
Discussion on Efficient One-Sided RDMA Programming Guidelines
Discussion on Efficient One-Sided RDMA Programming Guidelines
Building upon one-sided Remote Direct Memory Access (RDMA) technology, remote data structures have become the cornerstone of today's trending compute-storage separated database management systems. With thousands of users accessing these structures concurrently, there's a pressing need for efficient synchronization schemes. Notably, existing research has highlighted significant disparities in performance and scalability among current synchronization schemes. Worse still, some schemes fail to synchronize correctly, leading to elusive data corruption. Drawing insights from these findings, we cite a Sigmod 2023 paper titled "Design Guidelines for Correct, Efficient, and Scalable Synchronization using One-Sided RDMA." This paper provides the first comprehensive analysis techniques for one-sided RDMA synchronization schemes and lays out general principles for correctly synchronizing using one-sided RDMA. Adhering to these guidelines not only guarantees synchronization accuracy but also yields significant performance enhancements for applications.
01 Background
Remote Direct Memory Access (RDMA) has rapidly become a cornerstone tool for building compute-storage separated databases. Not only does it offer single-digit millisecond network access latency, but it also provides efficient primitives for remote memory access. Notably, one-sided RDMA primitives enable computing nodes to directly read from or write to remote storage servers without the participation of the remote storage node's CPU. Given that storage servers typically have constrained computational capabilities with the bulk of computing power located at the computational tier, one-sided RDMA emerges as a perfect fit for compute-storage separated databases. Recent research trends have concentrated on optimizing the use of one-sided RDMA in these databases. Key components of these systems include one-sided data structures such as hash tables, B-Trees, and SkipLists, all of which facilitate efficient access to remote data. Since one-sided operations don't require the intervention of a remote CPU, traditional synchronization techniques that rely on the storage-side CPU become ineffective. Consequently, a variety of one-sided synchronization approaches have been proposed, broadly categorized into pessimistic and optimistic. Pessimistic strategies prevent concurrent modifications, while optimistic ones detect and address them. These methodologies exhibit fundamental differences in terms of scalability and performance.
Remote data structures might have to serve thousands of client connections originating from multiple computing nodes. With such high concurrency, the performance hinges on the implementation of the one-sided synchronization scheme. While various papers have introduced different one-sided synchronization strategies, it's surprising that no study has systematically investigated these proposals under comparable workloads and conditions. This paper is the first to offer an in-depth performance analysis, revealing that even subtle design decisions within a scheme could gravely impact its performance, leading to performance bottlenecks. Implementing high-performance synchronization is undoubtedly valuable, but ensuring correctness is an essential prerequisite. The paper identifies that certain techniques from previous studies don't adequately synchronize concurrent operations, leading to elusive data inconsistencies. Consider the scenario of optimistic synchronization schemes: they usually assume that RDMA operations are executed in an ascending order by address—a common presumption in many papers. The method employed involves first writing the version number in the data header, then altering the data, followed by the data's tail-end version. Assuming operations execute in an ascending address order, concurrent reads can detect concurrent modifications by comparing the header and tail versions. Unfortunately, contrary to the general assumption present in numerous papers, RDMA read operations don't execute in an address-increasing order. In fact, the RDMA specification doesn't specify byte-read sequences in RDMA. Therefore, the synchronization scheme mentioned earlier might pose problems. For instance, consider the following data structure:[version-data-version]
Should an application attempt to read this data in a single RDMA read, it's possible for the data portion to be returned before the initial version value. As a result, a concurrent writer could modify the data and subsequently increment the version. The reader issuing the RDMA read could access the new data value before reading the old version value. Then, when it finally verifies the version, it still matches the initial old value read, so the reader won't detect the concurrent modification. Surprisingly, this issue remains largely under the radar, and assumptions based on address-sequential reading remain prevalent. The paper posits that the crux of the issue lies in the fact that a single RDMA request requires numerous protocols - not just RDMA but also PCIe and cache consistency - to work in tandem. Consequently, understanding the guarantees offered by the respective specifications presents its challenges. As illustrated in Figure 1, the RNIC is connected to the memory control hub (MCH) of a multi-core processor via the PCIe bus. The MCH handles memory access requests from both the CPU and external devices. The MCH incorporates a memory controller, a consistency protocol, and serves as the root complex for the PCIe bus. Modern server architectures have implemented cache coherent direct I/O, such as Intel's DDIO and ARM's CCI. Therefore, RDMA's access to system memory will probe (look up) the CPU cache for conflicting addresses, an indispensable step. If a conflicting address is found, it can be serviced from the CPU cache; otherwise, it must be fetched from the main memory. Cache coherent I/O stands as a key driving force for many applications.
