
HTAP Database Capability Series Sharing: Read-Write Separation
HTAP Database Capability Series Sharing: Read-Write Separation
This issue's golden quote:
Because it has read-write separation capabilities, KlustronDB can completely separate OLTP and OLAP workloads, avoiding resource contention and ensuring that they do not affect each other's performance.
01 Why is read-write separation necessary?
After the database has horizontal scalability, to cope with excessive pressure on a single machine, there are generally two approaches: one is sharding, and the other is read-write separation.
Horizontal sharding is the process of distributing data across multiple database instances according to certain rules, and applications route to the corresponding shard when accessing the data based on the rules.
Read-write separation involves allowing the slave database to handle some business read requests in a master-slave architecture of one master and N slaves.
Both of these schemes have their advantages. After sharding, each shard can be read and written independently, and the system's write capability is also improved; only accessing the primary database of each shard also avoids having to consider the issue of master-slave replication delay.
The disadvantage of the sharding scheme is that because data is distributed across multiple shard primary databases, some data access logic becomes more complex, such as certain cross-table join statements. In addition, when scaling a read-write separation scheme, you only need to add more replica databases without changing the primary database data, which is more cost-effective.
Especially in computing-storage separated solutions like AWS Aurora, the cost of adding a read replica is very small, making the difference in implementation costs between these two solutions even more obvious.
The read-write separation scheme needs to take into account the delay of the standby database, so the business needs to be clear about which statements can use the read-write separation strategy. In HTAP scenarios, most of the statements for analytical requirements can accept this level of second-level delay and also consume considerable computing resources. Therefore, the read-write separation feature can be said to be essential for HTAP databases.
The read-write separation scheme must at least be transparent to the business code. For architectures without a middle layer, where the business layer connects directly to the database, a common solution is to use third-party services like Zookeeper to maintain master-slave information, and let the client connection framework handle the logic of read-write separation. For architectures with a middle layer, mature middle layers will have built-in read-write separation capabilities, allowing the business side to access it directly with an ordinary client. In a cloud environment, the second solution is more widely used.
KlustronDB routes requests from the computing layer to the storage layer, and the architecture diagram is as follows:
_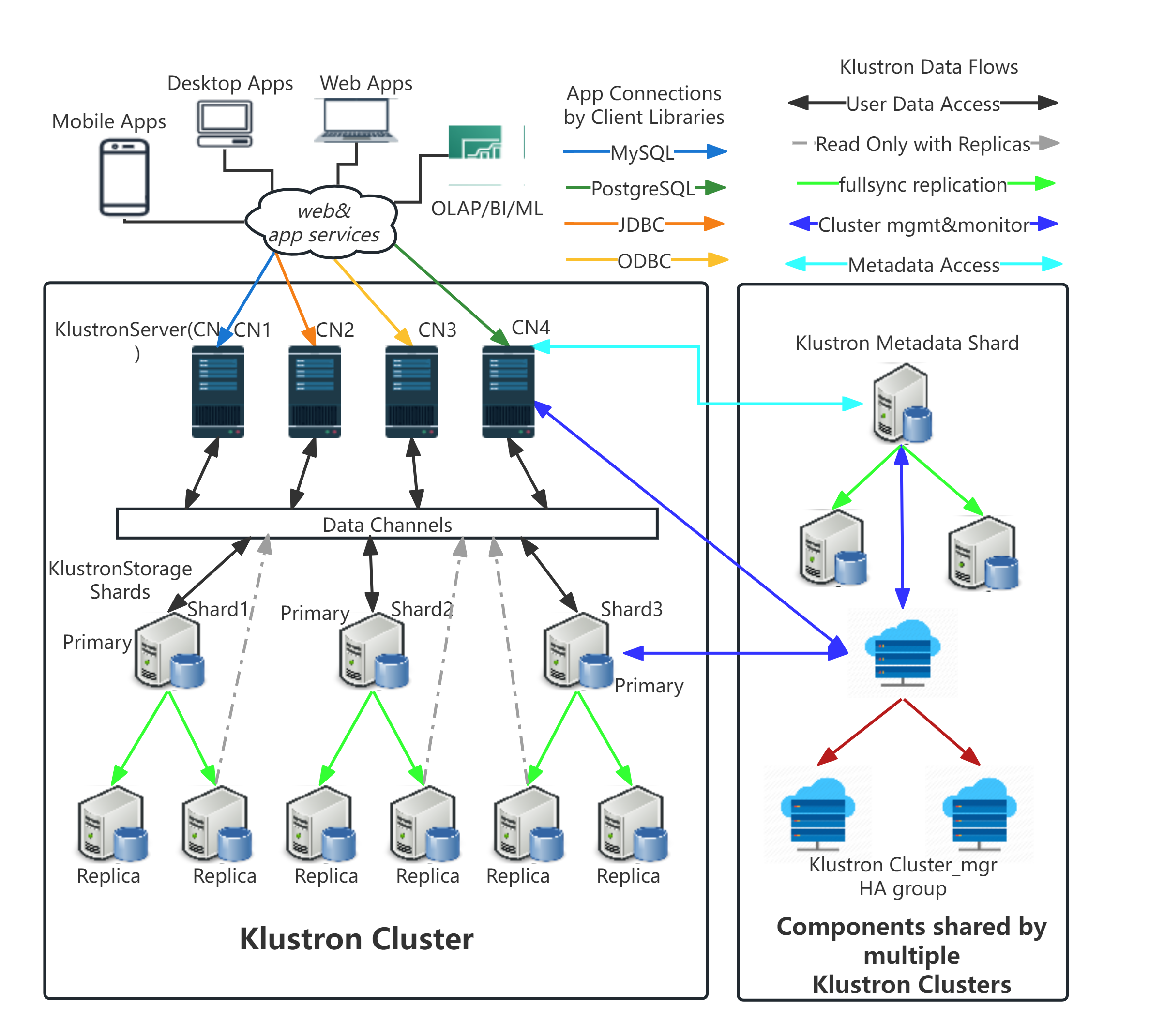
The client can enable the read-write separation feature by executing set enable_replica_read=on;.
