
Instant DDL in MySQL 8.0
Instant DDL in MySQL 8.0
This Issue's Golden Quote:
Instant DDL in MySQL 8.0 is one of the very important features of this version. It achieves instant completion of some DDLs by only updating the data dictionary, greatly improving the execution performance of DDL.
The instant DDL feature of MySQL 8.0 is a very distinctive function of this version. It significantly improves the execution efficiency of certain DDL operations by only modifying the data dictionary, achieving instant execution of DDL actions such as adding or dropping columns. This presentation will mainly introduce the principles and implementation methods of instant DDL, as well as new features developed by KlustronDB based on it, with the hope that attendees will gain an understanding of this key feature and also have a deeper understanding of Klustron.
01 Introduction to MySQL DDL
First, let's briefly review the entire development history of MySQL DDL.
- Before MySQL 5.5, only Copy-based DDL operations were supported, which required copying data and could not allow concurrent writes to the table being altered.
- Starting from MySQL 5.5, Inplace DDL operations are supported. For DDL operations that support inplace, there is no need to copy data, and changes can be made directly on the existing table data, but concurrent writes are still not allowed.
- Starting from MySQL 5.6, Online DDL is supported, allowing most DDL operations to be performed while concurrent reads and writes continue, greatly reducing the overall impact of DDL operations on the system;
- MySQL 8.0 began supporting instant DDL, allowing DDL operations to be completed instantly by only modifying the data dictionary without modifying the data.

02 Detailed Explanation of MySQL Instant DDL Features
Why?
The main reasons for needing to implement Instant DDL are as follows:
- The DDL execution process for large tables is too long, especially in replication scenarios;
- Executing some DDL requires multiple times the disk space.
- Some DDL execution processes can consume a large amount of IO, memory, and CPU resources.
- In a replication scenario, executing DDL on the replica takes a long time to synchronize with the primary.
The following is the execution process of an Online DDL: (Online DDL flowchart: image from Tencent Cloud MaYuan Technology column)
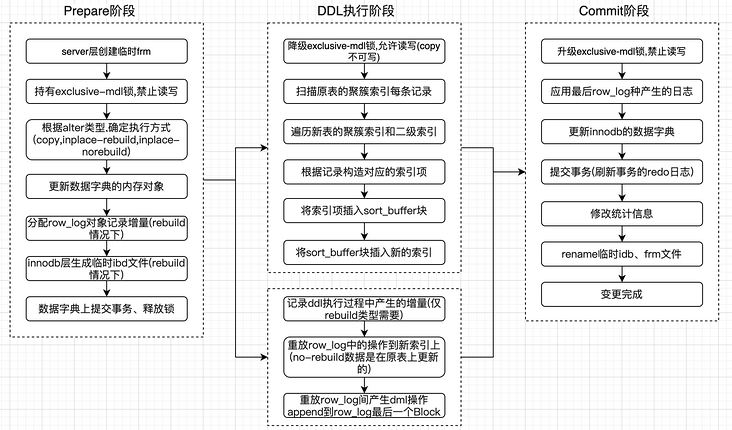
From the above diagram, we can see that before MySQL 8.0, the execution of a DDL required three stages, which involved creating a new table, importing data into the new table, and finally switching between the old and new tables, among other relatively complex processes. This not only made the process complicated but also required a large amount of disk, memory, and CPU resources, resulting in low DDL execution efficiency and potentially affecting the normal operation of the entire system.
Therefore, we need a new method to perform DDL, so that it can be both fast and efficient.
The Principle of Instant DDL:
The basic principles of Instant DDL mainly include the following points:
- Only modify the data dictionary information, without copying or modifying any historical data;
- Determine whether a data row is in the new or old format by adding and setting flag bits;
- After MySQL 8.0.29, the structure corresponding to a data row is determined by setting the version number of the data row.
- Only modify the data dictionary information, without copying or modifying any historical data;
- Determine whether a data row is in the new or old format by adding and setting flag bits;
- After MySQL 8.0.29, the structure corresponding to a data row is determined by setting the version number of the data row.
