySQL端口将数据写入计算节点。为了提高处理速度,node_mgr采用多表并行dump,并行load方式。
binlog catch-up --- binlog2sync
node_mgr根据dump时各个shard上binlog起始位置记录调用binlog2sync工具,binlog2sync 工具从该位置点开始dump binlog事件,并根据需要同步源库表过滤掉不需要binlog事件。针对源表的更新事件自动转换为SQL语句并做库表名映射。将转换好SQL语句通过Klustron的mysql端口送计算节点执行。
即将完成时通过计算节点 rename 源表和目标表
binlog2sync工具通过查询源shard中binlog写入位置和自身已经dump binlog位置判断是否进行表名切换。尽量减小切换表名后dump binlog时间。切换表名后业务无法再写入,该工具快速将剩余的binlog同步完,确保源中新增数据完全导入目标表中。然后再将目标表rename成源表名,业务恢复正常使用。在该阶段会对业务有毫秒级影响。
3 新表与源表必须有如下的相同点并且可以有如下的不同点
由于 Klustron online DDL (repartition) 功能的 mydumper 和 binlog2sync 产生的 insert 语句都是带有源表的所有列名的,所以关于源表和新表的表定义的相同和不同,我们不难得到以下推论。
为了方便描述,我们把源表和新表具有相同名称的两个列分别记为 colX 和 colY。新表必须在如下几个方面与源表保持一致和可以不同。
3.1 列集合
源表所有列名在新表必须都出现,但是这些列的顺序可以不同。新表可以增加更多的列,但是这些列必须具有default值或者允许NULL值。所以一个online DDL 可以同时做多个操作 ---- 新增列(不仅仅追加到最后面还可以加到该表的任意位置)和调整列顺序以及调整列的约束和default值。
源表和新表同名的列可以具有不同的 default 值或者 NULL 约束或者 check约束,不过如果colX 有 NULL 值而 colY 是 NOT NULL,或者 colX 的数据无法满足colY 的check 约束,那么数据导入将失败并导致repartition操作失败。
3.2 列数据类型
源表和新表同名的列的数据类型必须要么完全相同,要么属于同一个大类,并且colY 的数据类型可以更宽,但是不可以更窄。
