
部署HDFS 高可用集群作为Klustron备份存储
部署HDFS 高可用集群作为Klustron备份存储
注意:
如无特别说明,文中的版本号可以使用任何已发布版本的版本号代替。所有已发布版本详见:Release Notes
概述
主要内容是 KunlunBase HDFS 高可用(High Availability, HA)集群做备份存储配置,安装配置 java 软件和配置 kunlun 用户环境变量,安装配置 Hadoop,配置 Hadoop 参数文件和环境变量,配置 HDFS HA 模式,测试 HDFS HA 存储。最后通过 XPanel 控制台配置 HDFS 备份存储目标。
配置 HDFS HA 的机器 IP 分别为 192.168.56.118 和 192.168.56.119,端口都为 9000。
1 HDFS 高可用(HA)模式部署环境
1.1 HDFS HA 部署规划
| HDFS HA部署规划 | HDFS HA部署规划 |
|---|---|
| hdfs1:192.168.56.118 | hdfs2:192.168.56.119 |
| NameNode | NameNode |
| JournalNode | JournalNode |
| DataNode | DataNode |
1.2 [hdfs1,hdfs2]服务器上都配置/etc/hosts文件,配置主机名和IP地址的对应关系。使用root执行下面的命令。
vi /etc/hosts
192.168.56.118 hdfs1
192.168.56.119 hdfs2
备注:这里的 hdfs1 和 hdfs2 分别是两台服务器的主机名,如果环境主机名不是 hdfs1 和 hdfs2,需要将 hdfs1 和 hdfs2 调整为对应的主机名。
2 下载部署 java 和 hadoop 软件
2.1 [hdfs1,hdfs2] 服务器上创建 kunlun 组和 kunlun 用户。使用 root 执行命令并设置用户密码。
useradd --create-home --shell /bin/bash kunlun
passwd kunlun

2.2 [hdfs1,hdfs2] 服务器上安装 wget 工具。使用 root 执行下面的命令。
yum -y install wget

2.3 [hdfs1,hdfs2]服务器上下载hadoop软件和java软件,使用root执行下面的命令。
cd /home/kunlun
wget http://zettatech.tpddns.cn:14000/thirdparty/hadoop-3.3.1.tar.gz
wget http://zettatech.tpddns.cn:14000/thirdparty/jdk-8u131-linux-x64.tar.gz
2.4 [hdfs1,hdfs2] 服务器上安装配置 java,将 java 软件解压到/usr/java目录下,使用 root 执行下面的命令。
tar -zxvf jdk-8u131-linux-x64.tar.gz -C /usr/java
cd /usr/java/jdk1.8.0_131/bin
./java -version