_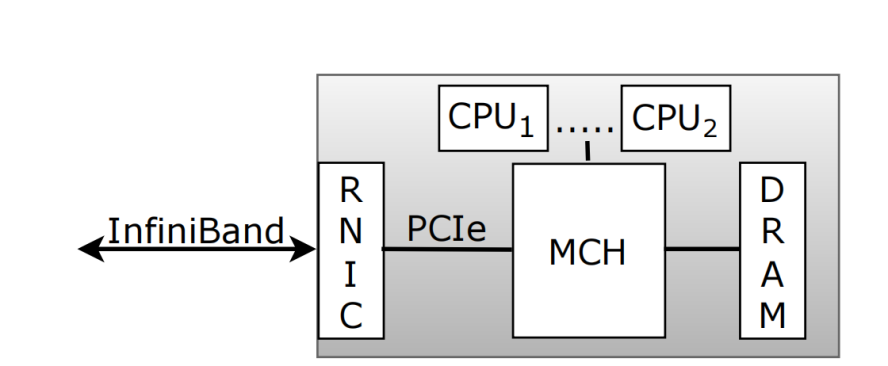
Figure 1. Hardware modules involved in RDMA operations
Below, we delve into the potential pitfalls worth considering when constructing RDMA applications, examining both pessimistic and optimistic synchronization implementations of one-sided RDMA. The testing platform adopts the widely-used InfiniBand specification and associated infrastructure. This specification shares commonality with alternative RDMA protocols, making the test results applicable to a broad range of general deployment scenarios.
02 One-sided RDMA Pessimistic Synchronization Implementation
To prevent simultaneous modifications to remote data structures, such as B-trees or hash tables, one-sided pessimistic synchronization techniques utilize one-sided RDMA operations to implement latches. In this section, we introduce the basic implementation of such latches and use them as running examples to discuss possible optimizations. As RDMA atomic instructions form the foundational building blocks of these one-sided latches, the paper delves deeply into the scalability characteristics and performance of these RDMA atomic instructions. Subsequently, potential optimizations for one-sided latches are outlined and evaluated.
2.1 Performance of RDMA Atomic Operations
Given that each pessimistic synchronization method relies on RDMA atomic instructions (CAS and FAA), it's vital to understand their concurrent isolation performance before discussing how to optimize the fundamental latch implementation. In the first experiment, the scalability of contentious and non-contentious RDMA atomic operations is inspected. Both scenarios are equally crucial. While intense contention is rare, it's inevitable in certain workloads, such as with hot tuples. To demonstrate the effects of contention, an experiment was conducted where all worker threads executed RDMA CAS instructions targeting the same 8-byte atomic counter. To understand the scale that contention-free atoms can achieve, each worker thread was assigned a private 8-byte remote atomic counter. For reference, the difference in RDMA atomic operation performance under non-contentious conditions is compared to RDMA read performance.