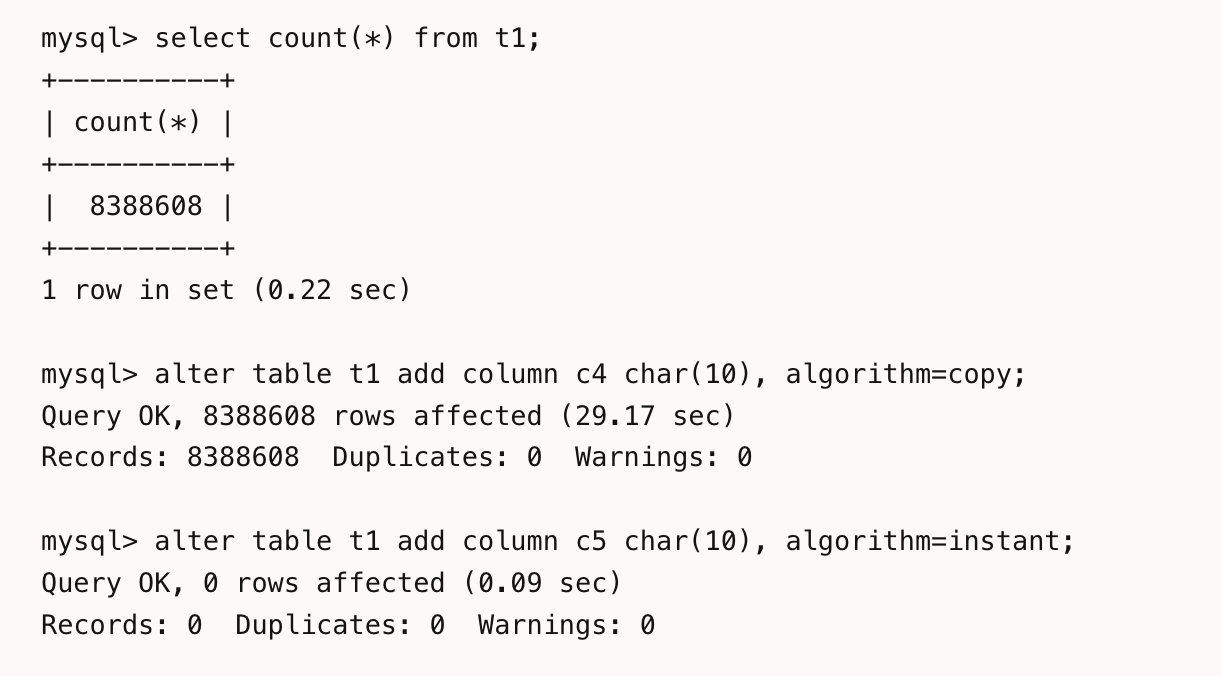
The above image compares the execution of DDL between the Instant method and the copy method. We can see that executing the add column operation with the Instant method only took 0.09 seconds, while the copy method took 29.17 seconds. It's like heaven and earth!!!