02 Issues to Focus on in the Implementation of Read-Write Separation
2.1 Selection Strategy for Slave Databases
When there are multiple slave databases, it is necessary to consider which slave to choose. The general strategy is to select the slave with the smallest delay. Of course, if there are differences in configuration or load among the slaves, different weights can be assigned to the slaves and selection can be made according to the weights when all delays meet the requirements.
In principle, the read-write separation directs write operations to the master database and read operations to the slave database. However, not all read requests can be directed to the slave. For example, within an explicit transaction, if a data row is first updated and then queried, the query must still access the master database because the transaction has not yet been committed and the binlog has not been generated. The slave database will not see this update, so continuing to access the master is the only way to maintain the characteristics of transaction isolation.
The read-write separation strategy of KlustronDB is that when the user's SQL simultaneously meets the following conditions:
- The current SQL type is select;
- User-defined functions in SQL (that is, functions created with the create function statement) are not included, unless the current transaction is read-only;
- If not in a transaction (autocommit=on), read-write separation is allowed; if the statement is in an explicit transaction, the following must be met:
a) If it is a read-only transaction, read-write separation is allowed;
b) If it is in a read/write transaction, then the transaction has not yet updated any data;
The remote query optimizer will deliver the corresponding SQL execution plan to the nodes of the standby machine for execution.
2.2 Primary-Backup Delay
Once you understand the considerations for implementing database read-write separation, it is not difficult to realize that this point must also be taken into account when using it: due to the existence of master-slave delay, read queries routed to the slave database cannot guarantee that the latest data will be retrieved.
This delay is unavoidable, based on MySQL's binlog-based synchronization strategies there are asynchronous replication, semi-synchronous replication, fullsync (by KlustronDB), and transaction strong consistency synchronization.
Transactional strong consistency synchronization refers to the process where a transaction is applied on the replica using the binlog, feedback is sent to the primary database, and the primary then returns a transaction commit success message to the client. This approach sacrifices too much in terms of performance and availability, and is rarely used in production.
For the other three synchronization mechanisms, when the primary database acknowledges the client, it cannot guarantee that the transaction has been replayed on the standby databases.
Therefore, before using read-write separation, the business must be able to know and accept the existence of this delay.
If it is unacceptable, all operations must go to the primary database. According to the rules mentioned above, when using a KlustronDB read-write separation cluster, there are two ways to force operations to the primary database: one is to execute set enable_replica_read=off in a thread to turn off the read-write separation strategy; the other is to send a SQL statement with a write or write lock, after which all queries in that transaction will only access the primary database.
2.3 The 'Bug' of Consistent Read
In the implementation of the read-write separation mechanism, there is also a consistency read 'bug' that is easily overlooked. Let's analyze it in depth.
First, let's review the mechanism of the repeatable-read isolation level.
There is an InnoDB table in the database with two columns (id, c). The id column is the primary key, and there are only two rows of data, with initial values (1,1) and (2,2) respectively. As shown in the figure:

Assume we perform the following sequence of operations without a read-write separation mechanism (add the statement set enable_replica_read=off; at the beginning of session1) so that all subsequent requests for this connection do not follow the read-write separation strategy, that is, they all go to the primary database.
In the third select statement of session1, the value of c in the second row is 2, because the timing of when this transaction was created was before the update statement in session2. Therefore, the version of the row with id=2 that is seen is (2,2). This is consistent with the behavior of the repeatable read isolation level.