Figure 2. Scalability of contentious and non-contentious RDMA atomic operations as the number of working threads increases (4 computing nodes and 1 storage node)
Figure 2 displays the scalability characteristics of RDMA atomic operations under both non-contentious and contentious scenarios as the number of working threads increases. As shown, non-contentious atomic operations resemble one-sided RDMA read operations, peaking in performance with 128 threads, achieving a throughput of approximately 51.2 million operations per second. This suggests that parallel non-contentious atomic operation requests do not interfere with each other, though later it will be demonstrated this doesn't hold in all cases. Notably, the decline in performance of non-contentious atomic operations with 512 working threads isn't attributable to the atomic operations themselves, but mainly to jitter in the RDMA Queue Pairs (QP) on the client machine. QP jitter means the QP status isn't cacheable on the RNIC card and needs frequent swapping. As expected, the peak for contentious atomic operations is considerably lower than non-contentious scenarios, at just 2.32 million operations per second, scaling up to only 8 working threads.
In some literature, RDMA atomic operations seem to have a bad reputation for being non-scalable - even for non-contentious workloads. However, the aforementioned experiment indicates that throughput for non-contentious atomic operations can scale nicely with the increment in thread count. Indeed, their scalability performance is on par with RDMA read operations. While this experiment offers valuable insights into the scalability aspect of atomic operations, as will be shown below, it's not the complete story about RDMA atomic operations.
Clearly, the scalability of RDMA atomic operations depends on parallelism. However, subtle details like data alignment can also impact scalability. In the experiment above, data was placed in 64-byte blocks (equivalent to a cache line size). The first 8 bytes were used as an atomic counter, neglecting the remaining 56 bytes. In practice, RDMA atomic operations are often situated on larger data blocks, safeguarding data of various sizes, such as a 4 KB B-tree node.
A subsequent experiment measures the effect of large data blocks by varying the distance between atomic counters. Like the previous non-contentious experiment, each working thread owns a private latch to avoid contention. Hence, expected outcomes should mirror the non-contentious results seen in Figure 2. Surprisingly, results in Figure 3 indicate that block size severely impairs scalability. That is, the larger the data block, the more pronounced the inflection point. Throughput peaks (highlighted in red) are reached earlier. With a 64-byte data block size, the performance peak is at 50 million for 128 threads, consistent with the upper limit of Figure 2; for a block size of 256 bytes, peak performance is 40 million for 128 threads; and with a 512-byte data block, peak performance is halved.

Figure 3. Scalability of atomic operations in non-contentious scenarios with varying data block sizes
Scalability can only reach up to 64 threads. Keep in mind that there isn't real latch contention here; we're just varying the distance between atomic counters without any other operations. The observed behavior can likely be attributed to physical contention within the RNIC. Through reverse engineering, the paper's authors hypothesize that the RNIC uses an internal lock table to serialize atomic operations. The working mechanism of the lock table, similar to a hash table, can lead to conflicts. Even non-contentious atomic operations can be allocated to the same slot, significantly limiting the throughput of concurrent, non-contentious atomic operations. The slot in the lock table is determined by the last 12 bits of the target address of the atomic operation. As shown in Figure 4b(i), the last 12 bits of a 4KB data page are all zeros, meaning atomic operations on these data pages are allocated to the same lock table slot, leading to physical contention, as shown in Figure 4a. This explains the phenomenon observed in Figure 3: when data block alignment is not properly chosen, logically conflict-free atomic operations may not be scalable. Hence, to improve the scalability of non-contentious operations, we must avoid lock table collisions. The only way to control this is by altering the data layout, changing the latch's address in the lock table. The goal is to vary the addresses within the lock table, so the last 12 bits (used for lock slot computation) differ. Consider the example in Figure 4(b) ii); instead of consecutively allocating 4 KB blocks, an 8-byte padding is placed before the latch. Now, the last 12 bits of the latch address are not all zeros, and it will be allocated to different lock slots. The effects of this mitigation technique are shown in the right graph of Figure 3. One could also design by separating the latch from the data, but such a data placement approach is not cache-friendly.