The following figure shows the table structure information based on version numbers implemented after version 8.0.29:
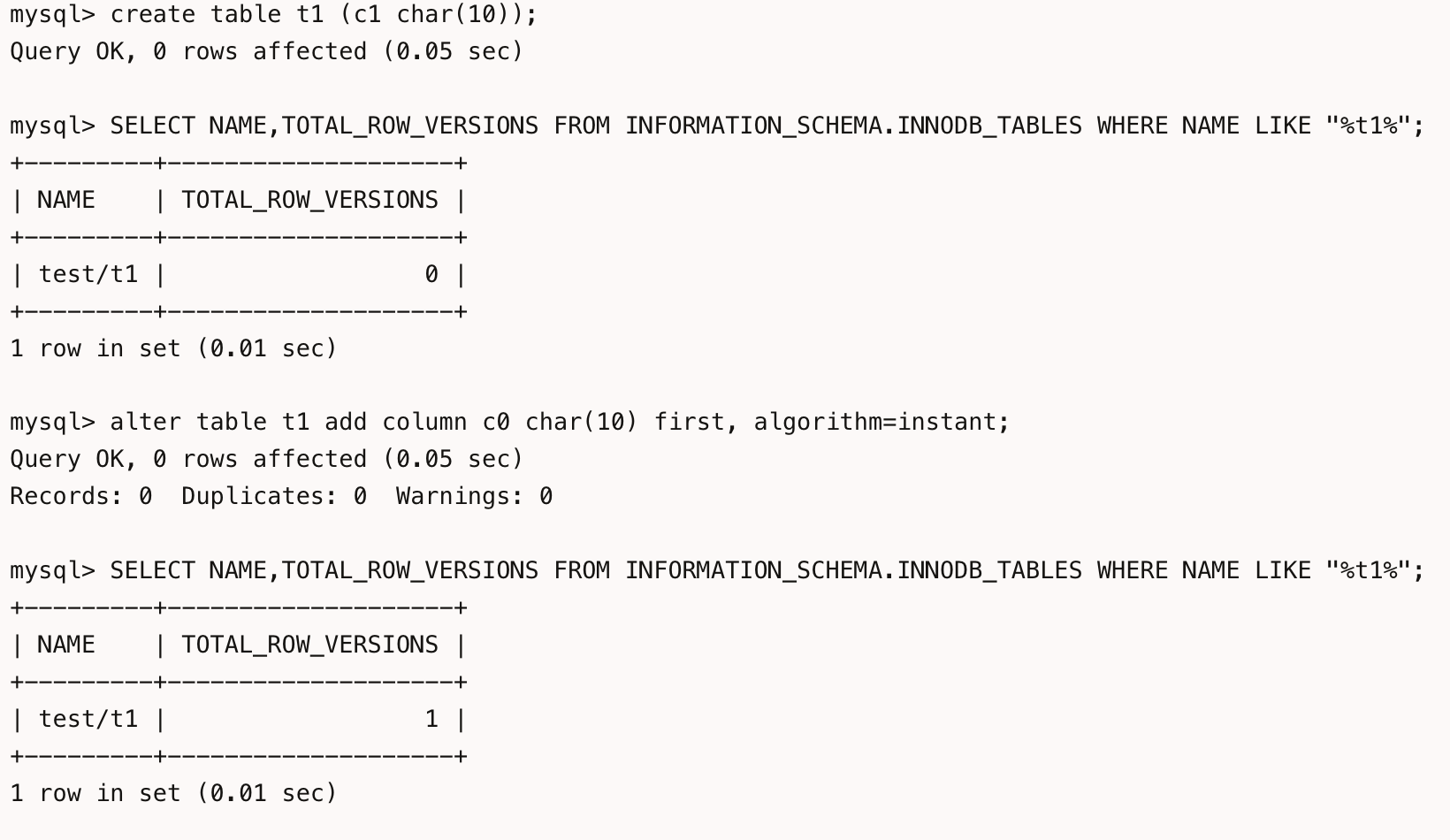
From this diagram, we can see that the table structure in MySQL 8.0.29 already has a version number, and different table structures can be distinguished by the version number.
