
Klustron集群运维操作
Klustron集群运维操作
01 集群各组件启停
1.1 计算节点启停
查看计算节点进程:
ps -ef|grep $port # $port是指计算节点的端口号
示例:
ps -ef|grep 23001
到计算节点的安装目录中与bin目录同级的scripts目录下:
cd /$install_dir/instance_binaries/computer/$port/kunlun-server-$version/scripts
# $install_dir是指计算节点安装目录
# $port是指计算节点端口号
# $version是指计算节点的版本号,例如:1.2.1
示例:
cd /data/ha/kunlun/instance_binaries/computer/23001/kunlun-server-1.2.1/scripts
启动:
python2 start_pg.py --port=$port
示例:
python2 start_pg.py --port=23001
停止:
python2 stop_pg.py --port=$port
示例:
python2 stop_pg.py --port=23001
1.2 存储节点启停
查看存储节点进程:
ps -ef|grep $port # $port是指存储节点的端口号
示例:
ps -ef|grep 33503
到存储节点的安装目录中与bin目录同级的scripts目录下:
cd/$install_dir/instance_binaries/storage/$port/kunlun-storage-$version/dba_tools
# $install_dir是指存储节点安装目录
# $port是指存储节点端口号
# $version是指存储节点的版本号,例如:1.2.1
示例:
cd /data/ha/kunlun/instance_binaries/storage/33503/kunlun-storage-1.2.1/dba_tools
启动:
./startmysql.sh $port
示例:
./startmysql.sh 33503
停止:
./stopmysql.sh $port
示例:
./stopmysql.sh 33503
1.3 cluster_mgr节点启停
查看cluster_mgr进程:
ps -ef|grep cluster_mgr
到cluster_mgr的安装目录中与conf目录同级的bin目录下:
cd /$install_dir/kunlun-cluster-manager-$version/conf/cluster_mgr.cnf
# $install_dir是指cluster_mgr安装目录
# $version是指计算节点的版本号,例如:1.2.1
示例:
cd /data/ha/kunlun/kunlun-cluster-manager-1.2.1/bin
启动:
./start_cluster_mgr.sh
停止:
./stop_cluster_mgr.sh
1.4 node_mgr节点启停
查看node_mgr进程:
ps -ef|grep node_mgr
到node_mgr的安装目录中与conf目录同级的bin目录下:
cd /$install_dir/kunlun-node-manager-$version/conf/
# $install_dir是指node_mgr安装目录
# $version是指计算节点的版本号,例如:1.2.1
示例:
cd /data/ha/kunlun/kunlun-node-manager-1.2.1/bin
启动:
./start_node_mgr.sh
停止:
./stop_node_mgr.sh
1.5 元数据节点启停
Tips :元数据集群的启停方式和存储节点的启停方式相同,但需要注意修改对应安装目录和对应的端口号。
1.6 XPanel启停
查看xpanel进程:
sudo docker ps -a
**Tips:**查看xpanel进程的状态:Exited表示进程停止,Up表示进程存活。
启动:
sudo docker container start $xpanel_service_name
# $xpanel_service_name是指xpanel服务名,由xpanel_$xpanel-service-p
# ort组成,例如xpanel_10024
示例:
sudo docker container start xpanel_10024
停止:
sudo docker container stop $xpanel_service_name
示例:
sudo docker container stop xpanel_10024
1.7 扩缩机器节点
扩容机器节点
扩容机器节点用作于什么组件,由配置参数nodetype决定,nodetype: 用于指定机器的用途,字符串类型,当前有 4 个可选值 'none', 'storage', 'server', 'both', 分别表示该机器将不部署任何节点,用于部署存储节点,用于部署计算节点,以及用于部署存储和计算节点。值默认为 both。
编辑新的json文件,例如add_node.json文件,在中控机/data1/softwares/setuptools-36.5.0/cloudnative/cluster目录下编辑文件,配置的内容样例如下:
{
"machines":[
{
"ip":"192.168.0.132",
"basedir":"/data1/kunlun",
"user":"kunlun"
},
{
"ip":"192.168.0.134",
"basedir":"/data1/kunlun",
"user":"kunlun"
}
],
"meta":{
"group_seeds": "192.168.0.110:6001,192.168.0.111:6002,192.168.0.100:6003"
},
"node_manager": {
"nodes": [
{
"ip": "192.168.0.132"
},
{
"ip": "192.168.0.134"
}
]
}
}
以上配置样例中,machines表示新增扩容的机器信息;meta表示当前元数据集群ip和port;node_manager表示执行cluster_mgr下发命令的组件,每台机器都需要部署。
在机器扩容前,新增的机器需要按照3.2.1章节“部署前准备工作-所有机器操作”和3.2.2章节中的第一个步骤“中控机与其他机器配置SSH互信”。
执行机器扩容
原集群中控机上,kunlun用户执行命令:
cd /data1/softwares/setuptools-36.5.0/cloudnative/cluster
sudo python2 setup_cluster_manager.py --config=add_node.json --action=install
bash -e clustermgr/install.sh
扩容机器完成后,可以在XPanel的“计算机管理”->“计算机列表”查看到新扩容的机器。如下图片中红框的就是新增的机器。
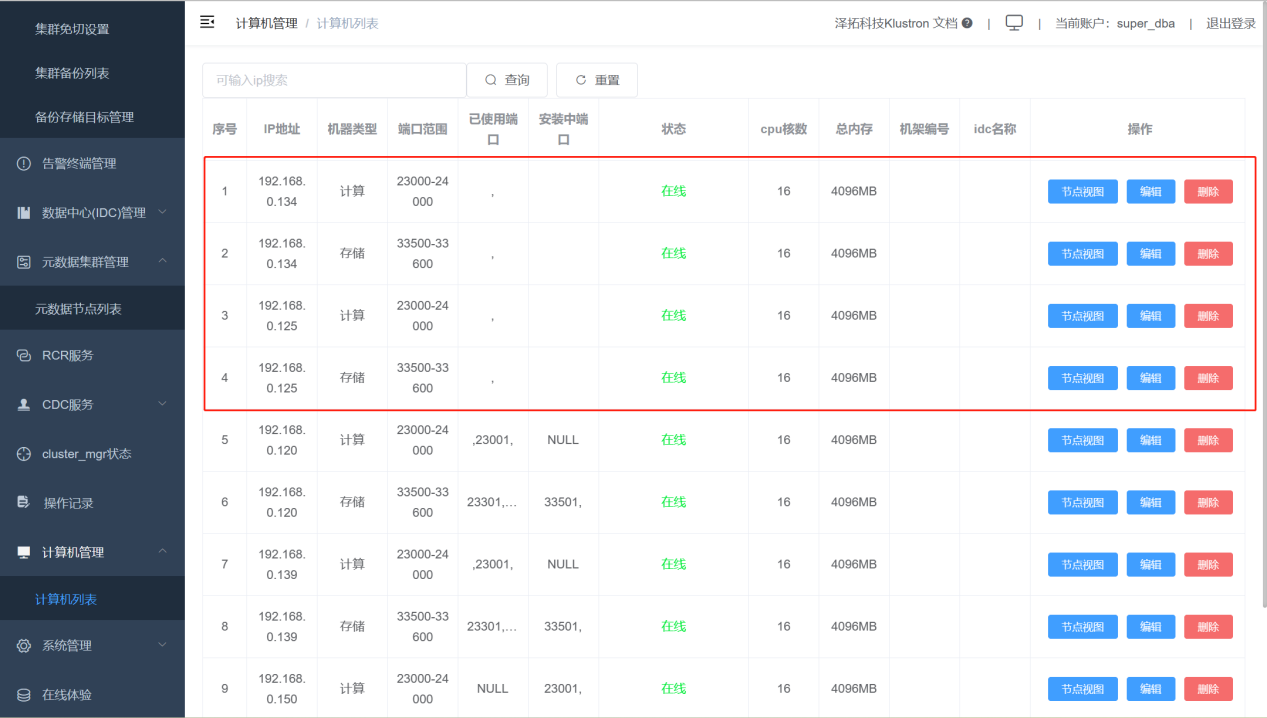
缩容机器节点
1.8 摧毁所有集群
高危警告!!!再三确认所有集群可以摧毁后,方可执行,此操作不可逆!!!
中控机上执行摧毁所有集群命令:
cd /data1/softwares/setuptools-36.5.0/cloudnative/cluster
python setup_cluster_manager.py --autostart --config=$config_file --product_version=$version --action=clean
bash /data1/softwares/setuptools-36.5.0/cloudnative/cluster/clustermgr/clean.sh
# $config_file是指Klurton Cluster的拓扑文件,文件以.json格式结尾。
# $version是指当前集群的版本号,例如:1.2.1
示例:
python setup_cluster_manager.py --autostart --config=cluster_and_node_mgr.json --product_version=1.2.1 --action=clean
bash /data1/softwares/setuptools-36.5.0/cloudnative/cluster/clustermgr/clean.sh
02 各组件日志目录和配置文件目录
2.1 日志目录
Tips :klustron集群中各个模块的端口号都可以在XPanel上进行查看。
计算节点kunlun-server
通过如下命令查看计算节点kunlun-server日志目录:
ps -ef|grep 23001
#这里以23001计算节点端口号为例
如图:
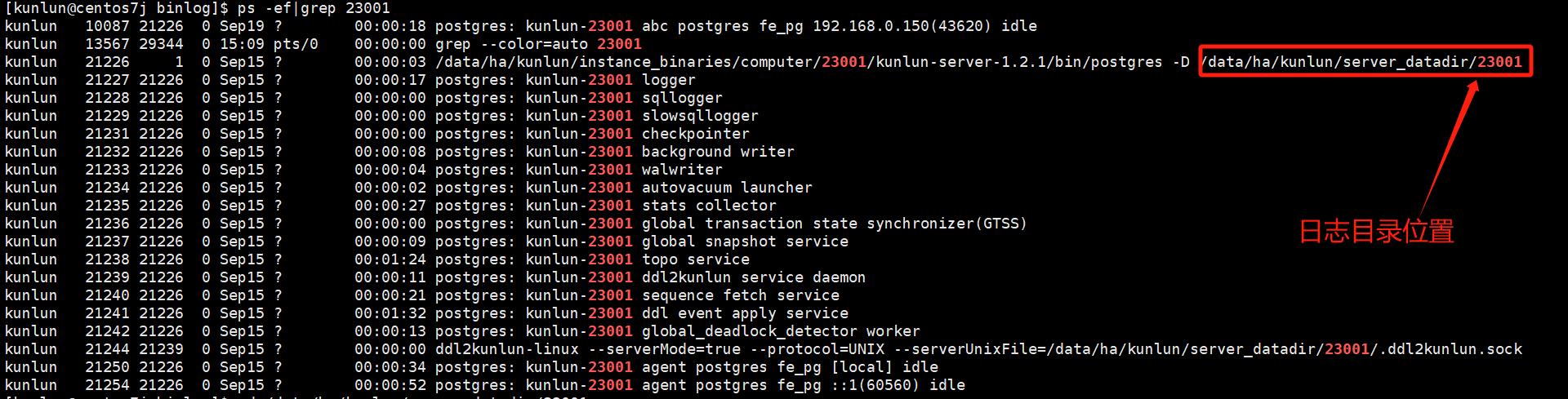
cd /data/ha/kunlun/server_datadir/23001/log
如图:
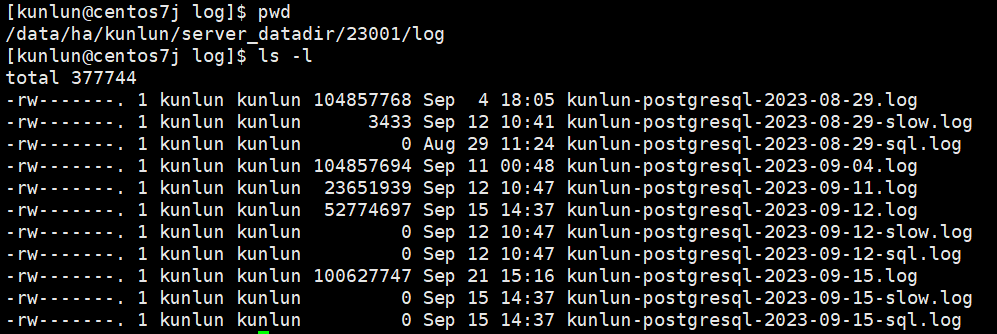
日志文件分类:
- kunlun-postgresql-*.log 记录的是计算节点运行日志文件,记录计算节点运行期间所接收到SQL语句与计算节点程序本身的日志、ERROR、WARNING等信息。
- kunlun-postgresql-*-slow.log 记录的是计算节点出现的慢SQL日志,计算节点上慢SQL由变量log_min_duration_statement控制阈值大小,默认值10,单位s,超过10s的sql会记录到该日志文件中。
- kunlun-postgresql-*-sql.log 记录的是从计算节点发给存储节点的SQL语句,由变量enable_sql_log控制打开或者关闭该日志,默认值off,处于关闭。
存储节点storage-server
通过如下命令查看存储节点storage-server日志目录:
ps -ef|grep 33501
#这里以33501存储节点端口号为例
cd /data/ha/kunlun/storage_logdir/33501
如图:
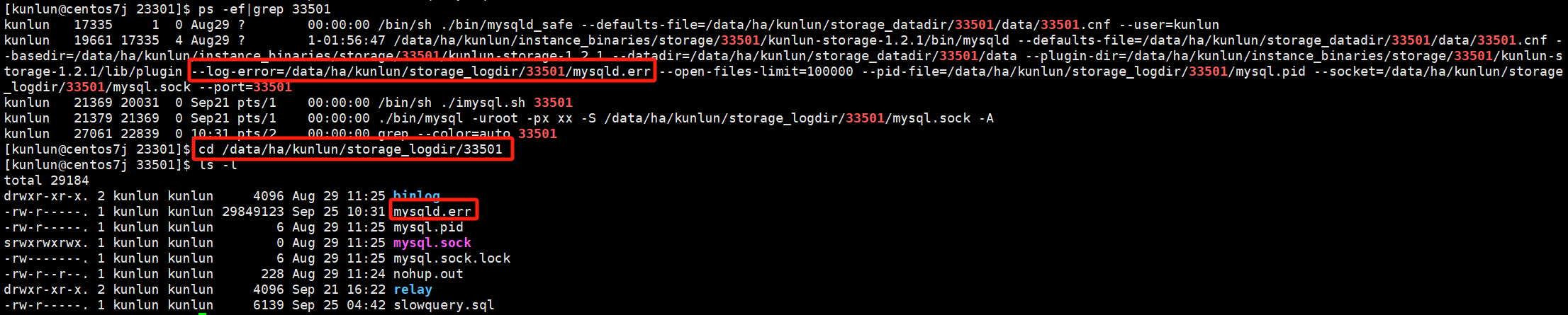
主要查看的是mysqld.err日志,该日志记录存储节点运行信息、Warning、ERROR等信息。
cluster_mgr节点
通过如下命令查看cluster_mgr节点日志目录:
ps -ef|grep cluster_mgr
log目录与conf目录同级
cd /data/ha/kunlun/kunlun-cluster-manager-1.2.1/log
如图:
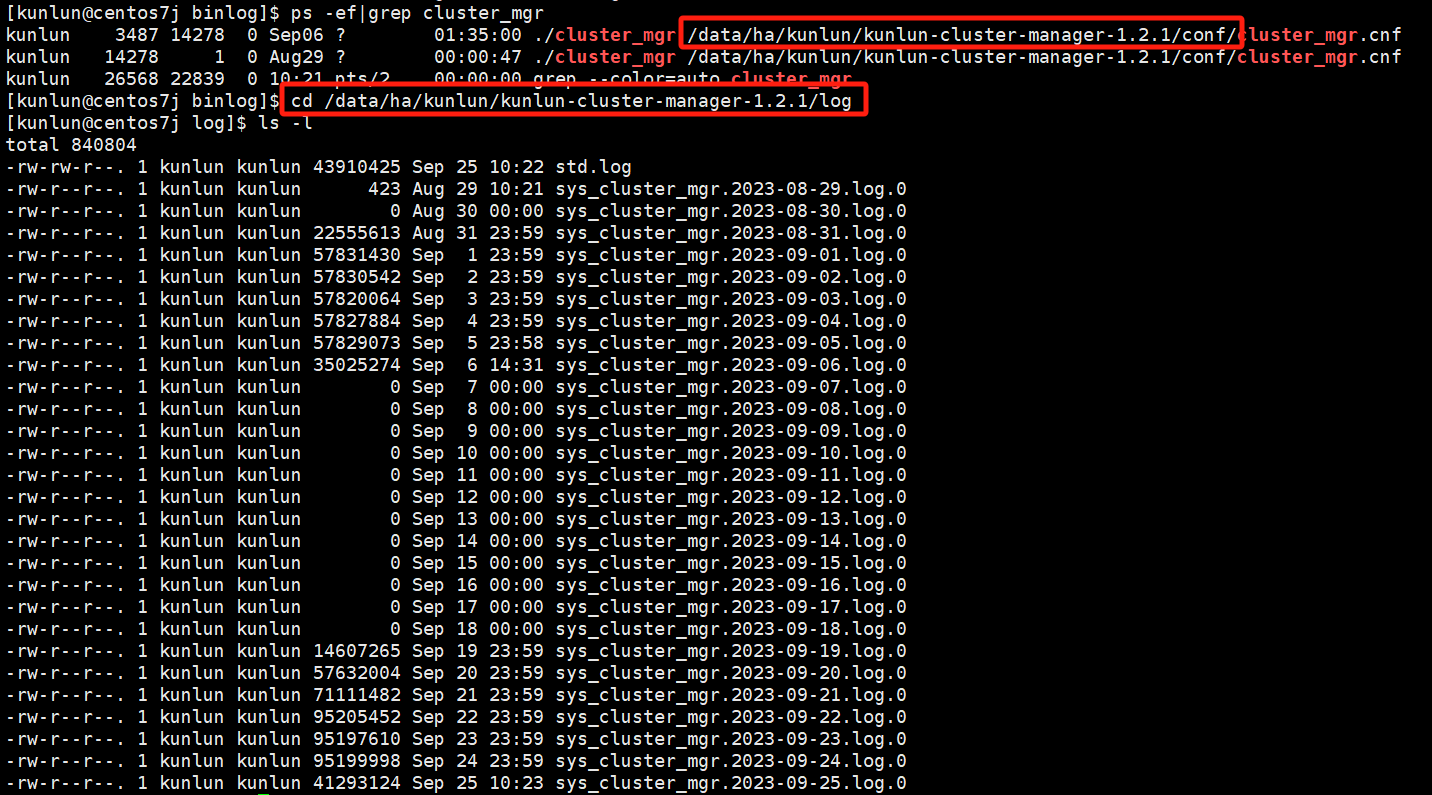
主要查看的是sys_cluster_mgr*.log.*日志,记录的是cluster_mgr运行期间打印的任务,管理调度,错误等信息。
元数据集群
通过如下命令查看元数据节点日志目录:
ps -ef|grep 23301
# 这里以23301元数据节点端口号为例
cd /data/ha/kunlun/storage_logdir/23301/
如图:

主要查看的是mysqld.err日志,该日志记录元数据节点运行信息、Warning、ERROR等信息。
node_mgr节点
通过如下命令查看node_mgr节点日志目录:
ps -ef|grep node_mgr
log目录与conf目录同级
cd /data/ha/kunlun/kunlun-node-manager-1.2.1/log
如图:
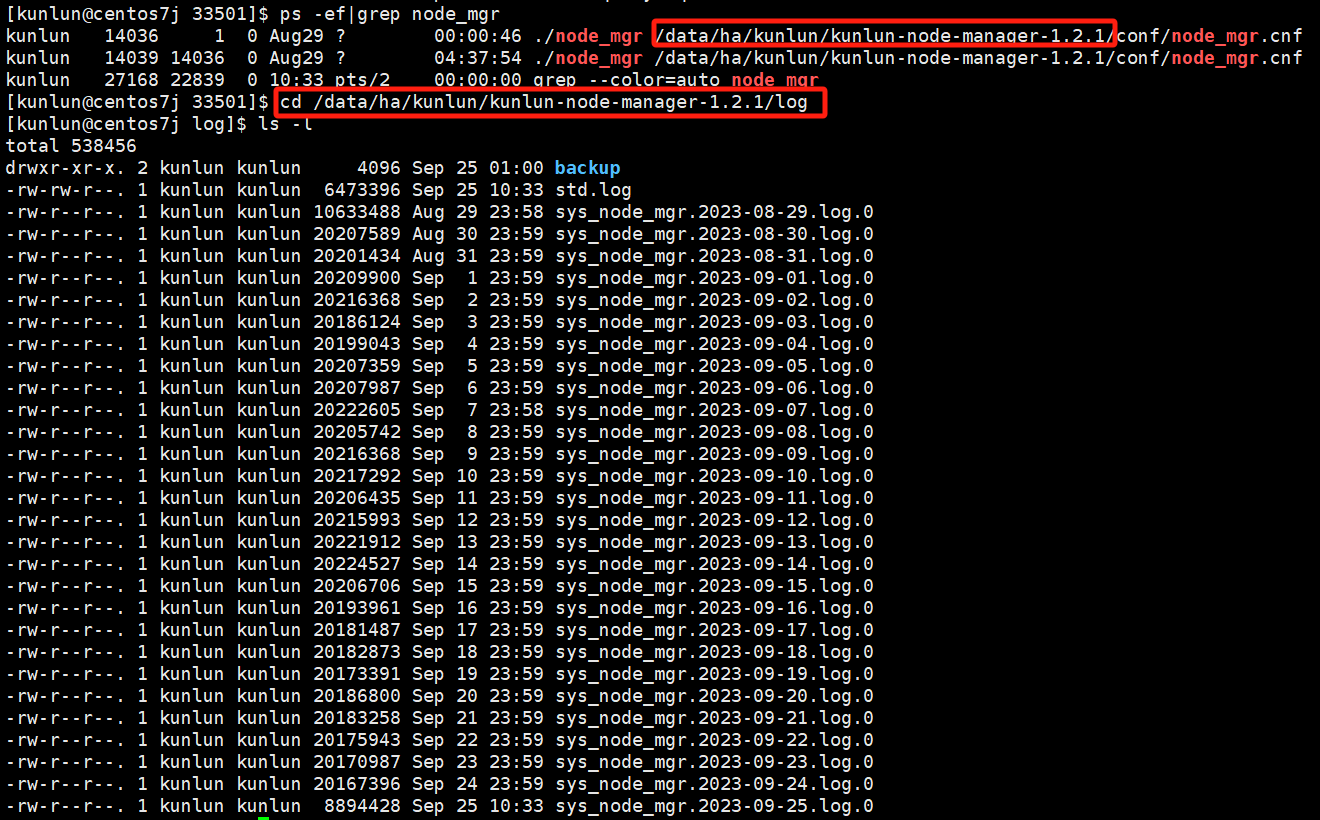
主要查看的是sys_node_mgr.*.log.*日志,该日志记录着cluster_mgr下发的任务让node_mgr执行的相关shell命令,例如:集群安装,扩缩容节点,备份恢复,主备切换等任务对应的shell命令。
2.2 修改配置模板
在创建集群前如有特殊需求,可以在配置模板中修改对应的配置,最后再创建集群。
计算节点
环境部署前
修改步骤如下:
到部署工具目录下,以Klustron1.2.1集群版本命令为例:
cd setuptools-36.5.0/cloudnative/cluster/clustermgr
tar xf kunlun-server-1.2.1.tgz
cd kunlun-server-1.2.1/resources
vim postgresql.conf
如图:
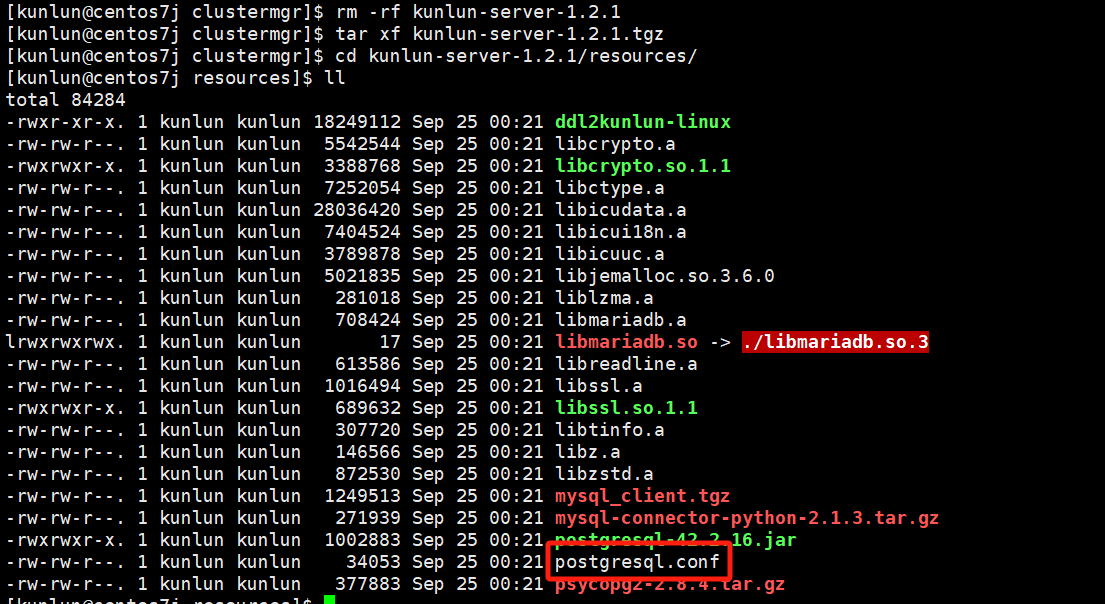
编辑配置模板文件,修改对应的配置值即可。请注意!!!修改配置值之前可以与Klustron数据库团队确认是否可以更改,以免配置失败影响使用。
最后打包压缩:
mv kunlun-server-1.2.1.tgz kunlun-server-1.2.1_bak.tgz
tar czf kunlun-server-1.2.1.tgz kunlun-server-1.2.1/
再按照部署步骤完成部署。
环境部署后
Klustron的环境已经部署完成,使再次创建集群时按照新的配置文件进行配置。
修改步骤如下:
cd $base_dir/program_binaries/kunlun-server-1.2.1/resources
vim postgresql.conf
$base_dir是指安装基础目录,可以在部署时的拓扑文件.json中查看。
以Klustron1.2.1集群版本命令为例:
cd /data/ha/kunlun/program_binaries/kunlun-server-1.2.1/resources
vim postgresql.conf
如图:
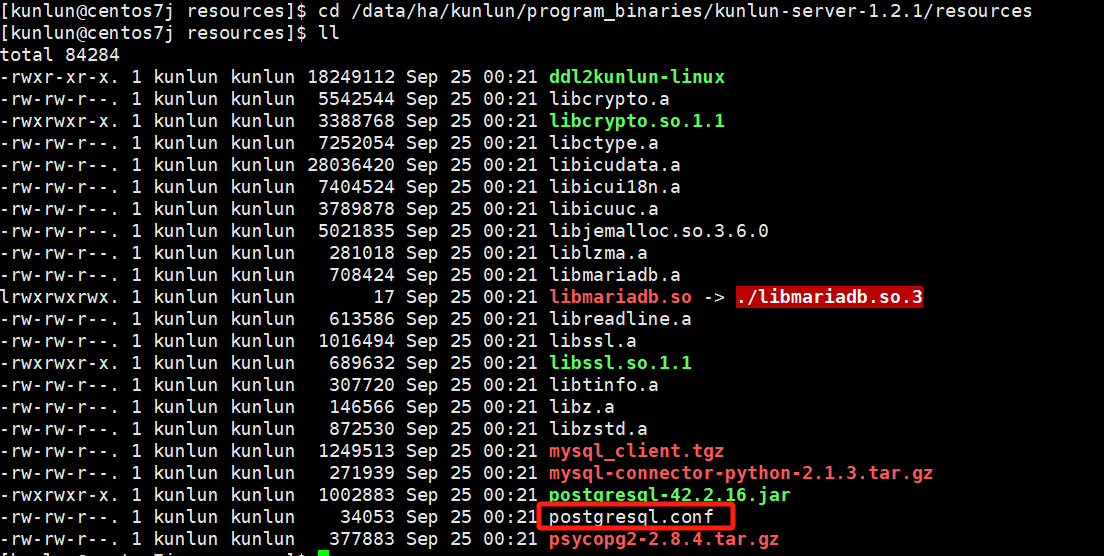
编辑配置模板文件,修改对应的配置值即可。请注意!!!修改配置值之前可以与Klustron数据库团队确认是否可以更改,以免配置失败影响使用。
存储节点
环境部署前
修改步骤:
到部署工具目录下,以Klustron1.2.1集群版本命令为例:
cd setuptools-36.5.0/cloudnative/cluster/clustermgr
tar xf kunlun-storage-1.2.1.tgz
cd kunlun-storage-1.2.1/dba_tools
vim template-rbr.cnf
如图:
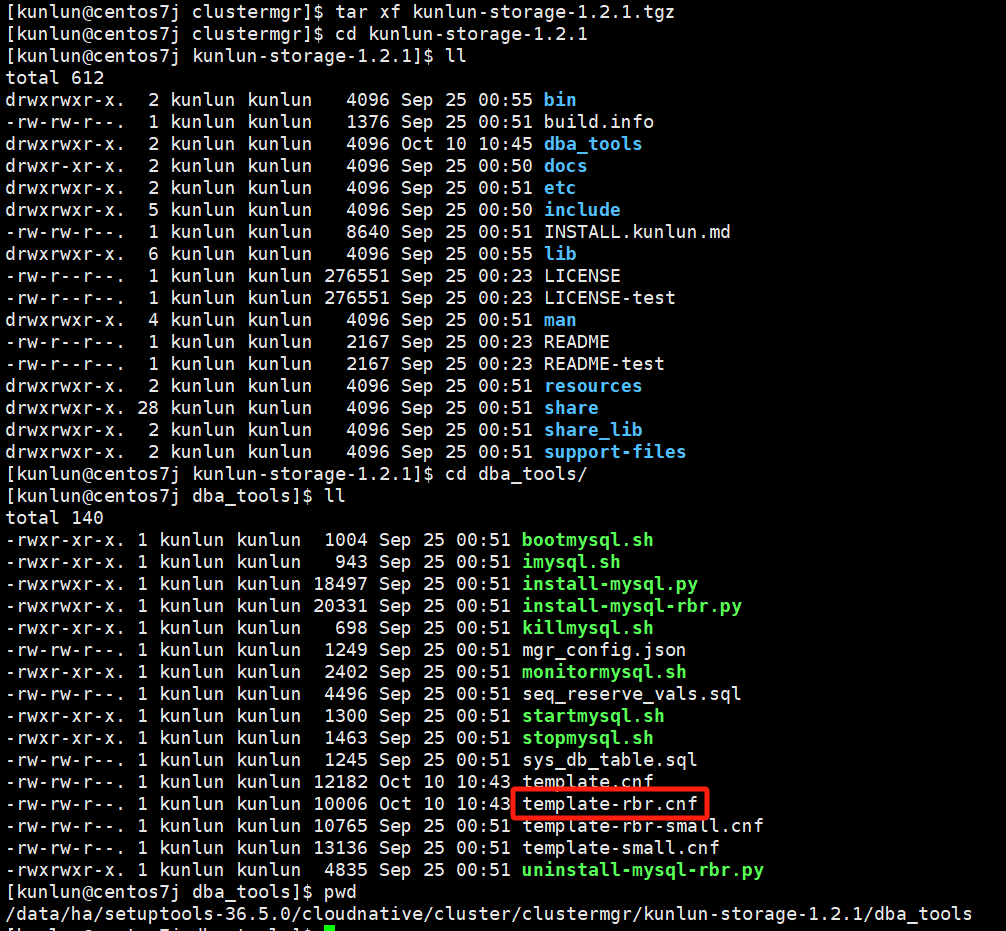
编辑配置模板文件,修改对应的配置值即可。请注意!!!修改配置值之前可以与Klustron数据库团队确认是否可以更改,以免配置失败影响使用。
最后打包压缩:
mv kunlun-storage-1.2.1.tgz kunlun-storage-1.2.1_bak.tgz
tar czf kunlun-storage-1.2.1.tgz kunlun-storage-1.2.1/
环境部署后
Klustron的环境已经部署完成,使再次创建集群时按照新的配置文件进行配置。
修改步骤
cd $base_dir/program_binaries/kunlun-storage-1.2.1/dba_tools
vim template-rbr.cnf
$base_dir是指安装基础目录,可以在部署时的拓扑文件.json中查看。
以Klustron1.2.1集群版本命令为例:
cd /data/ha/kunlun/program_binaries/kunlun-storage-1.2.1/dba_tools
vim template-rbr.cnf
如图:
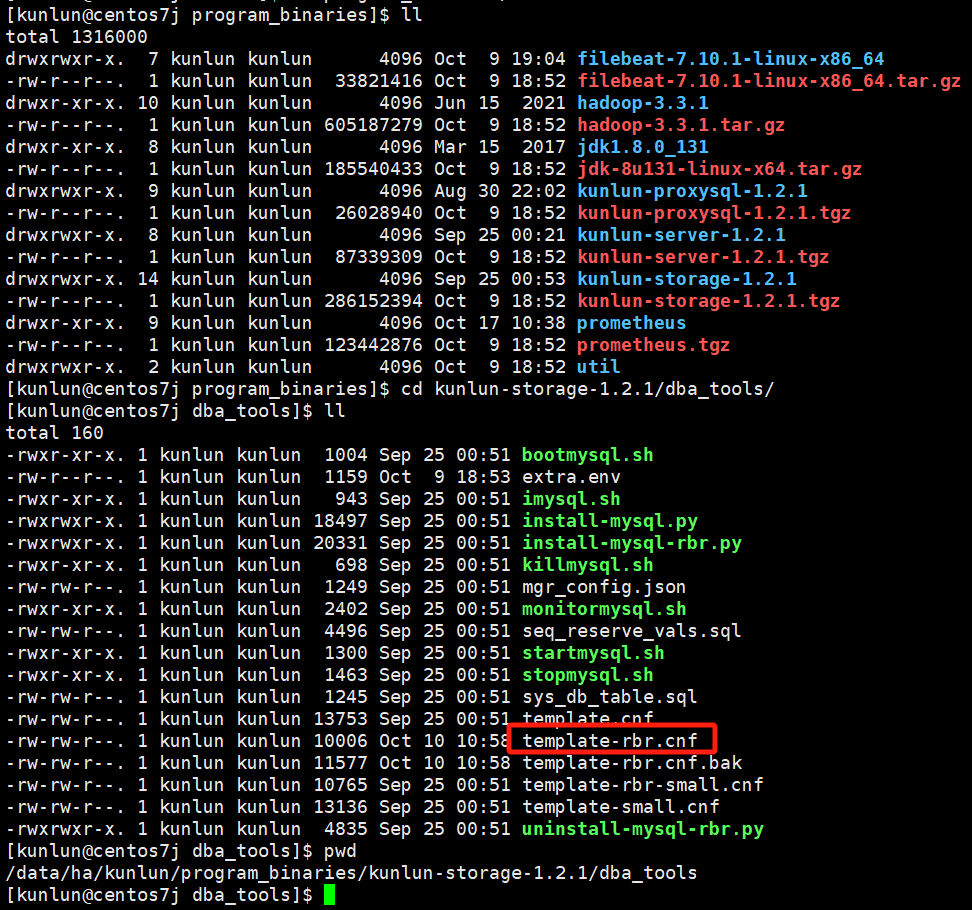
编辑配置模板文件,修改对应的配置值即可。请注意!!!修改配置值之前可以与Klustron数据库团队确认是否可以更改,以免配置失败影响使用。
2.3 配置文件目录与生效
注意:众多情况下,计算节点、存储节点、元数据集群、cluster_mgr、node_mgr的配置文件一般情况下用户不需要去修改,除特殊情况外,这里只是介绍配置文件所在路径,以供特殊情况使用!!!
计算节点配置文件目录
通过如下命令查看计算节点kunlun-server日志目录:
ps -ef|grep 23001
# 这里以23001计算节点端口号为例
如图:
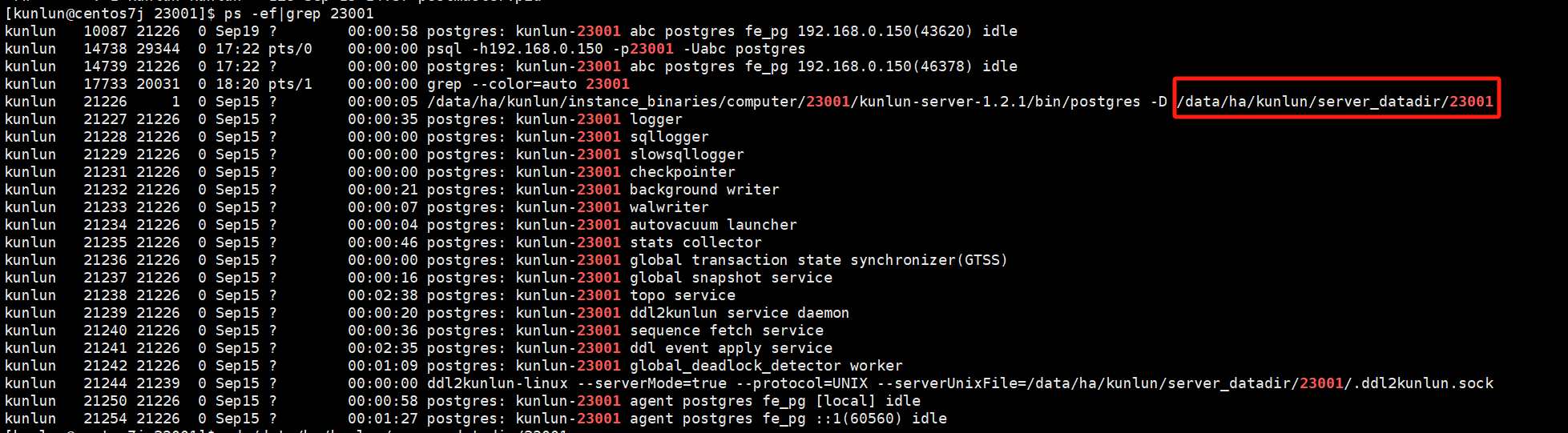
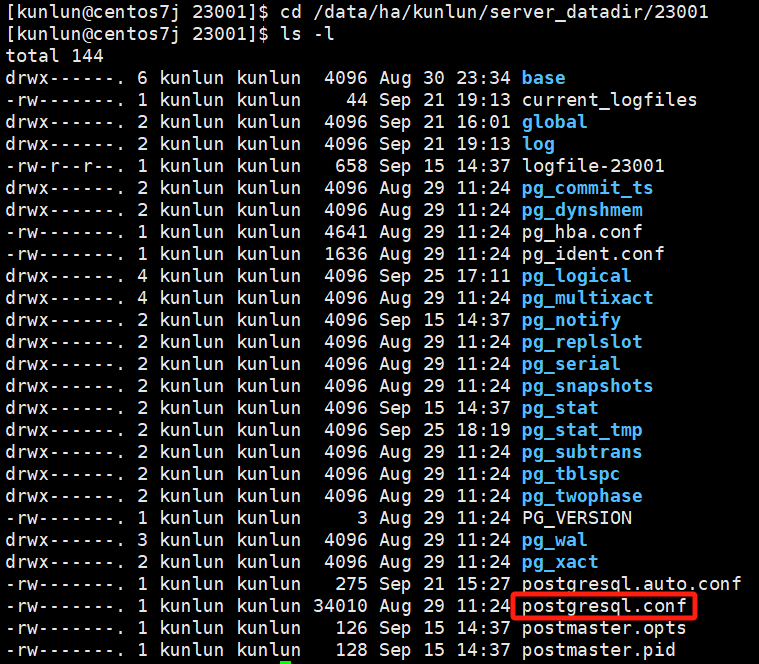
在计算节点中分为多种类型的系统变量,不同的系统变量生效的方式不同,如需修改系统变量并使其生效,见如下链接中计算节点部分内容:
http://doc.klustron.com/zh/Klustron_system_variable.html
存储节点配置文件
通过如下命令查看存储节点storage-server日志目录:
ps -ef|grep 33501
# 这里以33501存储节点端口号为例
如图:

存储节点中如需修改系统变量并使其生效,见如下链接中存储节点部分内容:
http://doc.klustron.com/zh/Klustron_system_variable.html
元数据节点配置文件
通过如下命令查看元数据节点日志目录:
ps -ef|grep 23301
#这里以23301元数据节点端口号为例
如图:

cluster_mgr节点配置文件目录
通过如下命令查看cluster_mgr节点配置文件目录:
ps -ef|grep cluster_mgr
如图:

修改配置文件后,生效方式需要重启cluster_mgr,参考1.3章节内容。
node_mgr节点配置文件目录
通过如下命令查看node_mgr节点日志目录:
ps -ef|grep node_mgr
如图:

2.4 服务器角色等信息
通过登录元数据集群获取相关信息
03 负载均衡配置
Klustron不提供负载均衡组件,由用户自己按需提供使用。负载均衡配置方法如下:在集群创建完成后,用户通过将计算节点的ip和port配置到负载均衡中,即可完成并可以连接负载均衡提供的ip进行访问Klustron。
04 导入导出工具
Klustron支持copy命令进行导入导出,也支持pg_dump和pg_restore,还有myloader和mydumper工具进行数据导入导出。
COPY命令
copy命令方式
通过postgresql客户端登录后,执行命令。
Tips :导入之前需要已有表结构或者先导入表结构。
导入:忽略首行,列间隔用“,”表示的csv文件
copy t1 from '/data/ha/sbtest_sourcedata/sbtest_sourcedata/sbt1/t1.0001.csv' with delimiter ',' csv header;
如图:

导出:整表数据,不带表头
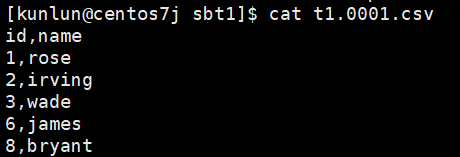
copy t1 to '/data/ha/sbtest_sourcedata/sbtest_sourcedata/sbt1/t1.000.csv' with delimiter ',' csv;
如图:
导出的CSV文件示例:

导出:整表数据,带表头
copy t1 to '/data/ha/sbtest_sourcedata/sbtest_sourcedata/sbt1/t1.0001.csv' with delimiter ',' csv header;
导出的CSV文件示例:
Copy命令常用参数说明:
csv **:**表示文件格式
header : 表示文件第一行为字段名,导入数据库时忽略首行
delimiter **:**表示字段分割方式,示例是以逗号分割
encoding **:**表示文件编码方式,示例是 GBK 编码,(默认为utf-8)
quote **:**指定需要用什么符号来将指定列进行定界符,指定一个数据值被引用时使用的引用字符。默认是双引号。 这必须是一个单一的单字节字符。只有使用 CSV格式时才允许这个选项。
force quote **:*根据指定的列进行定界符,使用时force quote不需要加“_”。强制必须对每个指定列中的所有非NULL值使用引用。 NULL输出不会被引用。如果指定了, 所有列的非NULL值都将被引用。只有在 COPY TO中使用CSV格式时才允许这个选项。
quote使用示例:
copy t1 to '/data/ha/sbtest_sourcedata/sbtest_sourcedata/sbt1/t1.csv' with delimiter ',' csv force quote name;
如图:

导出的CSV文件示例:

force quote使用示例:
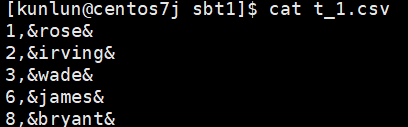
copy t1 to '/data/ha/sbtest_sourcedata/sbtest_sourcedata/sbt1/t_1.csv' with delimiter ',' csv quote '&' force quote name;
如图:

导出的CSV文件示例:
pg_dump和pg_restore
关于pg_dump和pg_restore命令参数的介绍见官网文档:
pg_dump:
http://www.postgres.cn/docs/11/app-pgdump.html
pg_restore:
http://www.postgres.cn/docs/11/app-pgrestore.html
如下是常用的pg_dump和pg_restore命令的介绍:
- pg_dump导出
由于导入导出工具客户端需要与服务端版本匹配的原因,需要使用配套工具操作。
pg_dump导入和pg_restore导出工具的存放目录位于计算节点如下目录:
这里以kunlun-server的端口号23001为例:
ps -ef|grep 23001
图片示例:
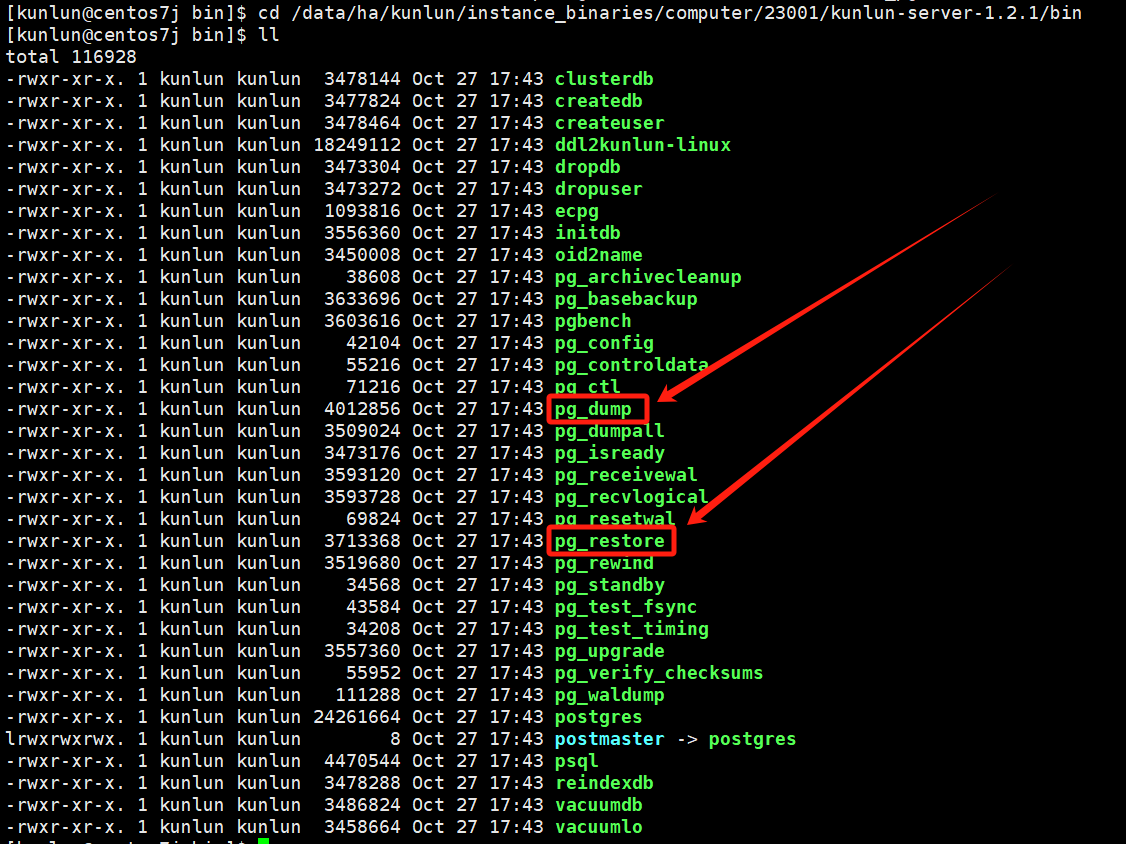
查看pg_dump和pg_restore所在的目录:
cd /data/ha/kunlun/instance_binaries/computer/23001/kunlun-server-1.2.1/bin
ls -l
图片示例:
导出指定库(这里以pgdb库为例),导出的文件为sql文本:
./pg_dump -h192.168.0.150 -p23001 -Uabc -d pgdb > pgdb.sql
导出指定表(这里以n1表为例),导出的文件为sql文本:
./pg_dump -h192.168.0.150 -p23001 -Uabc -d pgdb -t n1 > n1.sql
导出指定表结构(这里以n1表为例),导出的文件为sql文本:
./pg_dump -h192.168.0.150 -p23001 -Uabc -d pgdb -t n1 -s > n1_s.sql
导出指定表数据(这里以n1表为例),导出的文件为sql文本:
./pg_dump -h192.168.0.150 -p23001 -Uabc -d pgdb -t n1 -a > n1_data.sql
导出多个表(这里以t1和t2表为例),导出的文件为sql文本:
./pg_dump -h192.168.0.150 -p23001 -Uabc -d pgdb -t t1 -t t2 > t.sql
注意:以下格式不同于文本格式的sql文件:
导出指定库(转储一个数据库到一个自定义格式归档文件,以nb库为例):
./pg_dump -h192.168.0.150 -p23001 -Uabc -d nb -Fc > nb.dump
导出指定表(转储一个数据库到一个自定义格式归档文件,以t1表为例):
./pg_dump -h192.168.0.150 -p23001 -Uabc -d postgres -t t1 -Fc > t1.dump
- psql导入
对于sql文本文件可以使用psql进行导入:
注意:psql 导入的前置条件
前置条件:nb库下的表没有与sql文件中的表冲突。
导入库(以nb库为例):
psql -h192.168.0.150 -p23001 -Uabc nb < nb.sql
前置条件:n1表不存在。
导入表(以n1表为例):
psql -h192.168.0.150 -p23001 -Uabc nb < n1.sql
前置条件:n1表不存在
导入表结构(以n1表为例):
psql -h192.168.0.150 -p23001 -Uabc nb < n1.sql
前置条件:n2表存在,用户决定n2表是否有约束。
导入表数据(以n2表为例):
psql -h192.168.0.150 -p23001 -Uabc nb < n2.sql
- pg_restore导入
对于自定义格式归档文件,可以使用pg_restore
前置条件:nb库已经存在
导入库(以nb库为例,-c参数会删除nb库下面的表,然后再进行导入):
./pg_restore -h192.168.0.150 -p23001 -Uabc -d nb -c -e nb.dump
前置条件:nb库不存在
导入库(以nb库为例,-C参数在导入前创建好nb库):
./pg_restore -h192.168.0.150 -p23001 -Uabc -d postgres -C nb.dump
前置条件:在nb库中n2表不存在。
导入表结构(以n2表为例):
./pg_restore -h192.168.0.150 -p23001 -Uabc -d nb -e n2.dump
前置条件:n2表存在,由用户决定n2表是否有约束。
导入表数据(以n2表为例)
./pg_restore -h192.168.0.150 -p23001 -Uabc -d nb -a -e n2.dump
- myloader导出
- mydumper导入
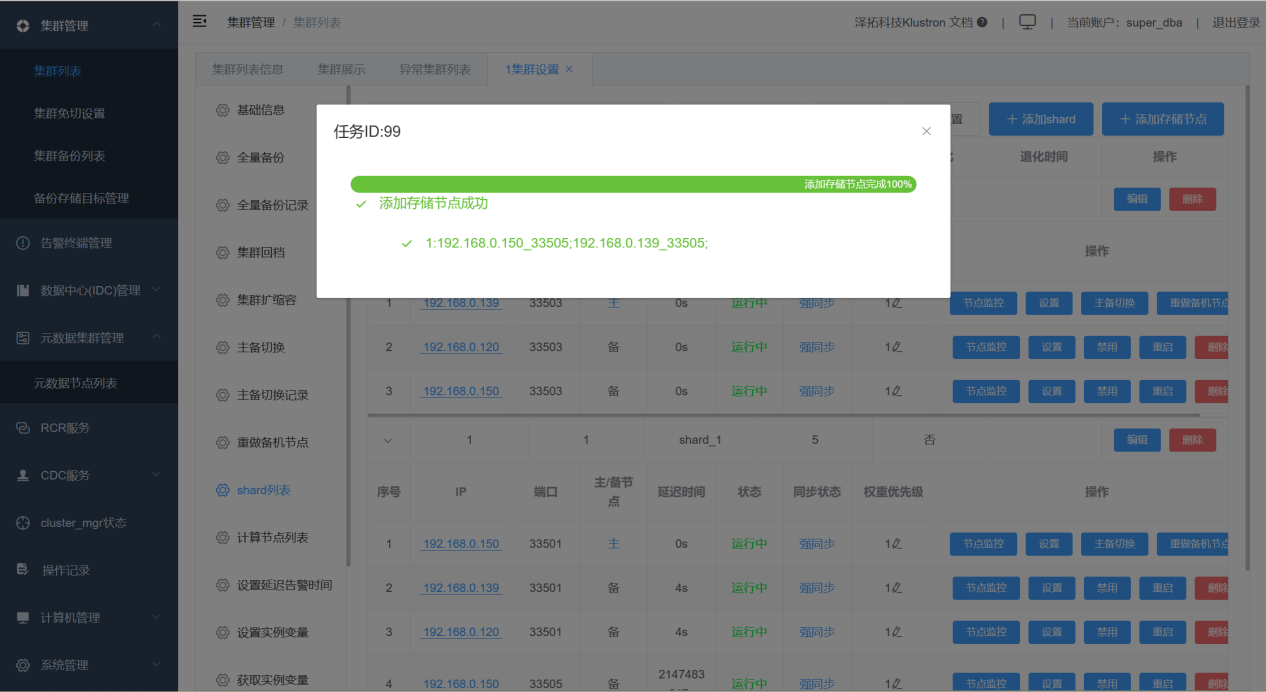
05 添加shard中备节点
通过XPanel上新增shard的备节点:
06 系统变量管理
如需查看Klustron特有的系统变量介绍见链接:
http://doc.klustron.com/zh/Klustron_system_variable.html
enable_global_mvcc
在修改enable_global_mvcc参数时,需要一定的时间窗口进行变更操作,在变更窗口中将所有的计算节点都修改并重启后使该参数生效,验证成功后方可恢复应用访问Klustron。
修改的步骤如下:
- 修改enable_global_mvcc参数
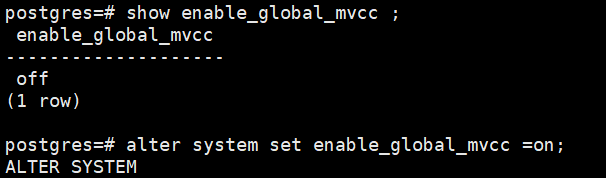
使用postgresql协议登录计算节点,然后执行如下命令:
show enable_global_mvcc ;
alter system set enable_global_mvcc =on;
如图:
- 重启计算节点
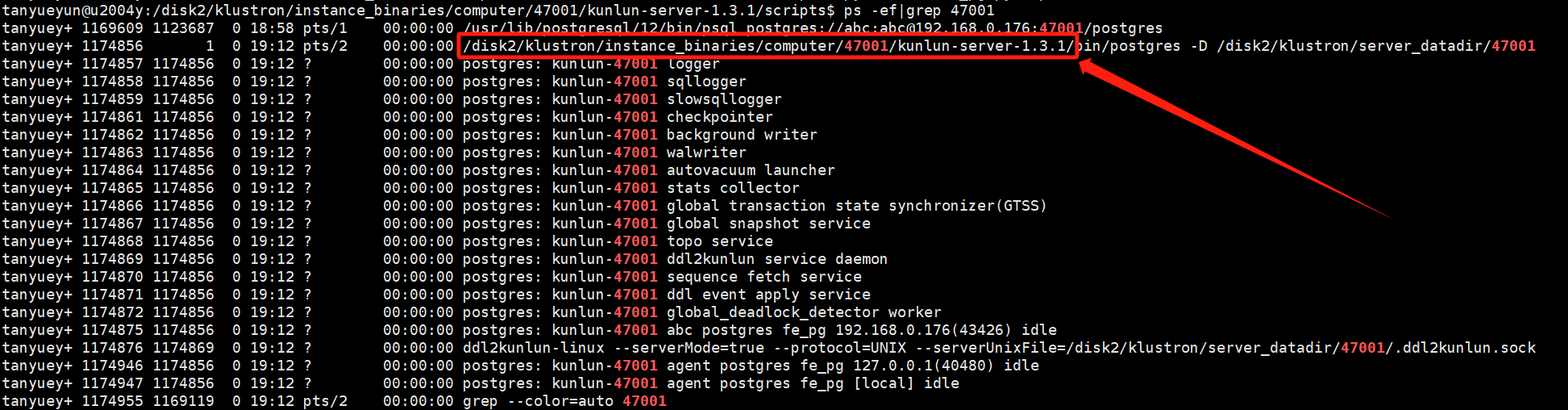
首先查看计算节点进程:
ps -ef|grep $port # $port是指计算节点的端口号
示例:
ps -ef|grep 47001
如图:
到计算节点的安装目录中与bin目录同级的scripts目录下:
cd /$install_dir/instance_binaries/computer/$port/kunlun-server-$version/scripts
# $install_dir是指计算节点安装目录
# $port是指计算节点端口号
# $version是指计算节点的版本号,例如:1.3.1
示例:
cd /disk2/klustron/instance_binaries/computer/47001/kunlun-server-1.3.1/scripts
停止:
python2 stop_pg.py --port=$port
示例:
python2 stop_pg.py --port=47001
启动:
python2 start_pg.py --port=$port
示例:
python2 start_pg.py --port=47001
如图:

- 验证修改成功
使用postgresql协议登录计算节点,然后执行如下命令:
show enable_global_mvcc ;
如图:

注意:其余计算节点遵循如上操作步骤进行修改!!!
07 命令行保底操作
添加计算节点
添加shard
添加备机节点
手动重做备机
当出现XPanel无法使用,又急于故障恢复备机增加高可用性时,可以使用手动的方式进行重做备机。
如下为操作步骤,以重做元数据集群的一个备机为例。
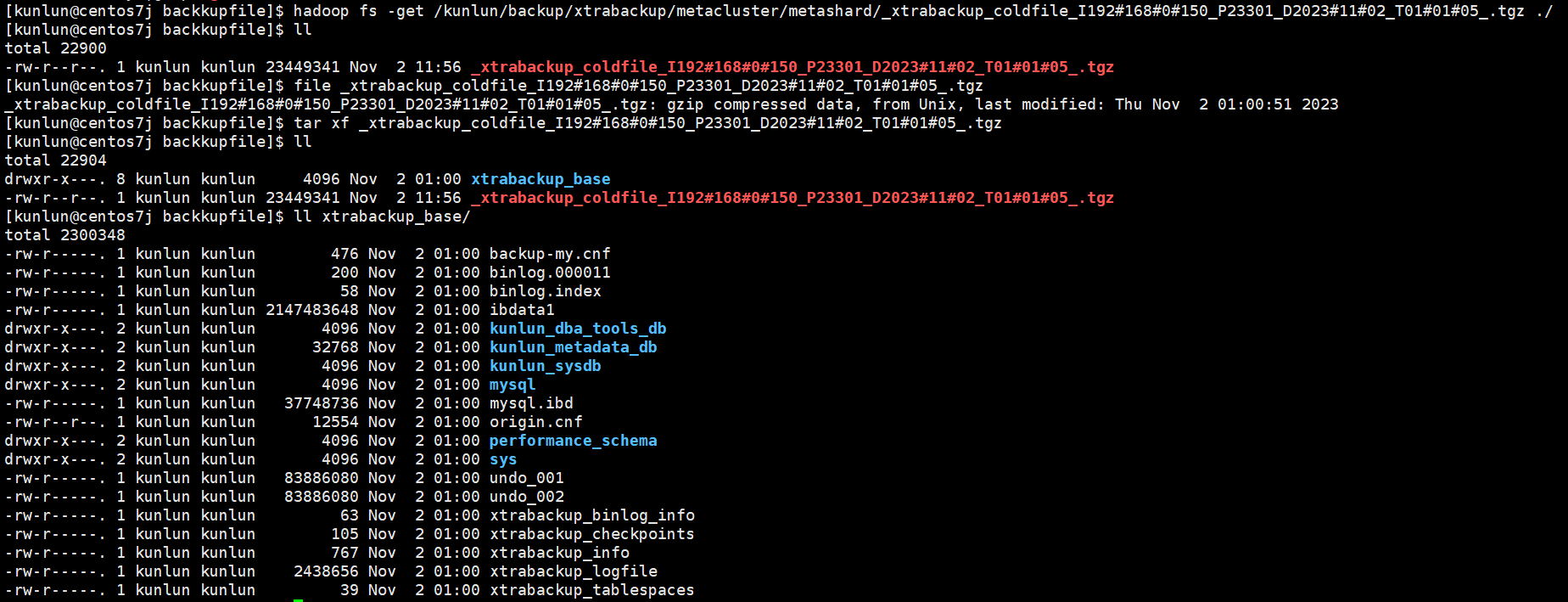
将HDFS上的元数据集群的备份下载到本地,拷贝到对应需要重做的机器上。
查看:
hadoop fs -ls /kunlun/backup/xtrabackup/metacluster/metashard/

