
HTAP Database Capability Series Sharing: Online DDL Capability Exploration
HTAP Database Capability Series Sharing: Online DDL Capability Exploration
1. Preface
Starting this week, our 【Klustron Tech Talk】 series will explore issues related to HTAP databases. The main focus will be on the key technologies of HTAP databases and the selection of corresponding solutions.
2. Is HTAP "Real"?
You may have seen similar discussions in previous community discussions about whether HTAP is a true proposition. First of all, I truly believe it is.
The development trends of the mainstream products in the industry also show that products that used to be strong in TP are expanding their AP capabilities, and vice versa.
Moreover, the HTAP solutions provided by these database vendors are not simply imagined needs by themselves, but rather developed based on many real application scenarios. In other words, these HTAP technology solutions are designed to meet actual business needs.
For some business systems with strong commercial attributes, decision-making depends heavily on the data analysis results of online systems. Previously, data analysis needs could wait for several days or hours to be completed, but now with changes in business requirements, there is an evolved need to complete data analysis within a few minutes.
Another way to phrase it is, can we achieve this need by combining AP and TP systems?
This architecture can solve many problems. Even with HTAP databases, this mixed architecture of AP + TP still has its application scenarios. After all, the analytical capabilities of large-scale AP systems are still undoubtedly irreplaceable.
However, some critical features required by HTAP databases, such as strong transaction consistency, cannot be easily satisfied by hybrid architectures. This means that in addition to having analytical capabilities, the results of analysis queries must also meet the ACID requirements of the database. (We will come to this topic later on in the series where we discuss the key technologies of HTAP databases).
3. What are the Necessary Capabilities for HTAP Databases?
First of all, as a product focused on analytical capabilities, it needs to have the ability to scale horizontally, as a single server obviously cannot meet the demands of analysis.
Meanwhile, it also needs to have comprehensive TP capabilities, which means it should support distributed transaction capabilities.
Analytical queries put a high demand on system performance, so read-write separation is also an essential technology.
With the ability to horizontally scale, it becomes possible to maximize performance under the assumption of sufficient resources. This paves the way for the capability of parallel queries.
Therefore, distributed transactions, horizontal scaling, read-write separation, and parallel queries are essential capabilities of an HTAP system, and there are some bonus capabilities that we will discuss in more detail in the upcoming series. Another challenge for HTAP databases is online DDL capability, which was initially raised and evolved in the centralized database scenario.
3.1 Online DDL Capability
After all, online businesses expect the database to work continuously 24/7, and table structure changes can be considered as routine operations that will inevitably happen. The most common requirements are adding fields, adding indexes, and changing field properties.
In the past, adding fields used to lock the table, and we occasionally heard such experiences from senior developers, which is clearly a painful memory. For example, when designing the table structure, leave a reserved field, and if reserved1 is not enough, add up to reservedN.
The solutions provided by database products and communities are also iterating and evolving.
Online DDL is required because DDL operations often involve redoing the entire table, which can take a long time for large tables.
In addition, DDL locks the table, making it impossible to perform write operations, which can significantly impact business operations.
In the earliest version of MySQL, even changing a field name required locking the entire table, which lasted for a long time. During this period, the community came up with solutions.
Subsequently, in MySQL 5.x and later versions, significant improvements were made to the DDL experience. For example, although adding a field still requires redoing the data, the table can be read and written to normally during most of the data redoing process. Only a short table lock operation occurs during the final stage of statement execution, greatly improving the user experience.
In HTAP database scenarios, there is a type of DML operation that involves manipulating a large amount of data, which is data redistribution.
For example, during the scale-out operation, as the project's data volume increases, additional servers may be required. This requires the original data to be redistributed to the cluster according to the new distribution rules. Ideally, this operation should be performed online to avoid disruption to the business.
Besides official version iterations, other branches in the community have also made improvements to Online DDL. For example, including MariaDB, many versions now support adding columns in seconds by simply changing metadata information, without even redoing data.
This capability is quite valuable as DBAs know that adding columns and indexes is one of the most common changes to table structure.
Of course, most DDL still needs to rebuild data.
In the community ecosystem, Percona's OSC was one of the first tools to implement Online DDL operations.
Let's first introduce a general OSC (Online Schema Change) process. Suppose that you want to change a varchar field to a text type in Table A. To do this, you need to create a temporary Table B with the desired DDL table structure, which starts as an empty table:
Full migration: Copy all data on Table A to Table B;
Incremental migration: During step 1, there will be new changes on Table A, which are referred to as incremental data sets. After the full migration is completed, the incremental updates made to table A during this stage need to be applied to table B as well.