However, it's challenging to generalize these conclusions, as RNIC manufacturers haven't publicly disclosed implementation details. So, like other papers, we can only infer the implementation specifics here. This underscores how crucial NIC hardware details are and illustrates that potential bottlenecks should be carefully evaluated when building high-performance systems.
_
Figure 4. The internal structure of RNIC affects the implementation of pessimistic synchronization
2.2 Optimizing Pessimistic Latch Implementation

Figure 5. Evolution of Latch Optimization
After understanding how to use atomic operations optimally, focus can now be placed on designing the optimal pessimistic latch. Recall that in the basic latch and its variants, all operations are executed synchronously. After each operation, it's necessary to poll the completion queue and wait for the operation to finish. While this is correct, it's inefficient and adds latency to each operation. Speculative read optimization overlaps the latch request with the read request, minimizing read wait latency. This optimization depends on guarantees of operation ordering. That is, it's essential to ensure that the atomic operation is ordered before the read operation. Fortunately, the InfiniBand specification meets this requirement. The second optimization overlaps the write operation with the unlock atomic operation, especially if the last operation happens to be a write. This optimization can use the unlock operation to mask the latency of the last write operation. Asynchronous unlocking goes a step further, not waiting synchronously for the unlock operation to complete before executing the next operation. This requires careful buffer management to avoid overwriting. The final optimization involves only using the write operation and not a separate atomic operation to unlock. For example, in an RDMA-based key-value store, the value carries unlocking information to achieve the unlocking purpose. However, this optimization needs to be used with CAS and not FAA. It also limits the lock to have only one exclusive mode. Figure 5 illustrates how the above optimizations work.
03 One-sided RDMA Optimistic Synchronization Implementation
From the previous content, we have seen that pessimistic lock synchronization has good scalability when there is no contention. However, in some data structures, lock contention is inevitable, in fact, it is determined by the inherent design of the data structure. For instance, all operations in a B-Tree must traverse the root node of the B-Tree. Although the root node is primarily locked in shared mode, when using pessimistic synchronization, this also results in (physical) contention on the RNIC, negatively impacting performance. This is why many studies bypass RDMA atomic operations and propose optimistic synchronization: optimistic reads do not physically lock data but detect if concurrent modifications exist. Below, we list some correct optimistic synchronization schemes.
3.1 Simple Optimistic Synchronization Implementation
In optimistic synchronization, readers proceed optimistically and then validate. Meanwhile, writers acquire a physical pessimistic lock to avoid write-write conflicts. To achieve the same guarantees as a shared pessimistic latch, the reader must check that the data item has not been modified during its operation. This is typically implemented using enhanced data items with version counters and incrementing the counter every time a modification is made, allowing readers to detect concurrent writes. The data layout for this enhanced optimistic latch is shown in Figure 6(a). It consists of a pessimistic latch register for exclusive access and a version counter. Using this version counter, readers can verify that the version hasn't changed during the operation. If validation fails, the operation is restarted.