Execution process of Instant DDL:
We will compare the differences in the execution process between Instant DDL and Online DDL through the following two images (images are from the Alibaba Database Kernel Monthly Report):
The following is the execution process of adding a column in Online DDL:
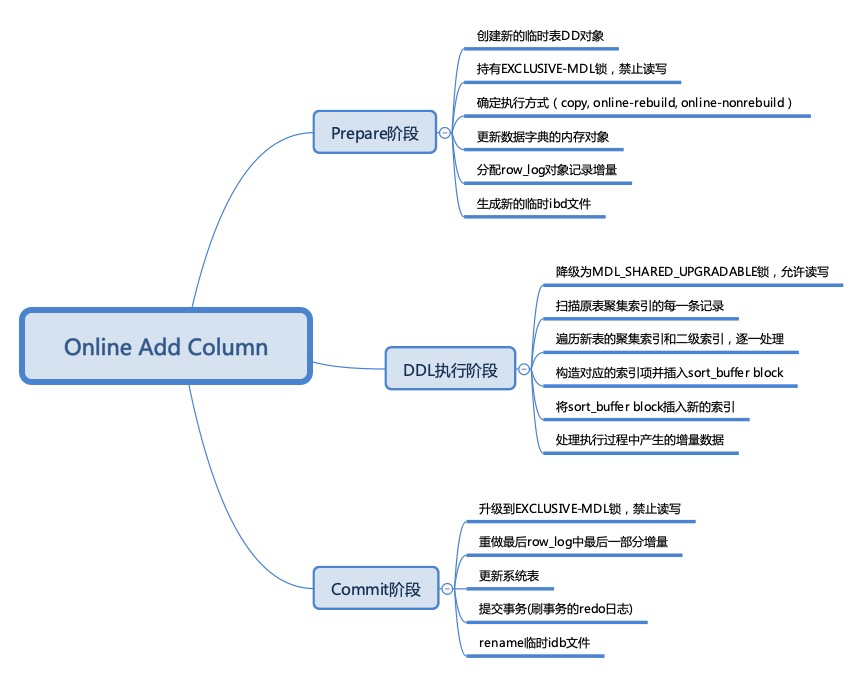
And the picture below shows the process of adding a column with Instant DDL:
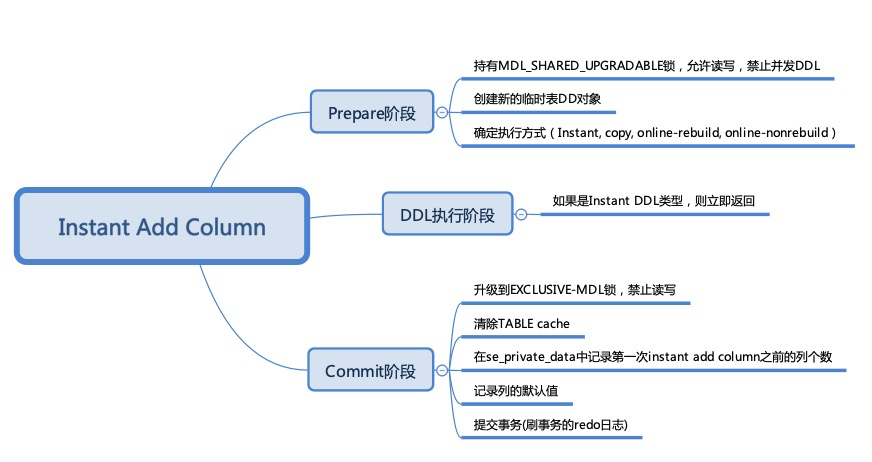
By comparing these two charts, we can see that, compared to Online DDL, Instant DDL only needs to modify the data dictionary and does not need to do anything during the DDL execution phase, allowing it to return immediately. This greatly reduces the process and time required for execution, significantly improving the efficiency of table structure changes.
Internal Implementation of Instant DDL:
We mentioned above that Instant DDL only modifies the data dictionary and does not modify the data. So after the DDL is executed, how does MySQL distinguish data under different table structures?
In fact, the Instant DDL feature also includes the related implementations within the InnoDB storage engine, mainly including the following points:
- Identify whether there is a new data format by setting the bits of the info bits;
- Save the field count information of the current data row by adding the number of fields.
- After MySQL 8.0.29, the structure corresponding to a data row is determined by setting the version number of the data row.