从HDFS上下载下来的全备文件存放到已经创建好的目录上:
示例:
mkdir -p /data/ha/backupfile/
# 这里以/data/ha/backupfile/为例,用户可自定义目录名。
特别注意:如下涉及的操作命令以实际的目录和端口号为准!!!变量只做介绍,以用户环境实际情况为准!!!
将全备文件下载后并解压(注意:需要将全备文件拷贝到重做备机的机器上):
hadoop fs -get /kunlun/backup/xtrabackup/metacluster/metashard/**$coldfile**.tgz /data/ha/backupfile/
# **$coldfile**为HDFS上的全备文件,**以实际的为准**。
示例:
hadoop fs -get /kunlun/backup/xtrabackup/metacluster/metashard/_xtrabackup_coldfile_I192#168#0#150_P23301_D2023#11#02_T01#01#05_.tgz /data/ha/backupfile/
tar xf $coldfile.tgz
示例:
tar xf _xtrabackup_coldfile_I192#168#0#150_P23301_D2023#11#02_T01#01#05_.tgz
如图:
解压后进行恢复,步骤如下:
- apply redo日志,完成数据一致性
cd /$install_dir/kunlun-node-manager-$version/bin/
# $install_dir是指node_mgr安装目录
# $version是指部署的版本号,例如:1.2.1
示例:
cd /data/ha/kunlun/kunlun-node-manager-1.2.1/bin/
./util/xtrabackup --prepare --apply-log-only --target-dir=**$fullbackup_base** >> /data/ha/log/rebuild_node_tool_37.log 2>&1
# $fullbackup_base是指解压后的全备目录
# /data/ha/log/rebuild_node_tool_37.log可自定义一个日志文件
示例:
./util/xtrabackup --prepare --apply-log-only --target-dir=/data/ha/backupfile/xtrabackup_base >> ../log/rebuild_node_tool_37.log 2>&1
- 备份配置文件,后续安装实例会用到
cp -a $install_dir/storage_datadir/$port/data/$port.cnf $install_dir/kunlun/storage_datadir/$port/
# $port是指存储节点端口号
示例,以23301端口为例:
cp -a /data/ha/kunlun/storage_datadir/23301/data/23301.cnf /data/ha/kunlun/storage_datadir/23301/
- 停止故障mysqld进程
注意:node_mgr会拉起mysqld进程,进行删除文件的速度要快,保证先停止mysqld****进程再删除数据和日志文件。
示例:
cd /data/ha/kunlun/instance_binaries/storage/23301/kunlun-storage-1.2.1/dba_tools; ./stopmysql.sh 23301
- 删除数据文件和日志文件
注意:以实际的安装目录和端口号为准!!!
rm -rf $install_dir/storage_datadir/$port/data/*
rm -rf $install_dir/storage_datadir/$port/data/.*
rm -rf $install_dir/storage_waldir/$port/redolog/*
rm -rf $install_dir/storage_logdir/$port/relay/*
rm -rf $install_dir/storage_logdir/$port/binlog/*
示例:
rm -rf /data/ha/kunlun/storage_datadir/23301/data/*
rm -rf /data/ha/kunlun/storage_datadir/23301/data/.*
rm -rf /data/ha/kunlun/storage_waldir/23301/redolog/*
rm -rf /data/ha/kunlun/storage_logdir/23301/relay/*
rm -rf /data/ha/kunlun/storage_logdir/23301/binlog/*
- 把完成apply的全备拷贝到对应的数据目录
cd $install_dir/kunlun-node-manager-$version/bin/
示例:
cd /data/ha/kunlun/kunlun-node-manager-1.2.1/bin/
./util/xtrabackup --defaults-file=$install_dir/storage_datadir/$port/$port.cnf --user=agent --pagent_pwd --copy-back --target-dir=$fullbackup_base >> ../log/rebuild_node_tool_37.log 2>&1
示例:
./util/xtrabackup --defaults-file=/data/ha/kunlun/storage_datadir/23301/23301.cnf --user=agent --pagent_pwd --copy-back --target-dir=/data/ha/kunlun/storage_datadir/23301/xtrabackup_tmp >> ../log/rebuild_node_tool_37.log 2>&1
- 删除存放全备目录下的所有文件
rm -rf $fullbackup_base/*
rm -rf $fullbackup_base/.rocksdb
示例:
rm -rf /data/ha/backupfile/xtrabackup_base/*
rm -rf /data/ha/backupfile/xtrabackup_base/.rocksdb
- 拷贝配置文件到对应数据目录和启动实例
cp -a $install_dir/storage_datadir/$port/$port.cnf $install_dir/storage_datadir/$port/data/
示例:
cp -a /data/ha/kunlun/storage_datadir/23301/23301.cnf /data/ha/kunlun/storage_datadir/23301/data/
启动mysql示例:
cd $install_dir/instance_binaries/storage/$port/kunlun-storage-$version/dba_tools; ./startmysql.sh $port
示例:
cd /data/ha/kunlun/instance_binaries/storage/23301/kunlun-storage-1.2.1/dba_tools; ./startmysql.sh 23301
- 根据全备信息xtrabackup_info文件中的gtid,重新建立主备关系
全备相关的信息和GTID可以查看xtrabackup_info文件
如图为GTID:
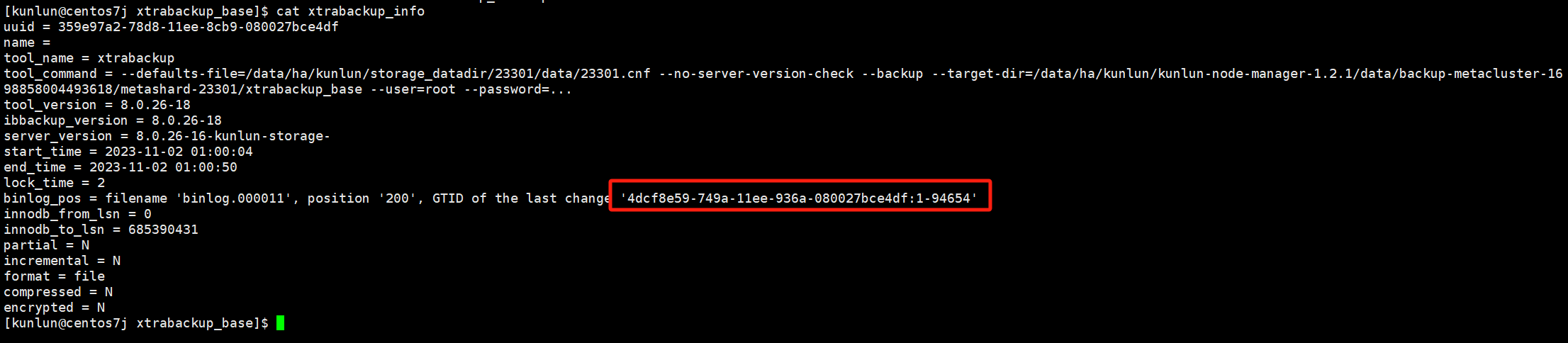
cd $fullbackup_base
cat xtrabackup_info
reset master; set global gtid_purged='$GTID'; stop slave; reset slave all; change master to MASTER_AUTO_POSITION = 1, MASTER_HOST='$master_host' , MASTER_PORT=$master_port, MASTER_USER='repl' , MASTER_PASSWORD='repl_pwd',MASTER_CONNECT_RETRY=1 ,MASTER_RETRY_COUNT=1000, MASTER_DELAY=0, MASTER_HEARTBEAT_PERIOD=10 for CHANNEL 'kunlun_repl'; start slave for CHANNEL 'kunlun_repl';
# $GTID 记录在全备目录xtrabackup_info文件
# $master_host 当前集群的主节点ip
# $master_port 当前集群的主节点端口号
示例:
reset master; set global gtid_purged='4dcf8e59-749a-11ee-936a-080027bce4df:1-82129'; stop slave; reset slave all; change master to MASTER_AUTO_POSITION = 1, MASTER_HOST='192.168.0.150' , MASTER_PORT=23301, MASTER_USER='repl' , MASTER_PASSWORD='repl_pwd',MASTER_CONNECT_RETRY=1 ,MASTER_RETRY_COUNT=1000, MASTER_DELAY=0, MASTER_HEARTBEAT_PERIOD=10 for CHANNEL 'kunlun_repl'; start slave for CHANNEL 'kunlun_repl';
- 验证主备关系是否正常
ps -ef|grep $port
示例:
ps -ef|grep 23301
登录重做完成的备节点进行查看主备关系:
cd $install_dir/instance_binaries/storage/$port/kunlun-storage-$version/dba_tools/
示例:
cd /data/ha/kunlun/instance_binaries/storage/23301/kunlun-storage-1.2.1/dba_tools/
./imysql.sh $port
示例:
./imysql.sh 23301
show slave status\G
如图:
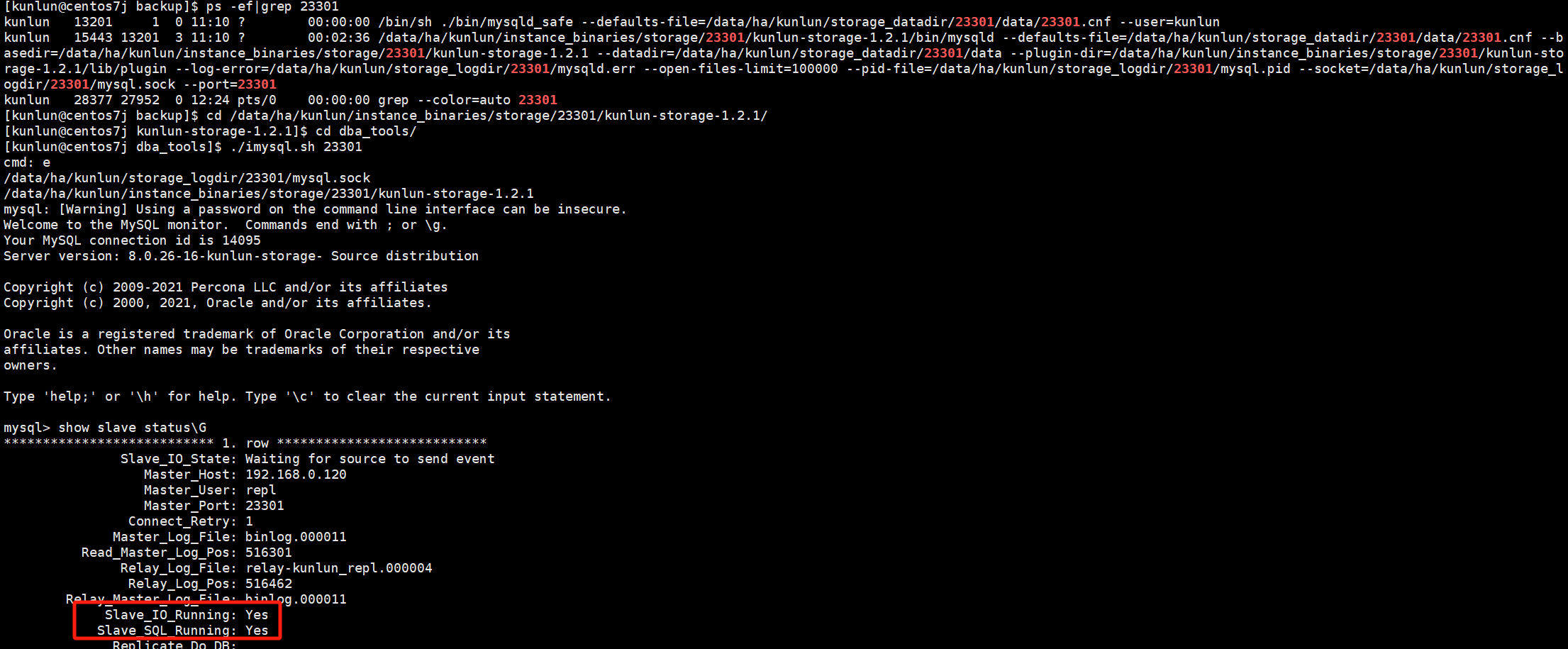
重做备机后,主备关系正常。
08 计算节点访问权限控制
通过修改每个计算节点的pg_hba.conf文件,进行访问权限控制。
操作步骤,每个计算节点操作:
- 修改pg_hba.conf:
查看文件所在目录:
ps -ef|grep $port # $port是指计算节点的端口号
示例:
ps -ef|grep 23001
如图:
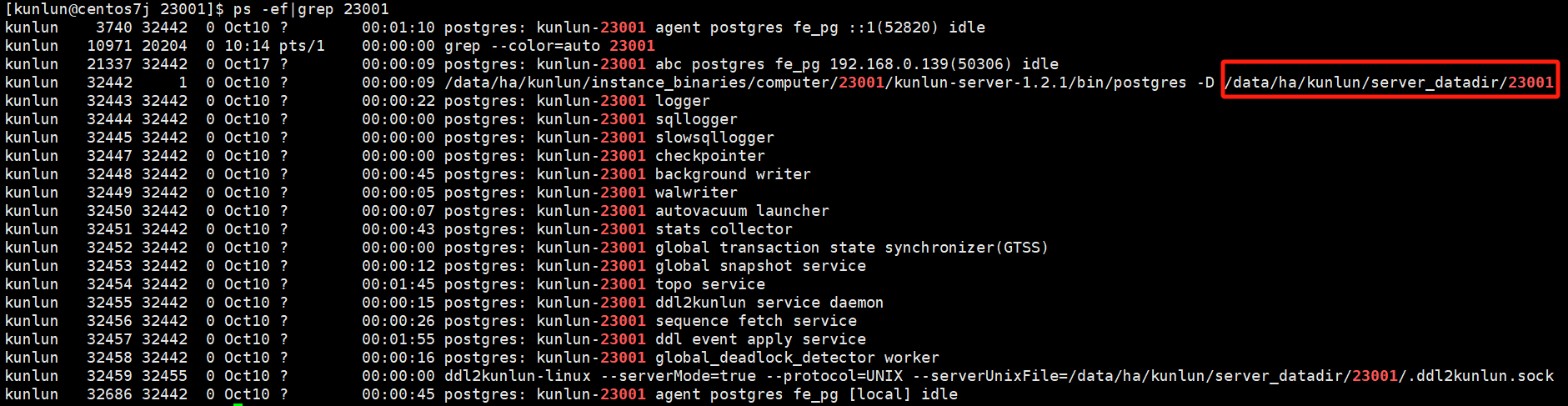
cd /$install_dir/server_datadir/$port
# $install_dir是指计算节点安装目录
# $port是指计算节点端口号
示例:
cd /data/ha/kunlun/server_datadir/23001
如图:
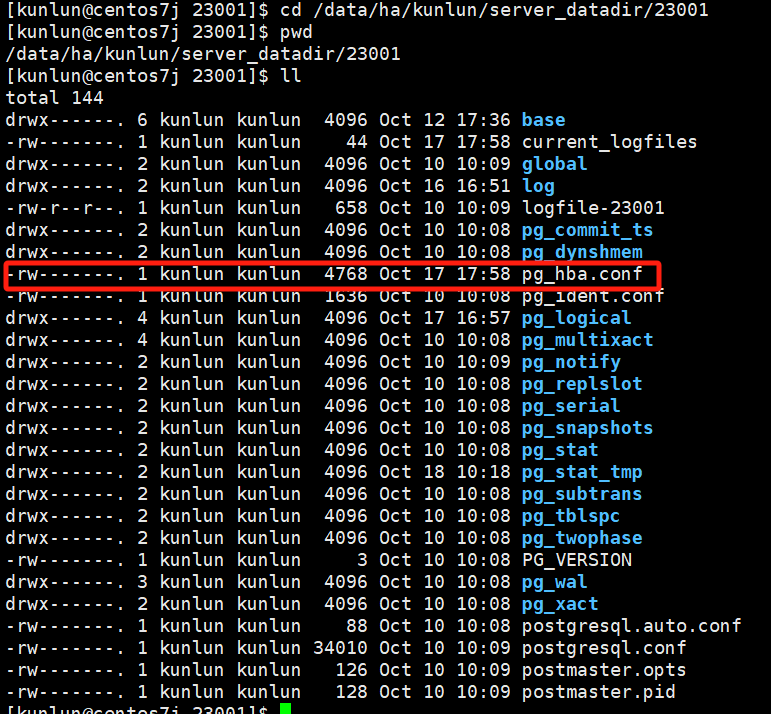
在配置文件的第一行加入如下内容:
host all kunlun_test 192.168.0.139/24 reject
该内容的具体含义是拒绝所有来自192.168.0.139的kunlun_test用户的TCP/IP连接访问。**在前面第一行加入的原因为前面的配置会覆盖后面的配置,如果前面有相关比较大的允许访问权限配置,那么后面即使设置了拒绝也无法生效。**具体的pg_hba.conf文件参数配置介绍见PG官网链接:
https://www.postgresql.org/docs/current/auth-pg-hba-conf.html
如图:
- 使配置生效:
查看kunlun-server进程,确认pg_ctl工具所在目录
这里以kunlun-server的端口号23001为例:
ps -ef|grep 23001
图片示例:

查看pg_ctl所在的目录:
cd /data/ha/kunlun/instance_binaries/computer/23001/kunlun-server-1.2.1/bin
ls -l
图片示例:
执行reload:
./pg_ctl -D /data/ha/kunlun/server_datadir/23001 reload
图片示例:

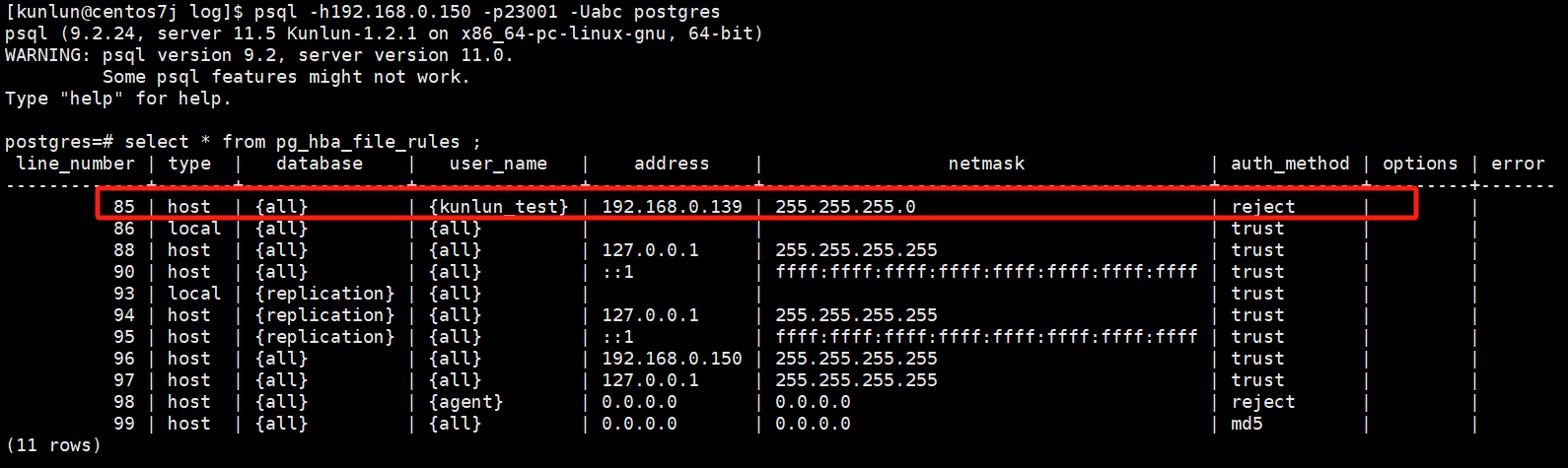
验证生效:
登录计算节点:
psql -h192.168.0.150 -p23001 -Uabc postgres
执行sql:
select * from pg_hba_file_rules ;
- 登录验证
192.168.0.139机器上执行登录:

登录失败,报错信息描述pg_hba.conf配置文件拒绝了连接。
09 手动配置cgroup实现CPU硬隔离
cgroup实现CPU硬隔离在创建集群会自动执行,不需要手动设置,这里只是说明如需故障排查或者其他问题需要设置cgroup****时,操作使用说明。
- 存储节点
执行命令:
到kunlun2cgroup工具目录下,该工具在node_mgr的bin/util目录下:
cd $base_dir/kunlun-node-manager-1.2.1/bin/util
# $base_dir是指安装基础目录,可以在部署时的拓扑文件.json中查看。
示例:
cd /data/ha/kunlun/kunlun-node-manager-1.2.1/bin/util
如图:
cgroup2kunlun工具参数解析:
Usage of ./cgroup2kunlun:
-action string
'add' or 'delete' cgroup related to the port
-control_mode string
resource control type, share or quota (default "quota")
-cpu_nums int
cpu resources reserving account, 1 means one cpu cores (default 1)
-pidFile string
instance pid file path
-port string
instance port
-resource_type string
resource controller type (default "cpu")
添加cgroup命令,示例:
./cgroup2kunlun -resource_type=cpu -port=33503 -cpu_nums=8 -control_mode=quota -pidFile=/data/ha/kunlun/storage_logdir/33503/mysql.pid -action=add
resource_type 参数为资源控制类型,默认为cpu
port参数为存储节点端口号
cpu_nums 参数为存储节点使用的vCPU核数
control_mode 参数为控制模式,默认为独占限制
pidFile 参数为存储节点mysql.pid文件的绝对路径
action 参数为配置cgroup的行为,分为add添加和delete删除
示例:
添加存储节点33503端口,8vCPU的限制:
./cgroup2kunlun -resource_type=cpu -port=33503 -cpu_nums=8 -control_mode=quota -pidFile=/data/ha/kunlun/storage_logdir/33503/mysql.pid -action=add
删除cgroup配置:
./cgroup2kunlun -resource_type=cpu -port=33503 -cpu_nums=8 -control_mode=quota -pidFile=/data/ha/kunlun/storage_logdir/33503/mysql.pid -action=delete
- 计算节点
示例:
添加计算节点23001端口,8vCPU的限制:
./util/cgroup2kunlun -resource_type=cpu -port=23001 -cpu_nums=8 -control_mode=quota -pidFile=/data/ha/kunlun/server_datadir/23001/postmaster.pid -action=add
删除cgroup配置:
./util/cgroup2kunlun -resource_type=cpu -port=23001 -cpu_nums=8 -control_mode=quota -pidFile=/data/ha/kunlun/server_datadir/23001/postmaster.pid -action=delete
10 扩展管理extension
extension管理
- 计算节点添加扩展(注意:集群只有一个计算节点时!!!)
以添加uuid-ossp扩展为例
安装相关依赖
sudo yum install -y e2fsprogs-devel uuid-devel libuuid-devel zlib-devel zlib-static
下载pg11.2版本进行源码编译
wget https://ftp.postgresql.org/pub/source/v11.20/postgresql-11.20.tar.gz
Tips:如果wget命令下载速度过慢,可以尝试用电脑访问下载后传到服务器上。
解压后编译
Tar xf postgresql-11.20.tar.gz
cd postgresql-11.20
./configure --prefix=/opt/pgsql11.2 --with-uuid=ossp
执行后结果如下图,无报错:
sudo make
执行命令后如图:
sudo make install
执行命令后如图:
将编译好的扩展相关文件拷贝到对应的目录
cd postgresql-11.20 && sudo chown kunlun:kunlun -R *
cd postgresql-11.20/contrib/uuid-ossp/
cp -a uuid-ossp.so /data/ha/kunlun/instance_binaries/computer/23001/kunlun-server-1.2.1/lib/postgresql/
cp -a uuid-ossp--1.0--1.1.sql uuid-ossp--1.1.sql uuid-ossp--unpackaged--1.0.sql uuid-ossp.control /data/ha/kunlun/instance_binaries/computer/23001/kunlun-server-1.2.1/share/postgresql/extension/
目录介绍:
/data/ha/kunlun为**$base_dir**是指安装基础目录,可以在部署时的拓扑文件.json中查看。
23001为计算节点端口号,以实际的为准。
kunlun-server-1.2.1为计算节点安装的目录,一般以kunlun-server-版本号定义。
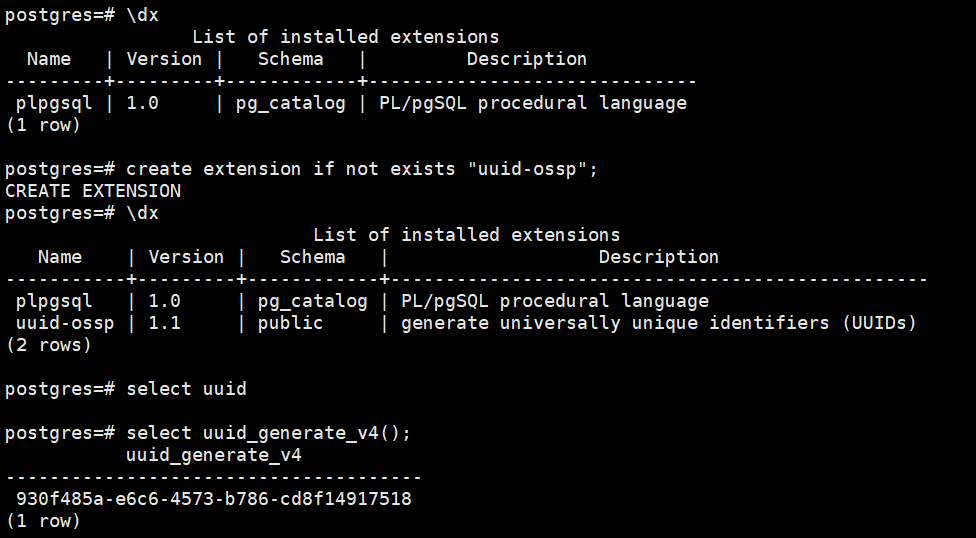
登录计算节点后创建uuid-ossp扩展
先查看已经存在的扩展
\dx
create extension if not exists "uuid-ossp";
\dx
select uuid_generate_v4();
如图所示:
- 计算节点添加扩展(注意:集群有多个计算节点时!!!)
同集群内其他计算节点添加扩展,需要yum安装所需依赖
sudo yum install -y e2fsprogs-devel uuid-devel libuuid-devel zlib-devel zlib-static
省去编译步骤,见单个计算节点的步骤进行操作。
然后在所有的计算节点上将编译好的扩展文件拷贝到对应的目录。
例如本实例中uuid-ossp扩展,只需要编译好的
uuid-ossp.so文件拷贝到**/data/ha/kunlun**/instance_binaries/computer/23001/kunlun-server-1.2.1/lib/postgresql/目录下;
uuid-ossp--1.0--1.1.sql、uuid-ossp--1.1.sql、uuid-ossp--unpackaged--1.0.sql、uuid-ossp.control这四个文件拷贝到**/data/ha/kunlun**/instance_binaries/computer/23001/kunlun-server-1.2.1/share/postgresql/extension/
最后在一个计算节点上进行操作加载extension即可,其他的计算节点就可以看到对应的extension。
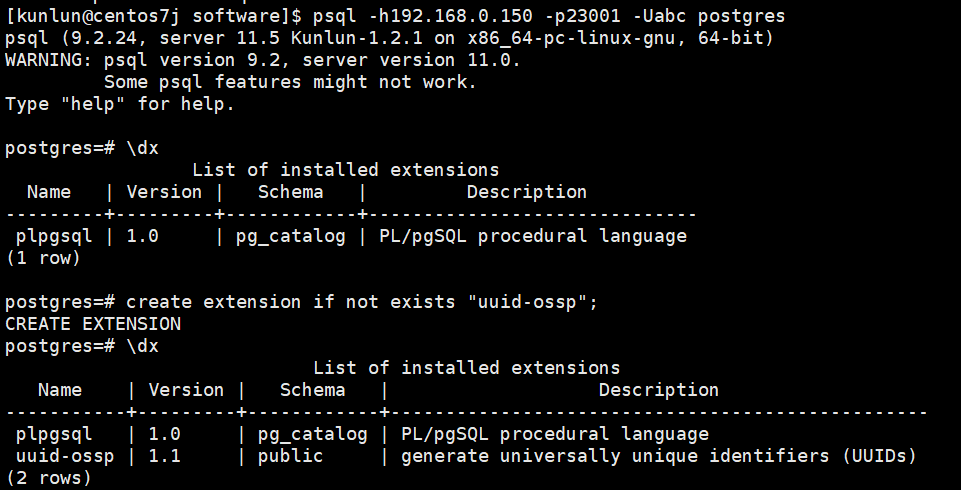
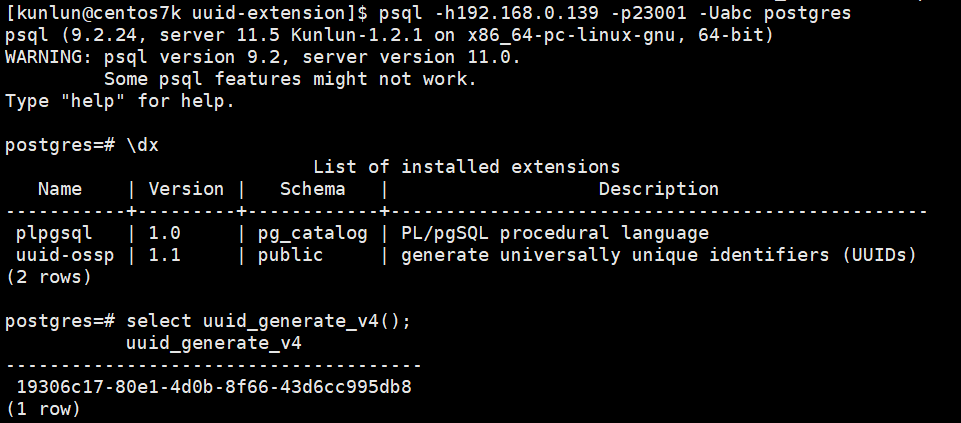
登录计算节点后创建uuid-ossp扩展
先查看已经存在的扩展
\dx
create extension if not exists "uuid-ossp";
\dx
select uuid_generate_v4();
如图所示:
计算节点1:
计算节点2:
- 将扩展文件添加到公共目录
为了往后新增计算节点或者创建新集群,不需要重复操作添加扩展,先在各个计划新增计算机器节点上安装依赖
sudo yum install -y e2fsprogs-devel uuid-devel libuuid-devel zlib-devel zlib-static
然后将扩展文件拷贝到对应的公共目录即可。
cd postgresql-11.20/contrib/uuid-ossp/
cp -a uuid-ossp.so $base_dir/program_binaries/kunlun-server-1.2.1/lib/postgresql/
cp -a uuid-ossp--1.0--1.1.sql uuid-ossp--1.1.sql uuid-ossp--unpackaged--1.0.sql uuid-ossp.control $base_dir/program_binaries/kunlun-server-1.2.1/share/postgresql/extension/
XPanel发起新增机器节点或者创建集群即可看到扩展。
Postgres_fdw扩展使用
postgres_fdw扩展为postgesql提供,无须手动下载后安装,直接加载extension即可。关于postgres_fdw介绍及操作示例可以先参考官网链接:http://postgres.cn/docs/11/postgres-fdw.html,了解后再进行操作。
环境介绍:
- 外部server和表等相关信息:
- host:192.168.0.150
- post:23007
- user:abc
- password:省略
- db_name:klustron,
- schema_name:public,
- table_name:k1。
内部映射相关信息:
- server:foreign_server
- 用户映射:abc
- 映射表:foreign_table1
如下为实际的操作步骤:
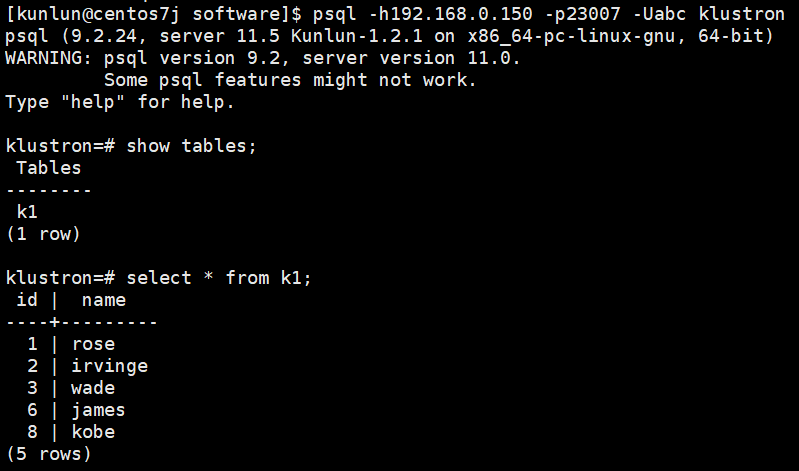
- 外部表k1信息
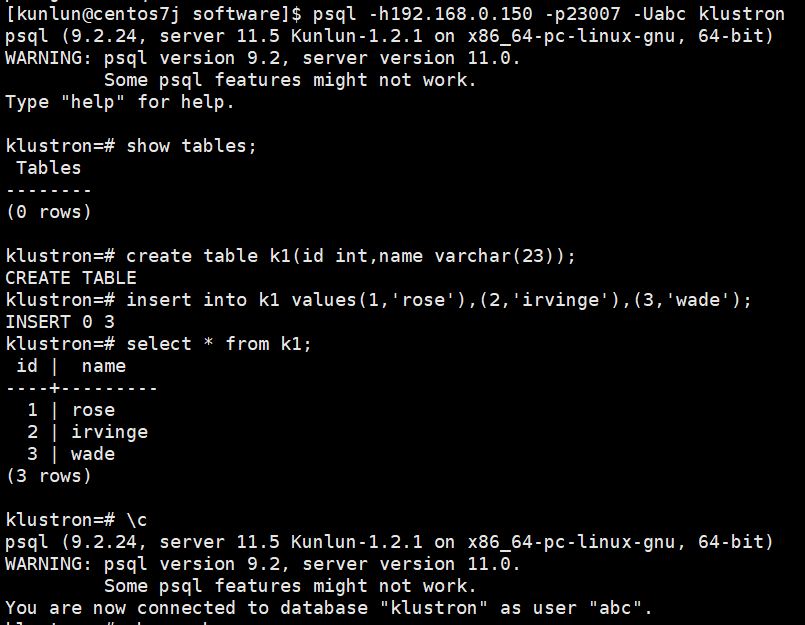
- 内部映射等配置相关操作
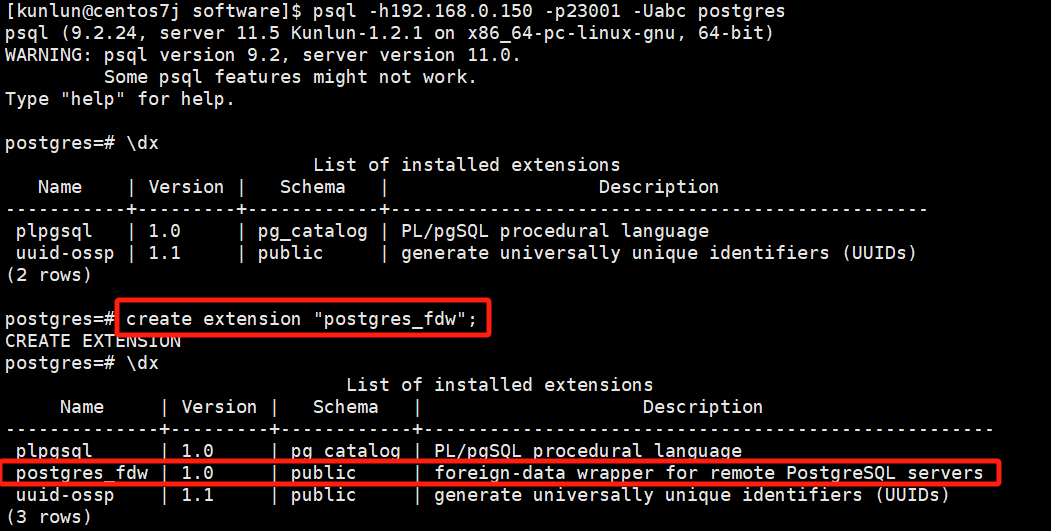
1)创建extension
\dx
create extension "postgres_fdw";
\dx
如图:
2)create server,create mapping,create foreign table
create server foreign_server foreign data wrapper postgres_fdw options(host '192.168.0.150',port '23007',dbname 'klustron');
create user mapping for user server foreign_server options(user 'abc', password 'abc');
create foreign table foreign_table1(id int,name varchar(23)) server foreign_server options(schema_name 'public',table_name 'k1');
如图:



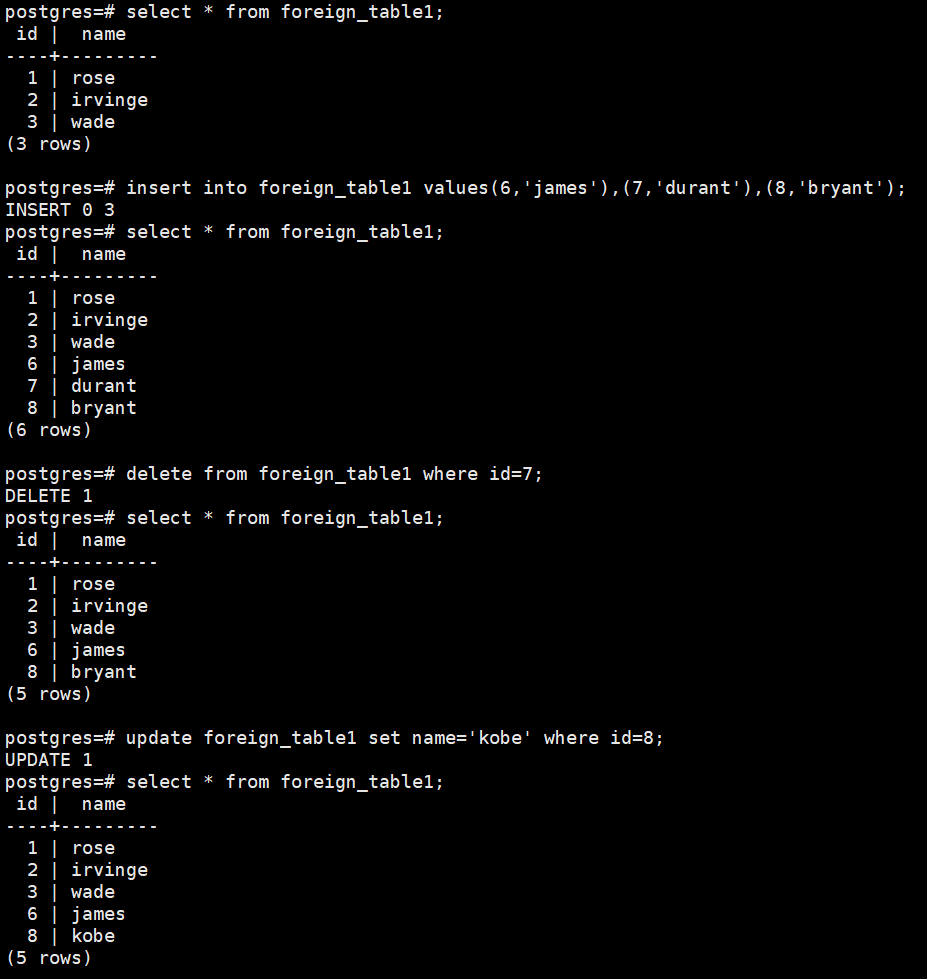
3)验证和操作外部表
select * from foreign_table1;
insert into foreign_table1 values(6,'james'),(7,'durant'),(8,'bryant');
select * from foreign_table1;
delete from foreign_table1 where id=7;
select * from foreign_table1;
update foreign_table1 set name='kobe' where id=8;
select * from foreign_table1;
如图:
外部表登录验证:
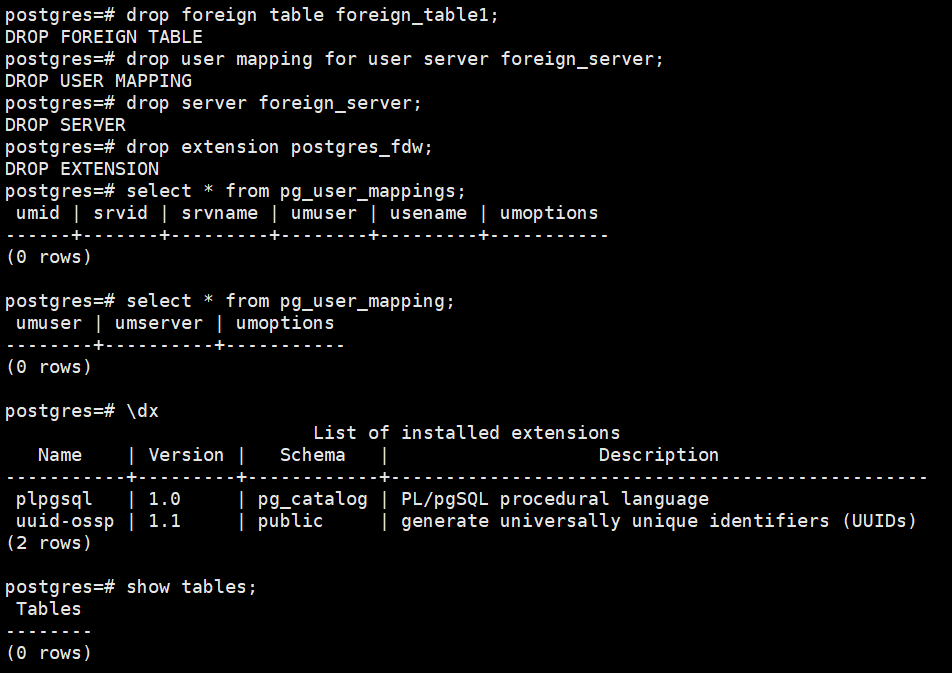
清理环境:
drop foreign table foreign_table1;
drop user mapping for user server foreign_server;
drop server foreign_server;
drop extension postgres_fdw;
select * from pg_user_mappings;
select * from pg_user_mapping;
\dx
show tables;
如图:
11 SSL认证
单向开启SSL
环境准备:
yum install -y openssl-devel openssl perl-ExtUtils*
未开启SSL前,登录计算节点没有SSL的信息:
开启后SSL后,登录计算节点有SSL信息:
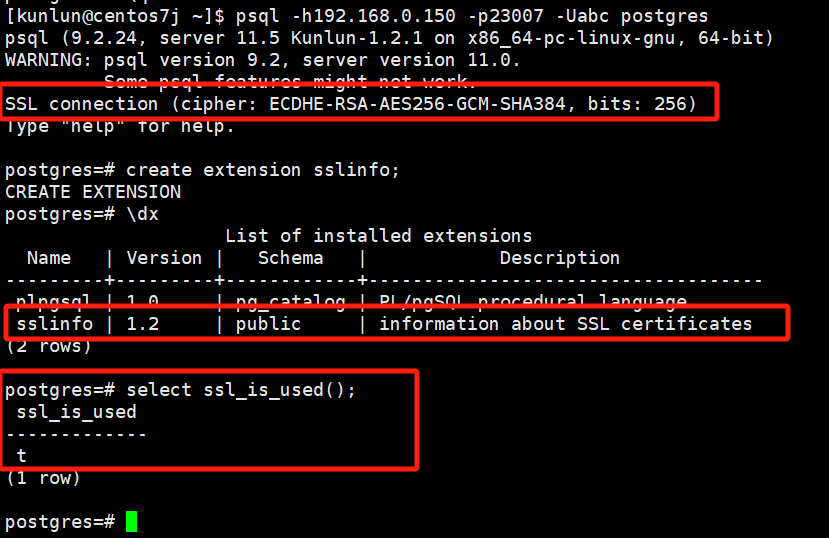
开启步骤如下:
- 生成证书和私钥文件
mkdir openssl
cd openssl/
openssl req -new -x509 -days 365 -nodes -text -out server.crt -keyout server.key -subj "/CN=centos7j"
# /CN=后跟主机名,可以使用hostname命令得出
修改server.key文件权限
chmod 600 server.key
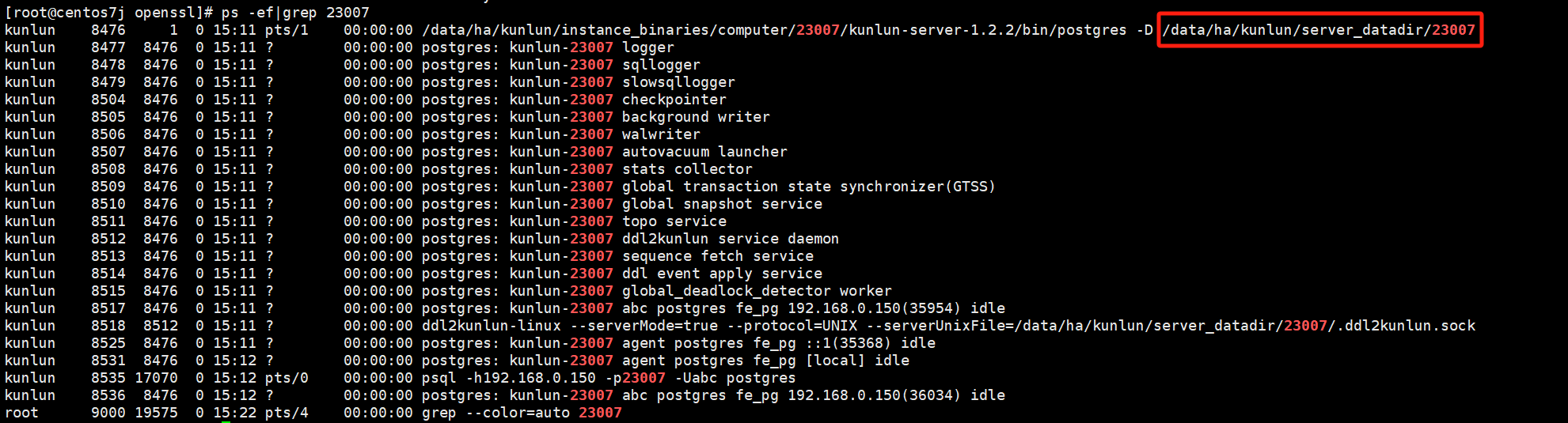
拷贝到对应目录下,这里以计算节点的23007端口号为例:
cp -a server.* /data/ha/kunlun/server_datadir/23007/ #具体目录以实际为准,可执行ps -ef|grep $port $port代表计算节点端口号。
- 修改配置文件
vim postgresql.conf
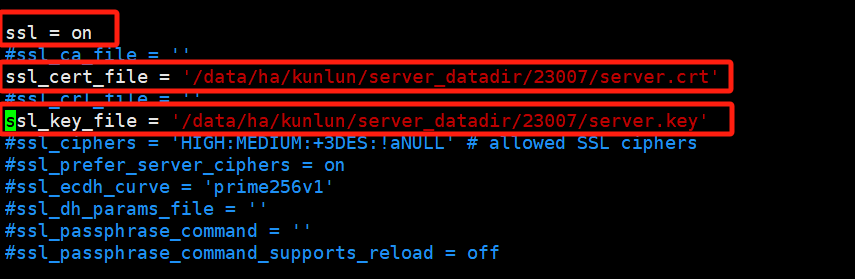
根据具体的文件绝对路径填写,ssl_cert_file和ssl_key_file,并开启ssl。
- 重启计算节点
查看计算节点进程:
ps -ef|grep $port # $port是指计算节点的端口号
示例:
ps -ef|grep 23007
到计算节点的安装目录中与bin目录同级的scripts目录下:
cd /$install_dir/instance_binaries/computer/$port/kunlun-server-$version/scripts
# $install_dir是指计算节点安装目录
# $port是指计算节点端口号
# $version 是指计算节点的版本号,例如:1.2.2
示例:
cd /data/ha/kunlun/instance_binaries/computer/23007/kunlun-server-1.2.2/scripts
启动:
python2 start_pg.py --port=$port
示例:
python2 start_pg.py --port=23007
停止:
python2 stop_pg.py --port=$port
示例:
python2 stop_pg.py --port=23007
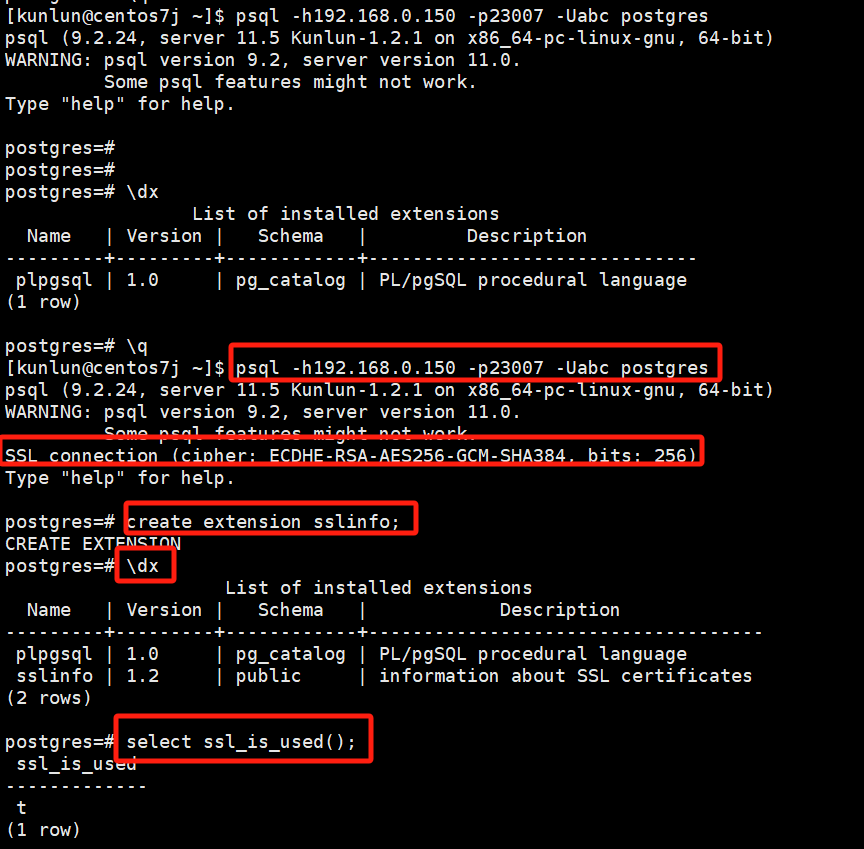
登录计算节点创建sslinfo扩展和验证
psql -h192.168.0.150 -p23007 -Uabc postgres
create extension sslinfo;
\dx
select ssl_is_used();
12 冷热数据分离
冷热数据分离是指,将一些业务基本不读或者不常读的表,例如归档表、日志表,移动到配置较低shard中,并用rocksdb引擎来存储。这样做的好处是将腾出更多的可用数据空间给到热数据来存储,加快热数据的查询速率。
操作步骤如下:
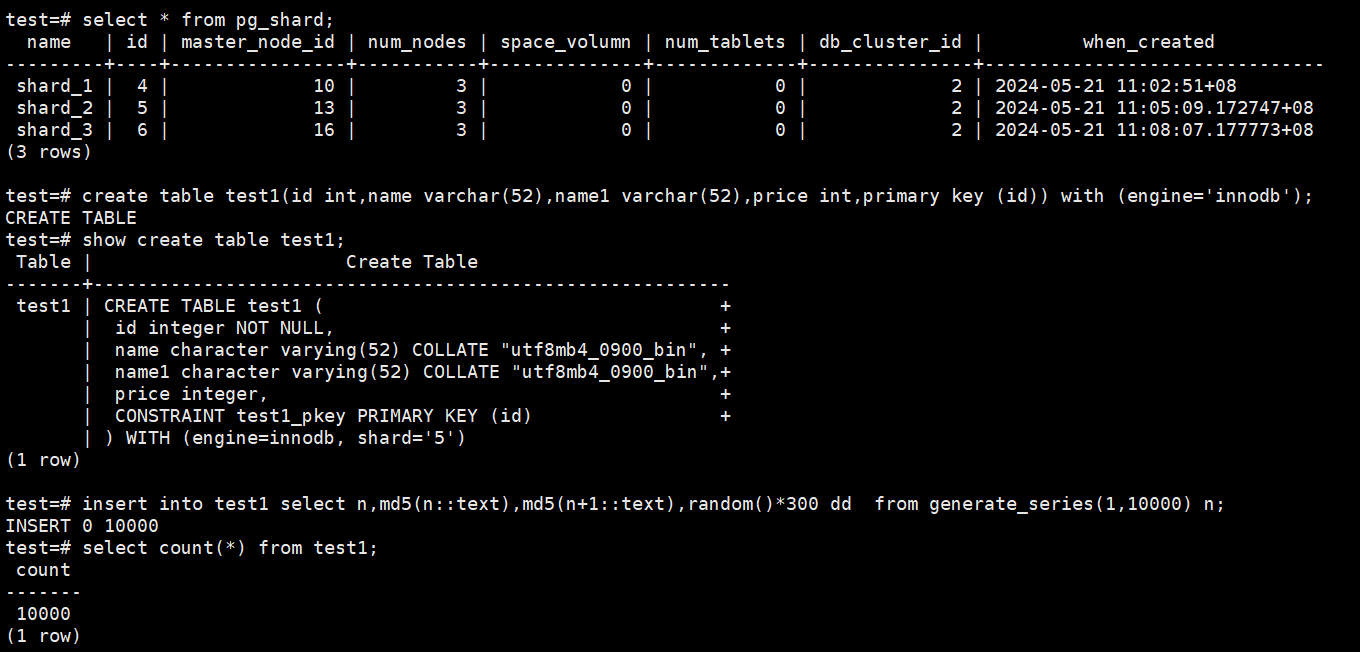
以test1表为例,插入测试数据10000条,
先查看当前集群的shard分布情况,然后创建测试表test1并插入数据:
# select * from pg_shard;
# create table test1(id int,name varchar(52),name1 varchar(52),price int,primary key (id)) with (engine='innodb');
# show create table test1;
# insert into test1 select n,md5(n::text),md5(n+1::text),random()*300 dd from generate_series(1,10000) n;
# select count(*) from test1;
如图:
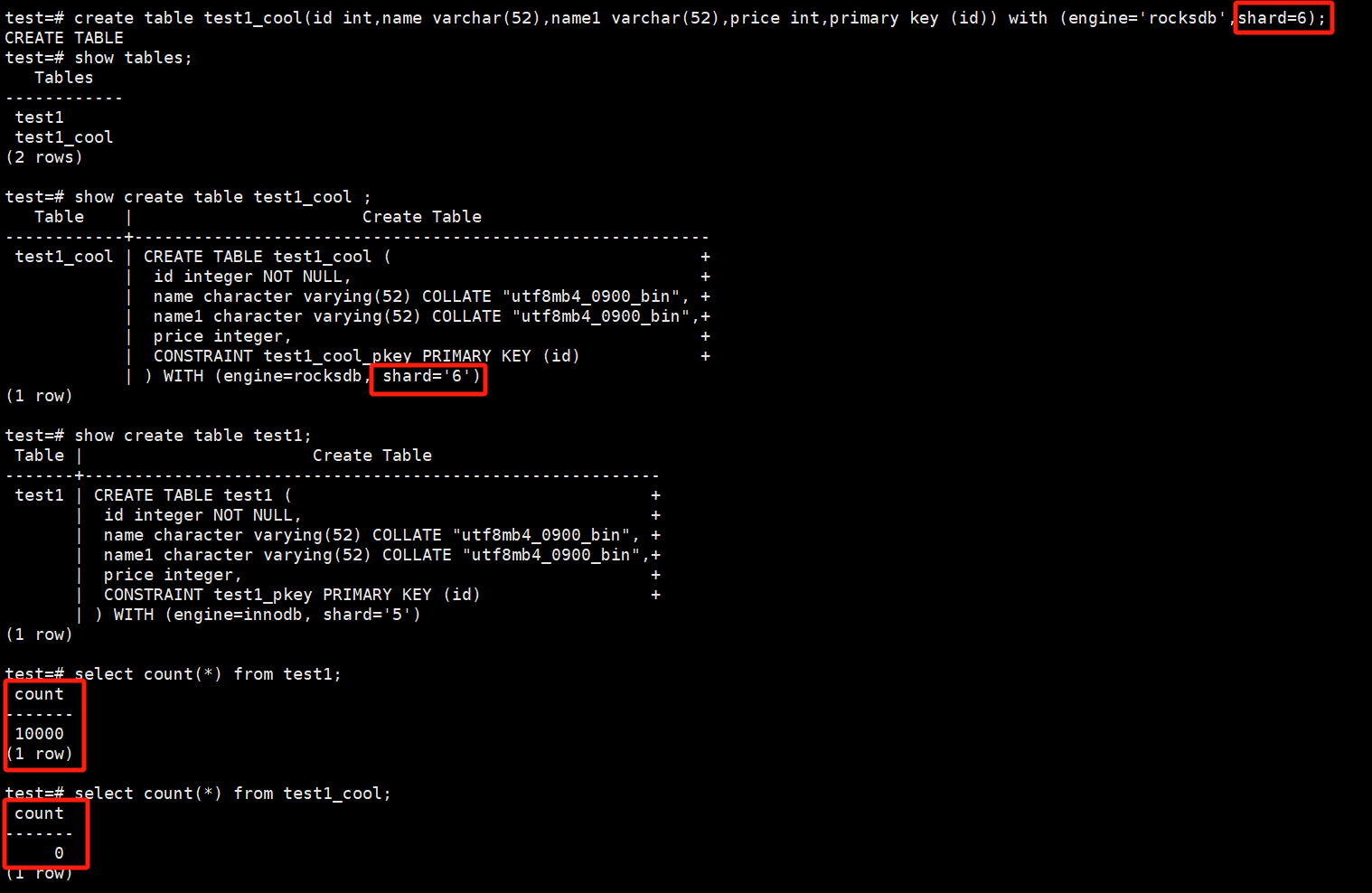
设shard_6为配置较低的冷shard。
创建表test1_cool,表结构与test1一致,但指定存储引擎为rocksdb,shard=6。
# create table test1_cool(id int,name varchar(52),name1 varchar(52),price int,primary key (id)) with (engine='rocksdb',shard=6);
# show tables;
# show create table test1_cool ;
# show create table test1;
# select count(*) from test1;
# select count(*) from test1_cool;
通过XPanel执行表重分布功能,将test1的数据从热shard_5迁移到冷shard_6中。最后将原test1表重命名为其他表名,将迁移数据后的test1_cool表重命名为test1,业务无需在代码上做更,需要注意的是,表重分布的原理为逻辑备份,即将数据从原表导出后,再导入到目标表中,最后重命名原表和目标表,所以需要根据数据量大小,评估变更时间窗口,为变更预留充足的时间。
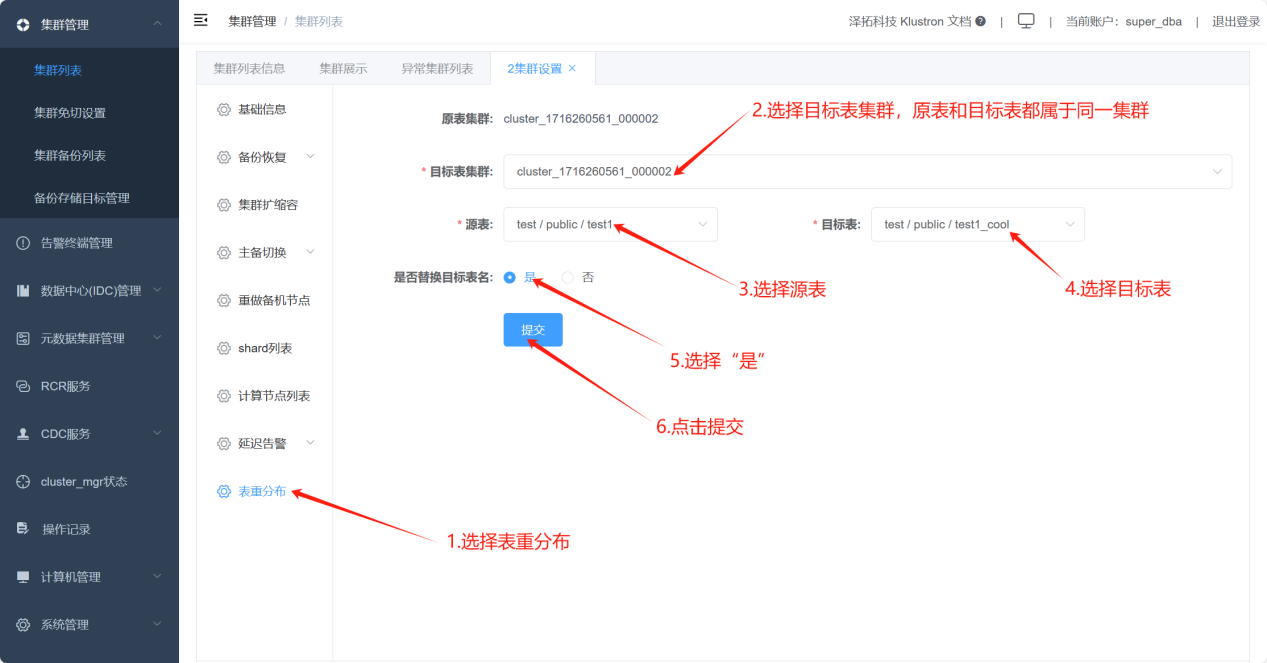
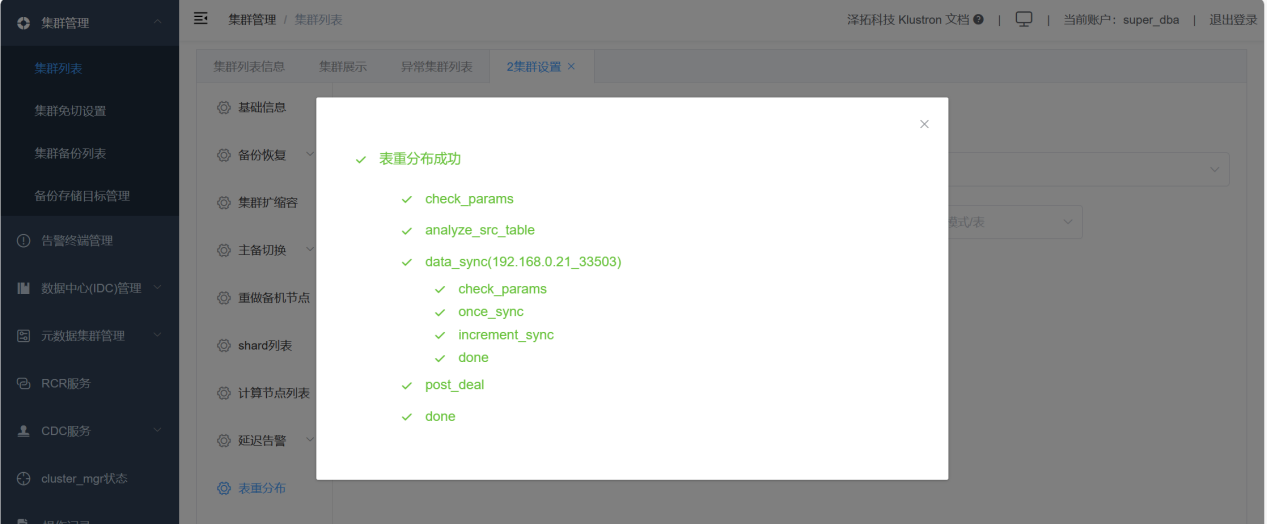
验证迁移是否完成:
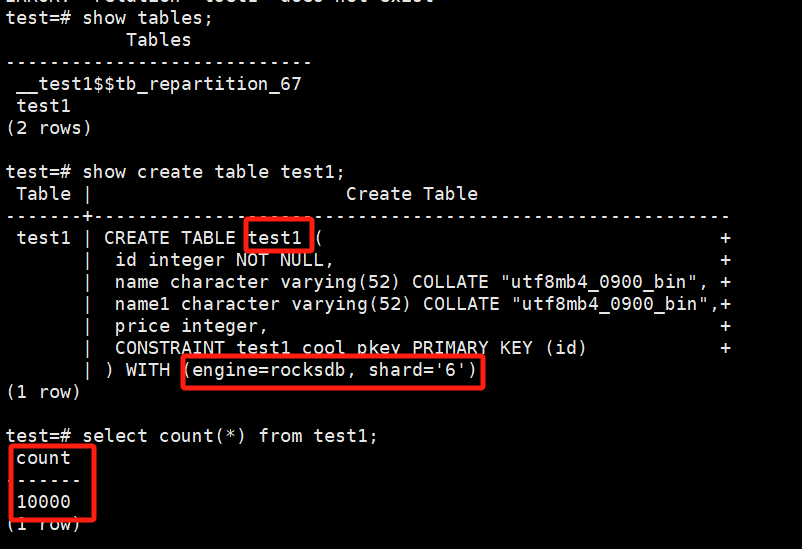
确认迁移完毕。