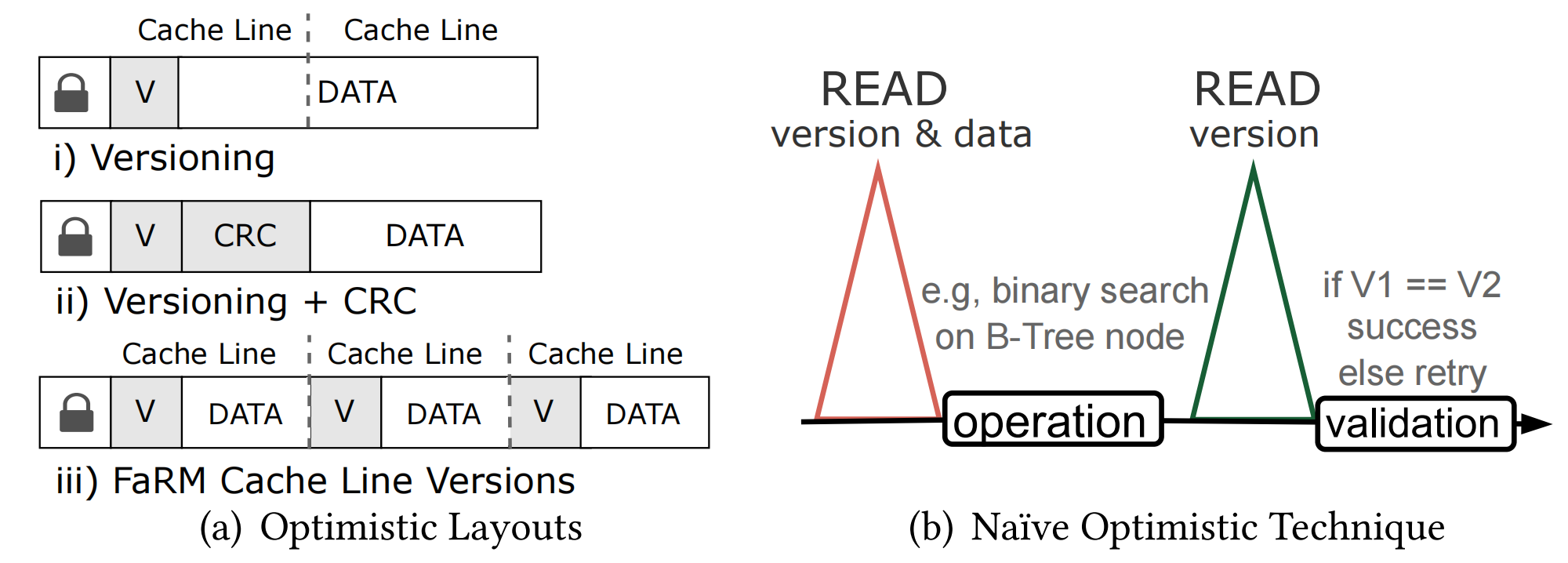
Figure 6. Optimistic Synchronization Implementation
The most naive optimistic synchronization latch implementation is shown in Figure 6(b). This method uses a single RDMA to copy the latch, version, and data to a thread-private space. The thread can then check if the data is exclusive. If it is, it restarts. Otherwise, by detecting the lock, it performs the corresponding operation, such as a binary search in a B-Tree node, which is optimistically executed. After the operation is complete, the version is read again (through RDMA) and compared to the initial value. This post-operation validation is crucial for detecting concurrent modifications, obtaining the same guarantees as with a pessimistic latch. Therefore, the validation essentially acts as an unlock operation.
3.2 PCIe Sequence Guarantees
Regrettably, the above naive optimistic synchronization implementation is not accurate. As pointed out in the literature, there are three factors affecting data transfer order: (1) the order of messages, (2) the order of packets within a single message, and (3) the order of DMA. The first two factors are generally guaranteed by InfiniBand and RoCE. However, even if the message order is assured, DMA operations are not guaranteed to execute in address order. The InfiniBand RDMA specification itself does not provide assurances regarding byte-order operations within a single RDMA read operation. Therefore, to fully understand why RDMA read operations might not execute in increasing address order, it is crucial to investigate the impacts of PCIe and the cache coherence protocol. Only after understanding these underlying protocols can we design correct synchronization techniques. As shown in Figure 1, RDMA read requests are sent over the network to a remote node. Then, the RNIC dispatches the request to the PCIe controller, which retrieves the requested data from host memory. Subsequently, data is sent back to the RNIC via PCIe. Finally, it's sent back to the requester in one or more RDMA packets. An important aspect is that PCIe requests are cache coherent in modern server architectures. Since the actual data transfer from remote memory to the remote RNIC is initiated and executed via PCIe, the guarantees provided by this hardware stack layer are paramount. We must review the PCIe specification to pinpoint the root of the issue.