If we open the read-write separation strategy and execute this operation sequence again, we can see that the result seen by the third execution of session1 is different, with the value of c for the row with id=2 being 20. As shown in the figure below:

The reason is that after enabling read-write separation, the transaction view of session1 is initially created on the replica. When it reaches the first update statement, the transaction view on the primary database is then created. At this point, in the newly created transaction view, session2 has already updated and committed, so it can see that this value has been changed to 20.
Whether this issue is serious depends on the business's need for the repeatable read isolation level, and it requires evaluation by the business. We will leave the improvement plan for this issue for further discussion at the end of the live session.
03 Q&A Discussion
Discussion Question Q:
After enabling read-write separation, this behavior is inconsistent with the behavior of repeatable-read. How can it be resolved?

Live A:
When a transaction is started on the replica database, a transaction view can also be created on the primary database, which is equivalent to a spatiotemporal transaction. This can solve the problem of repeatable reads.
Discussion Group (@Abu) A:
The key issue is to find a way to filter out the rows newly written by another transaction through readview or similar mechanisms. In fact, this is very similar to the cross-node consistency read problem in distributed databases. There are three solutions:
- In the case where the MySQL of a storage node uses binlog replication, a hidden column is added to each row to store the transaction number. To ensure that this timestamp is consistent across all nodes (including both primary and replica nodes), it might be something like a globally monotonically increasing logical transaction number. Both read-write transactions and read-only transactions need to obtain a global transaction number when starting. At the end of a write transaction, a global transaction number must be obtained, and when the write transaction commits, the commit transaction number must be written to this hidden column. Writing this transaction number to the modified rows during transaction commit has a cost. Read transactions compare the transaction number obtained at the transaction start with the commit transaction number of the row to determine whether the row is visible. The row is visible if the commit transaction number is less than the transaction number at the start of the read transaction. When the update in the figure above is performed after the select, and the transaction switches from a read-only transaction to a read-write transaction, a new transaction is initiated on the primary. At this point, using the transaction number obtained from the read-only transaction on the replica to start a new transaction on the primary, since the transaction number was generated on the replica, the data not readable on the replica cannot be read on the primary either.
- If the primary and standby storage nodes can use redo for replication, the primary database records the beginning and end of transactions in redo, and the standby can construct an active transaction list. The standby can then accept read requests and support MVCC. Since the transaction numbers of the primary and standby are guaranteed to be consistent by redo, the readview of read transactions on the standby can be directly associated with the read-write transactions initiated by the primary. In this way, the data that the primary can read is the data that the standby readview should read plus the data written by the primary's own transactions, so it will not read data written by others.
- If the storage node's primary and standby redo are replicated, and the standby database can accept read requests, it is possible to send all write requests to the primary and all read requests to the standby. In the diagram, the select after the update is still sent to the standby database, except that at this time, the standby's read view needs to know the transaction IDs of the write transactions related to the primary and standby read transactions. This way, as long as the redo LSN applied by the standby exceeds the LSN of the primary's completed update, the standby can read the data of the primary's write transactions, while rows written by other transactions will not be read due to read view filtering.
Teacher Ding Qi (replying to @A Bu) A:
In this reply from classmate Abu, there is an answer that meets expectations, an answer that exceeds expectations, and a proposal that far surpasses expectations. Appreciate these ideas.
- This is the idea of a global transaction ID. This ID can be written in the binlog or generated by the global transaction manager. This solution can also support multiple read nodes working together to achieve read-write separation.
- Redo log replication is the essence of Aurora. This solution is similar in concept to the inter-thread shared readview functionality already implemented in KlustronDB; they have a kindred approach.
- This is the true complete form of read-write separation. Hopefully, future hardware capabilities can reduce the latency to a level where this solution does not affect performance.
Discussion Group (@Abu) A:
Thanks to Teacher Ding Qi for the guidance. Saying it is one thing, but if you want to implement it in a project, there are still many details to consider. In the end, there may be many trade-offs to make. Being able to finally implement it and apply it to business is truly impressive. I look forward to the new features and innovations of Kunlun Database in the future.
Teacher Zhao Wei (replying to @A Bu) A:
We will add support for query result consistency in read-write separation within KlustronDB's global MVCC functionality, although the technical approach is somewhat different from what @阿咘 suggested. Of course, it indeed involves extensive kernel modifications to the Binlog system and InnoDB. We will provide a detailed introduction after the release of version 1.2.
04 Summary
Read-write separation is a technique that separates the read and write operations of a database onto different servers for processing, which can improve the performance and availability of the database system. By assigning read operations to the slave servers, the burden on the primary server can be reduced, enhancing the performance and throughput of the database system.
When HTAP technology is combined with read-write separation, a more efficient, faster, and more economical database processing solution can be achieved. Applying HTAP technology to a read-write separation architecture can meet the requirements for real-time transaction processing and complex analytical processing, and improve database performance and availability through read-write separation technology.