At this stage, Percona OSC uses MySQL's trigger mechanism to record the updates on Table A during incremental migration to a temporary table before incremental migration starts. Then apply the records in the temporary table to Table B.
There is another way to handle incremental migration based on parsing binlog, such as the tool gh-ost.
The trigger solution is superior to the binlog solution in that it does not depend on row base binlog, but because triggers need to be created on the original table, there will be conflicts if triggers are already used in the business itself.
In addition, MySQL triggers also have some occasional unsolved bugs, so the trigger-based solutions are considered too heavy, and binlog-based solutions like gh-ost are more commonly used.
3. Klustron Online DDL Capability
The Online DDL solution of Klustron is also based on parsing binlog to complete incremental migration.
The core components include mydumper, Kunlun-loader and binlog2sync. (As shown below.)
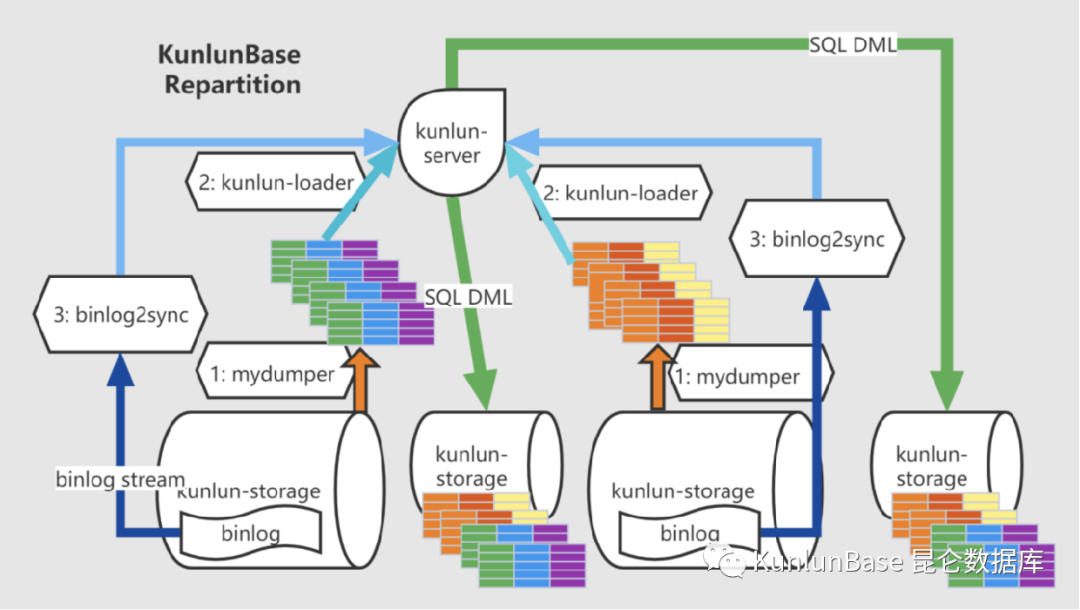
After binlog2sync parses the binlog of the source table, it constructs SQL statements according to the new table structure and sends them to the KunlunSever computing node, which distributes them to the corresponding storage nodes for execution. It can be seen that for sharded tables, this process implements data resharding by default. This means that if the application upgrade requires data resharding, this Online DDL function can be used.
Please refer to the official documentation for detailed information and case studies: http://doc.klustron.com/repartition.html
4. Q&A
Q1: Is the lock time of this Online DDL random or controllable?
A: This is a good question, and whoever asked it seems to have learned a painful lesson. After the incremental migration is completed, a short lock operation is required to exchange the table name between the temporary table and the source table.
From the perspective of the execution time of the product task, the table should be locked as soon as the migration is completed; from the perspective of being friendly to the production environment, since the table can still serve online during the incremental migration, the operation of locking and renaming the table name should ideally be scheduled within a specified time window to minimize the impact on the business. Klustron's Online DDL can specify the switching time period.
Q2: If the write load of the source table is very high, will it cause the speed of chasing binlog to be slower than the speed of generating binlog?
A: This is possible, especially if the table to be DDL is the most frequently updated table in this library. Then the system will have twice the writing pressure during the incremental migration.
In fact, if the tool is advanced enough, it should control the write speed of the Online DDL thread to prioritize ensuring that business is not affected. Klustron's Online DDL process allows users to specify the amount of binlog logs applied during the incremental process to achieve speed limiting. Fortunately, there is no lock operation on the source table during execution, which is also the advantage of the Online solution.