Figure 7. Correct Optimistic Latch Implementation
The PCIe specification states, "Memory read requests served by multiple completion packets will be returned in the order of the completion packets' addresses." From this, we see that PCIe returns in the order of completion packets, not based on the addresses from which data is retrieved from memory. In fact, the implementation allows for "a single memory read operation requesting multiple cache lines to fetch multiple cache lines from host memory simultaneously" - and there lies the problem! Because cache lines may be fetched in parallel, we cannot reliably use the simple implementation in Figure 6(b) to detect concurrent modifications. Imagine the following scenario: a reader and writer operate concurrently. Due to the lack of order guarantees, the reader might first read the current second cache line, while the writer is modifying the data. Concurrently, the writer increases the version number and unlocks the data. Only then does the reader read the first cache line containing the latch and version. The consequence is that, although the final validation step will reread the version number, the reader might mistakenly believe the version hasn't changed, leading to undetectable data corruption. Below is the correct implementation of optimistic latching.
Version Control (two reads, one for the version and one for the data). This technique doesn't differ much from the naive implementation; however, it requires two serial RDMA reads at the beginning. The first RDMA read targets only the lock and version, and only the second read fetches the data. One might wonder if overlapping execution, similar to what's shown in Figure 5, could mask the overhead of the two RDMA reads. Unfortunately, because read operations might be reordered in PCIe or even the network, this optimization can't be implemented in read scenarios. The correct implementation is shown in Figure 7a.
CRC+ Version Control. This method detects inconsistencies using a data checksum, e.g., CRC64, allowing the working thread to validate the data with high probability. If there's a concurrent write, the corrupted data won't match the CRC. Thus, in the best-case scenario, only one RDMA read is needed. However, the downsides are (1) CRC generation is computationally expensive, and (2) it's probabilistic.
Cache Line Version. Similar to CRC, Microsoft researchers proposed attaching version information to each cache line, avoiding an additional dedicated RDMA read for the version and latch information. The added cost is checking if each cache line's version information is consistent and additional storage space.
Even though the correct optimistic synchronization requires additional costs, such as a separate serial RDMA read to obtain version information and extra storage space, optimistic concurrency control has been proven to have good scalability. In situations with high concurrency, it can offer about a 2x performance increase over pessimistic concurrency. Another interesting finding is that, combined with an optimistic latch implementation, scalability of writes can be enhanced by employing the write-unlatch optimization. In summary, pessimistic and optimistic approaches have different trade-offs and requirements in terms of computation and storage.
Conclusion
As the first analytical study on RDMA synchronization primitives, its aim is to let readers draw lessons from practical work. The author distilled the following insights: 1) There's no guarantee on cache line order within a single RDMA read; 2) Overlapping RDMA reads also lack sequence assurance almost in the same manner; 3) One should treat with caution designs that combine RDMA writes with RDMA atomic operations. In some cases, the lack of atomicity doesn't breach semantics and might lead to better performance; 4) Data alignment affects the scalability of RDMA atomics; 5) Optimistic synchronization performs best in highly competitive situations; 6) The overhead of optimistic synchronization is non-negligible; 7) System designers, prioritizing production stability, should lean towards simple pessimistic synchronization until the community has successfully navigated the intricacies of clearly defined RDMA reads/writes and the associated memory semantics. Starting from existing techniques, the paper emphasizes the nuances of RDMA synchronization in terms of correctness, provides comprehensive performance analysis on current synchronization technologies and their optimizations, and also showcases the flaws in existing designs. It is a commendable paper worthy of reading and studying.
END
A "latch" refers to a physical lock used to protect a program's critical sections and related data structures. Its implementation relies on atomic machine instructions, such as Compare-and-Swap or Test-and-Set. This should be distinguished from "locks" in databases, which are conceptual at the logical level and are implemented using hash tables and lock compatibility matrix principles.