例如,二者都是整形,colX 如果是 int, 那么 colY 可以是 bigint,但是不可以是 smallint、tinyint;如果 colX 是 float,那么 colY 可以是 float 或者 double;如果 colX 是 varchar(10),那么 colY 可以是 varchar(11),char[11], text,但是不可以是 varchar(9),char(9), int, float 等。
对于字符串类型来说,还有一点比较特殊,就是字符集--- colX 数据类型如果是 varchar/char(n)/[long/medium]text 则其字符集与 colY 最好完全相同(collation 如有必要可以不同,需要符合应用逻辑的预期);colX 和 colY 的字符集如果确实需要不同的话(例如这次online DDL操作就是为了修改字符集),那么 colY 的字符集必须包含 colX 的字符集。例如 colX 字符集是 utf8mb3, colY 字符集可以 utf8mb4, 但不可以是 latin1,gbk 等,否则字符串查找可能失败;colX 字符集如果是 latin1,那么 colY 字符集可以是 unicode 各种字符集和 gbk等。
如果 colX 和 / 或 colY 是 domain 类型,那么必须确保 colY 的有效值范围比 colX 更宽,domain 上定义的各种 check 和约束也是 colY 比 colX 更宽泛,否则数据导入新表也会失败。
3.3 索引
源表和新表可以有完全不同的索引定义和主键定义。例如新表就是为了修改主键,或者增加索引或者唯一索引。但是源表的数据必须能够满足新表的所有唯一索引和主键的约束,否则数据导入会失败。
3.4 分区规则和参数
源表和新表可以有完全不同的 表分区规则、表分区参数。源表和新表都可以是 单表、镜像表、分区表 中的某一种。例如源表是单表,未分区,新表按照某种规则分区;或者新表是镜像表;源表 是镜像表,新表是单表或者分区表;源表和新表使用不同的分区规则(例如 hash -> range) 或者分区参数(例如都是 hash 分区,但是源表 4 个分区,新表 16 个分区)。
3.5 表约束
源表和新表可以有不同的表级 check 约束和触发器定义,但是源表的数据必须能够通过新表的 check 约束否则数据导入会失败。
综上可以看出,使用 Klustron 的 repartition 功能,一次操作就 可以统一地做一系列 DDL和表重分区操作,从而大大降低 DBA 的运维管理复杂性和时间开销,并且避免影响应用系统正常运行。
4 配置使用:
4.1 通过cluster_mgr 提供表重分布接口完成操作。
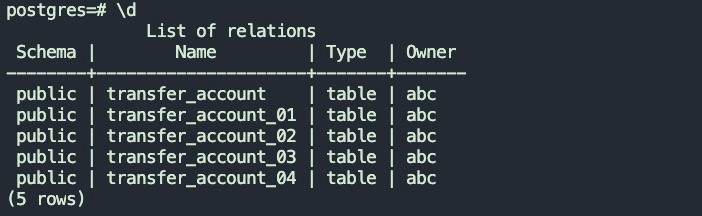
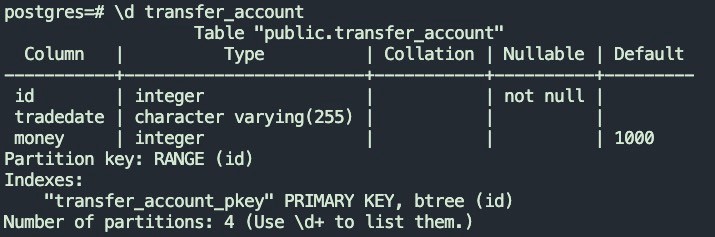
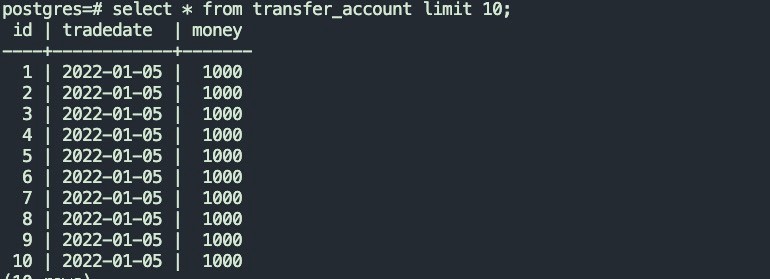
4.1.1 源表结构以及数据如下:
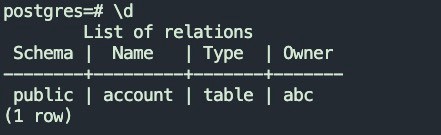
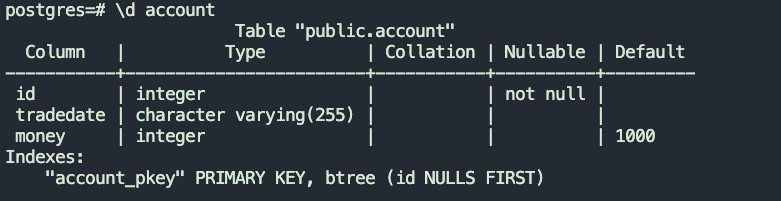
4.1.2 目标表结构
4.1.3 调用 cluster_mgr 表重分布 api
curl -d '
{
"version":"1.0",
"job_id":"",
"job_type":"table_repartition",
"timestamp":"1435749309",
"user_name":"kunlun_test",
"paras":{
"src_cluster_id":"1",
"dst_cluster_id":"3",
"repartition_tables":"postgres_$$_public.transfer_accout=>postgres_$$_public.account"
}
}
' -X POST http://127.0.0.1:58000/HttpService/Emit
该接口为异步接口,返回 job_id,根据返回的 job_id 查询任务执行状态。
curl -d '
{
"version":"1.0",
"job_id":"10",
"job_type":"get_status",
"timestamp":"1435749309",
"user_name":"kunlun_test",
"paras":{
}
}
' -X POST http://127.0.0.1:58000/HttpService/Emit
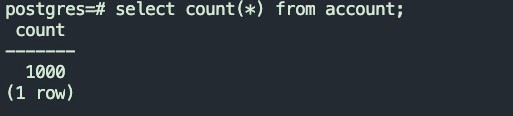
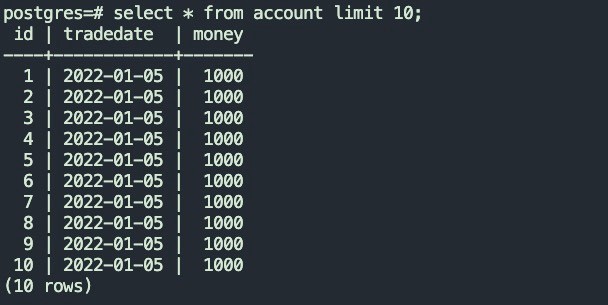
4.1.4 表任务执行成功后,目标表数据情况
源表数据量

目标数据量
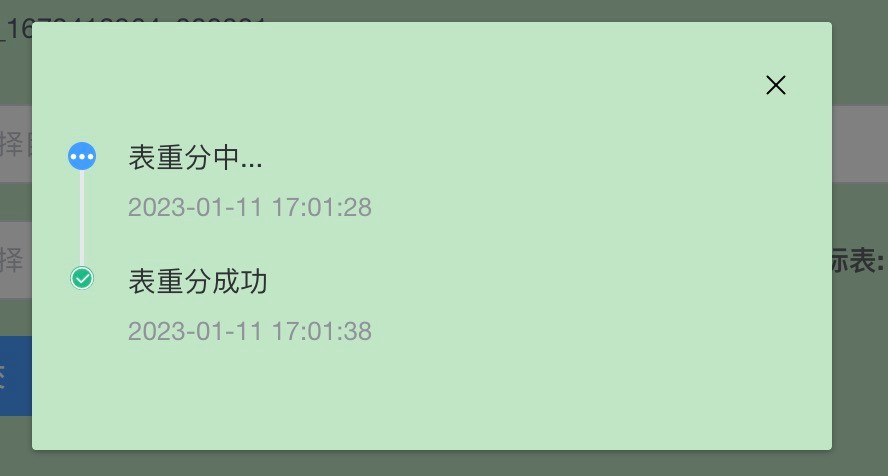
4.2 通过xpanel界面进行表重分布操作
4.2.1 登录源表所在集群设置页面
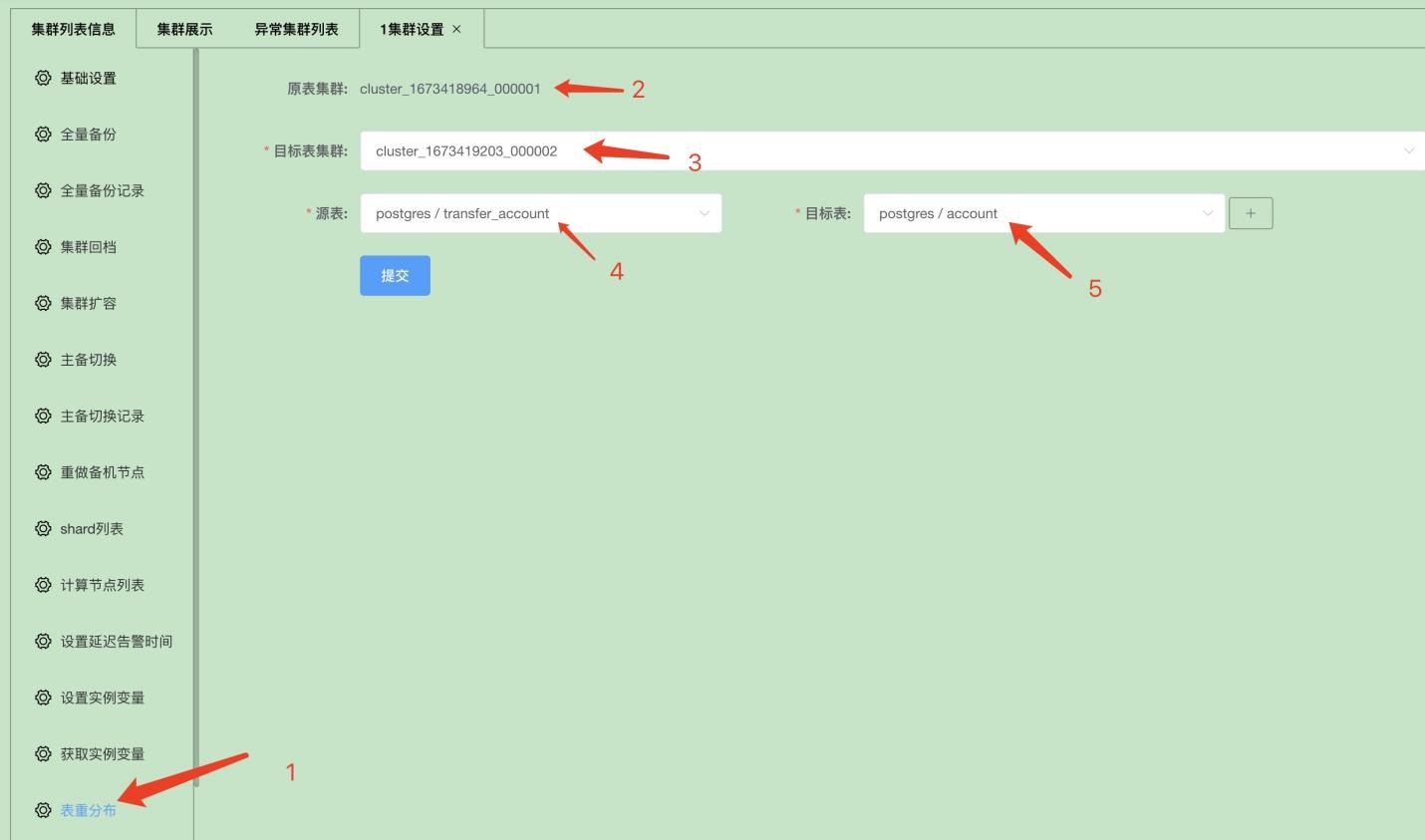
4.2.2 选择配置好后,点击提交按钮