The image below shows the data structure of rows in a table that has not undergone Instant DDL (image from the Alibaba Database Kernel Monthly Report):
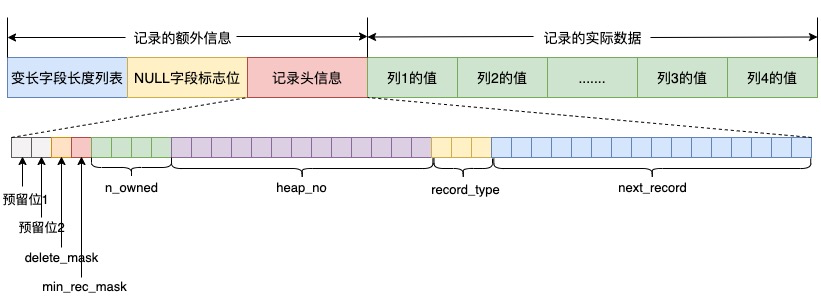
After adding a column via Instant DDL, the structure of newly inserted rows becomes like the following diagram:
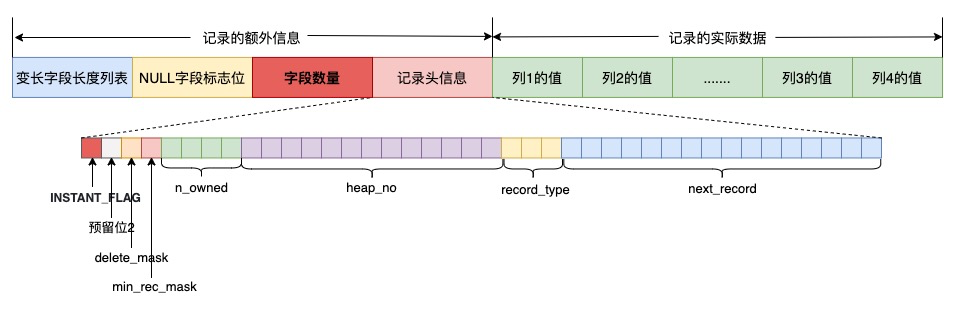
By comparison, we can see that the new record has the INSTANT_FLAG bit set in the info-bits of the record header to indicate that this is a new record inserted after a table structure change, and then the number of fields in the current record is obtained through the red 'Number of Fields' information.
Let's take another look at how specific DML operations are handled after Instant DDL is available:
- Insert: Insert according to the new format
- Search: Determine whether the data is a new or old version based on the flag
- Update: Updated to new format data
- Delete: No change
From the above description, we can see that Instant DDL cleverly distinguishes between old and new data through different data row structures, thereby enabling the identification and access of different versions of data within a single table.
03 KlustronDB's DDL
First, a brief introduction to the core architecture of our Klustron's distributed data product, KlustronDB:
KlustronDB's distributed storage-compute separated architecture
- Computing Layer (KlustronDB_server): Computing nodes composed of multiple PostgreSQL instances are responsible for accepting connection requests from verified application software clients, as well as receiving SQL query requests from established connections, executing the requests, and then returning the query results;
- Storage Layer (KlustronDB_storage): A storage shard (storage shard, abbreviated as shard) is composed of three or more MySQL 8.0 instances forming storage nodes, and each shard stores a portion of user tables or table partitions;
- The metashard stores the metadata of the KlustronDB cluster, including the topology, node connection information, DDL logs, commit logs, and other cluster management logs.
- The cluster_mgr cluster is responsible for maintaining the correct cluster and node states, implementing functions such as cluster management, cluster logical backup and recovery, cluster physical backup and recovery, and horizontal elastic scaling.
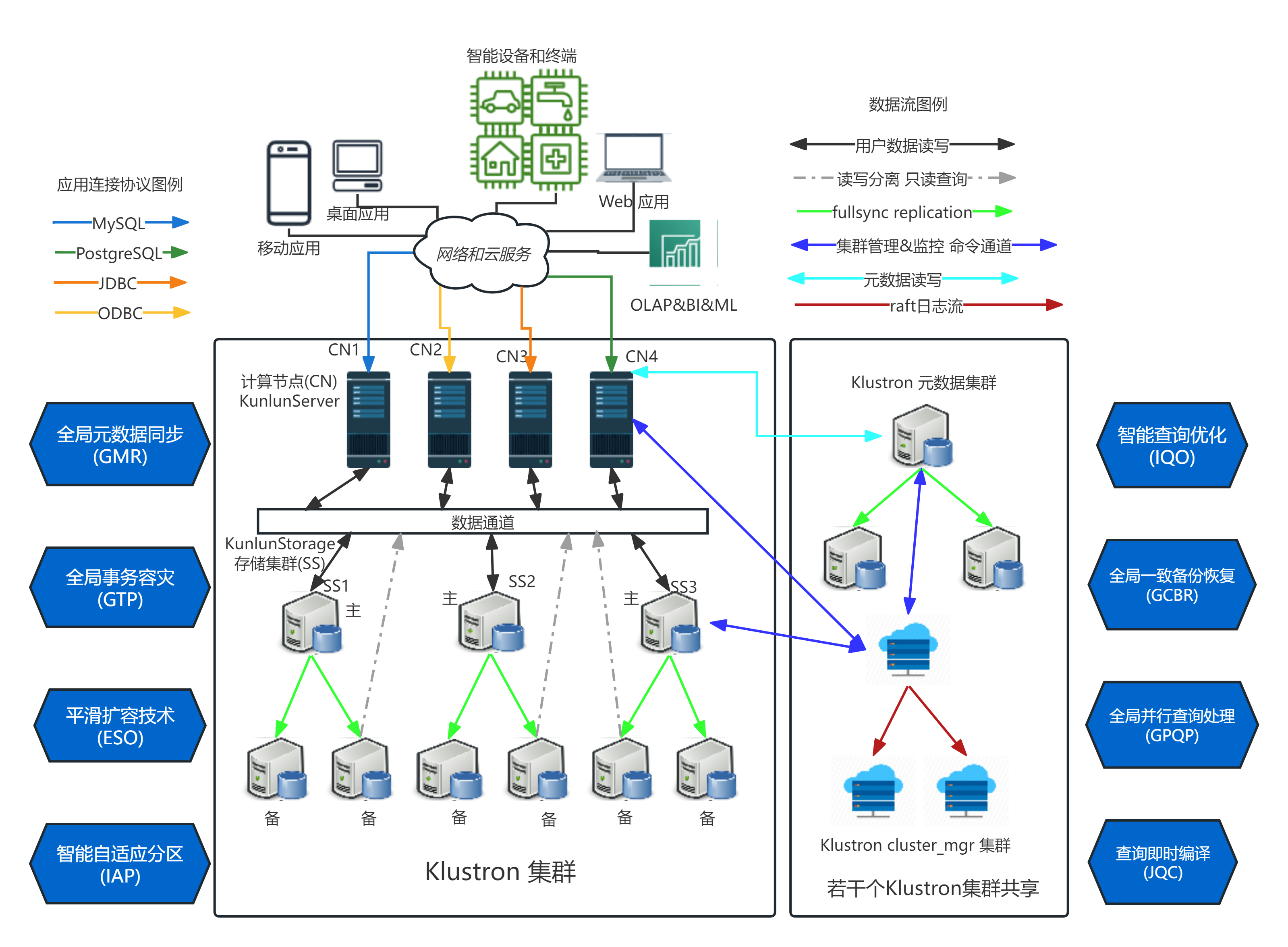
Next, let's introduce KlustronDB's Online DDL feature.
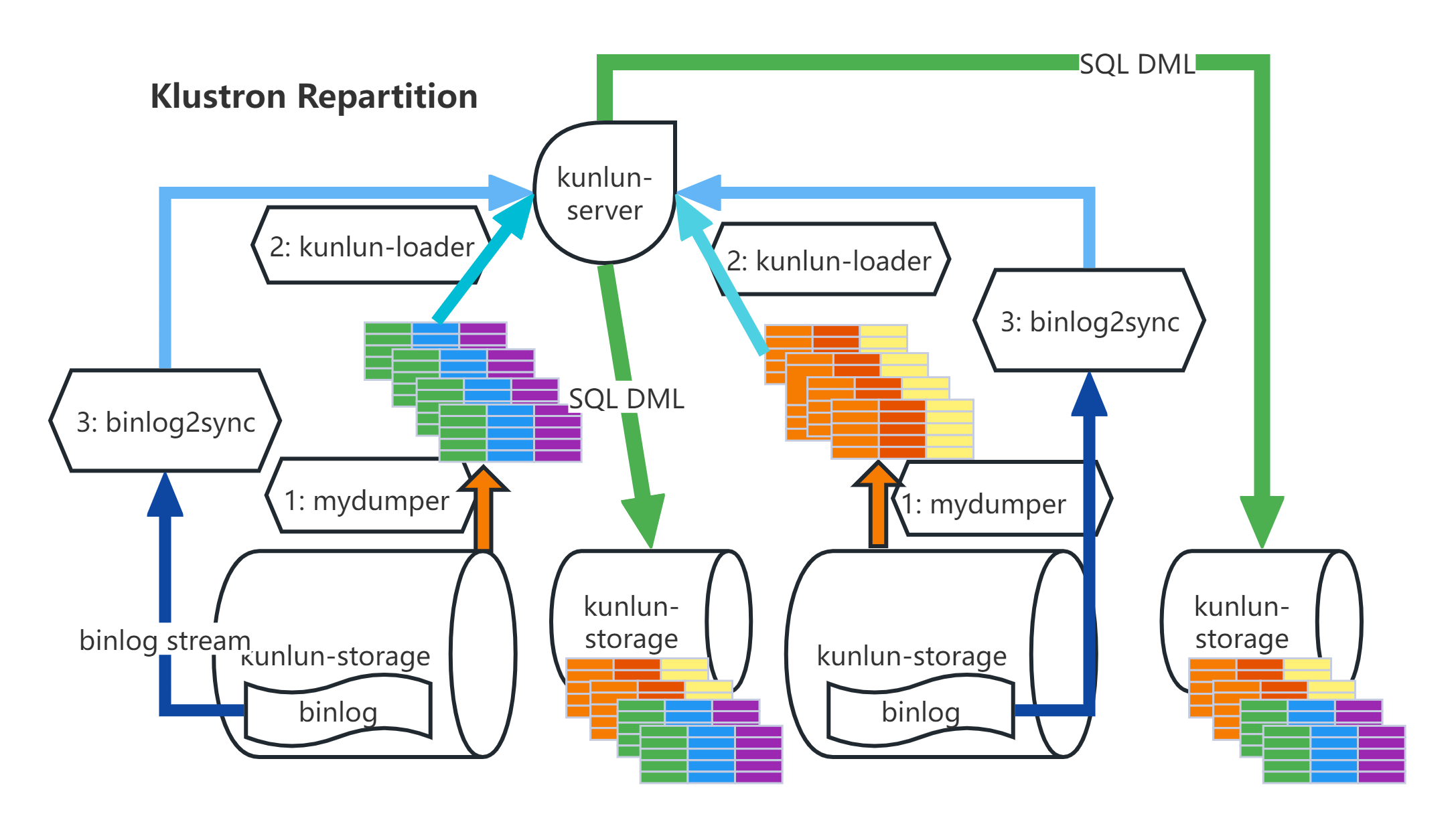
KlustronDB Online DDL (Repartition)
Method: Export the data from the source table and write it into the target table, then import the updates made to the source table during this period into the target table. Detailed steps:
- Export full table data: node_mgr calls mydumper to dump the source table data and transfer the data files to the server where the computing nodes are located.
- Load the full data of the table: node_mgr uses the kunlun_loader tool to dump the full data from the source table into the target table.
- binlog catch-up: node_mgr calls the binlog2sync tool according to the binlog starting positions recorded on each shard during the dump, and the binlog2sync tool starts dumping binlog events from that position.
- Rename the source table and the target table: Use the binlog2sync tool to quickly synchronize the remaining binlogs, and then rename the target table to the source table name, so that the business can resume normal use.
The Future of KlustronDB DDL:
KlustronDB not only implements the important DDL feature of Online DDL, but is also completing and planning other DDL-related features, such as:
- Enhancement and optimization of online DDL (performance optimization through parallel implementation, etc.)
- Transactional DDL (implementing the transactionality of DDL, not just atomicity)
- Enhancement and optimization of Instant DDL (implementing Instant execution for more DDLs)
- Parallelization of DDL
Wait a moment
04 :Q&A
Q1: Does the execution process of Instant DDL require locking?
A1: Instant DDL requires a very brief MDL lock during the final commit phase, which is the stage of switching between the old and new table structures, to ensure that users do not read the wrong table structure at this stage. This lock is extremely short, involves no complex internal operations, and can be said to complete instantly, having no impact on system operation.
Q2: Where can I try out KlustronDB?
A2: Friends who are interested in KlustronDB can download a trial version from our official website and deploy it according to the installation documentation. In addition, we also provide KlustronDB's serverless services on Amazon Marketplace and Alibaba Cloud, which everyone can try if interested.