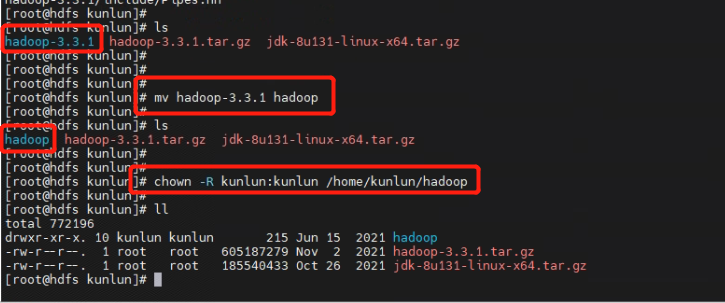
2.5 [hdfs1] 服务器上安装 hadoop 软件,将 hadoop 软件解压到/home/kunlun目录下,并将解压的文件夹 hadoop-3.3.1 重命名为 hadoop,然后将 hadoop 的所属用户和组修改为 kunlun:kunlun。使用 root 执行下面的命令。
tar -zxvf hadoop-3.3.1.tar.gz
mv hadoop-3.3.1 hadoop
chown -R kunlun:kunlun /home/kunlun/hadoop
2.6 [hdfs1,hdfs2] 服务器上关闭每台服务器的防火墙。在 root 用户下执行命令。
systemctl stop firewalld
systemctl disable firewalld
2.7 [hdfs1,hdfs2] 服务器上对 kunlun 用户配置免密登录。使用 kunlun 用户执行以下命令。
a)在两个节点生成密钥(分别在两个个节点执行)
[kunlun@hdfs1 ]$ ssh-keygen #按三次回车
[kunlun@hdfs2 ]$ ssh-keygen
b)将两个节点的密钥都拷贝到 hdfs1 节点中(分别在两个节点执行)
[kunlun@hdfs1 ]$ ssh-copy-id hdfs1
[kunlun@hdfs2 ]$ ssh-copy-id hdfs1
c) 将节点一的密钥拷贝到节点二 (在节点一上执行)
[kunlun@hdfs1 ]$ scp -r ~/.ssh/authorized_keys hdfs2:~/.ssh/
d)测试两个节点间的ssh互相设置成功
[kunlun@hdfs1 ]$ ssh hdfs1 date
[kunlun@hdfs1 ]$ ssh hdfs2 date
[kunlun@hdfs2 ]$ ssh hdfs2 date
[kunlun@hdfs2]$ ssh hdfs1 date
3 配置 HDFS
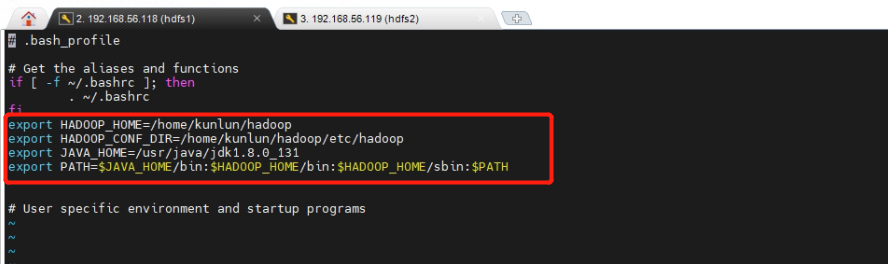
3.1 [hdfs1,hdfs2] 服务器上配置 kunlun 用户的环境变量。使用 kunlun 用户执行以下命令。
vi ~/.bash_profile
export HADOOP_HOME=/home/kunlun/hadoop
export HADOOP_CONF_DIR=/home/kunlun/hadoop/etc/hadoop
export JAVA_HOME=/usr/java/jdk1.8.0_131
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source ~/.bash_profile
3.2 [hdfs1] 服务器上修改 hadoop 配置文件,配置文件在/home/kunlun/hadoop/etc/hadoop目录下。使用 kunlun 用户执行以下命令。
[kunlun@hdfs1 hadoop]$ cd /home/kunlun/hadoop/etc/hadoop
ls

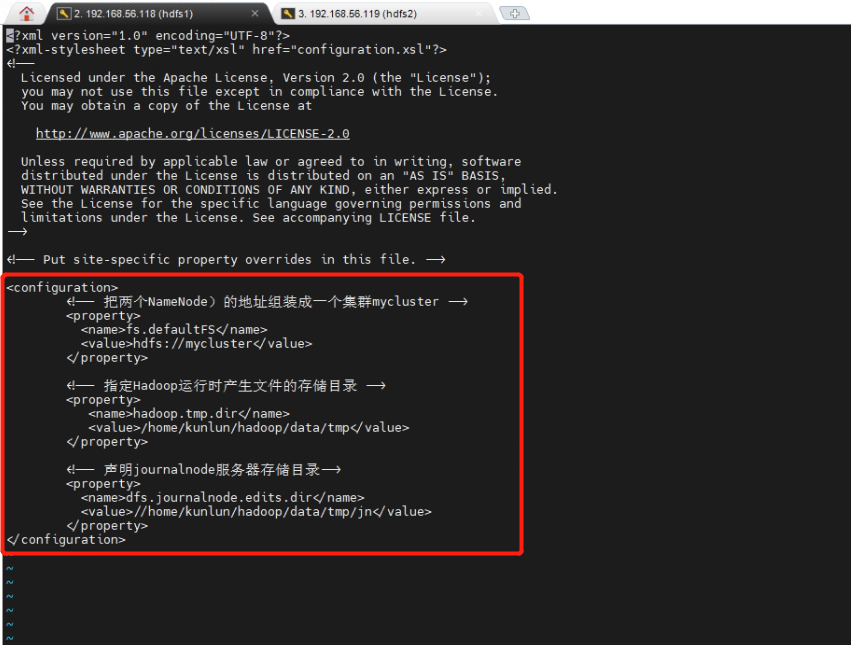
3.3 [hdfs1] 服务器上修改 core-site.xml 配置文件。使用 kunlun 用户执行以下命令。
[kunlun@hdfs1 hadoop]$ vi core-site.xml
<configuration>
<!-- 把两个NameNode)的地址组装成一个集群mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/kunlun/hadoop/data/tmp</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>//home/kunlun/hadoop/data/tmp/jn</value>
</property>
</configuration>
3.4 [hdfs1] 服务器上修改 hdfs-site.xml 配置文件。使用 kunlun 用户执行以下命令。
[kunlun@hdfs1 hadoop]$ vi hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hdfs1:9000</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hdfs2:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hdfs1:50090</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hdfs2:50090</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hdfs1:8485;hdfs2:8485/mycluster</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
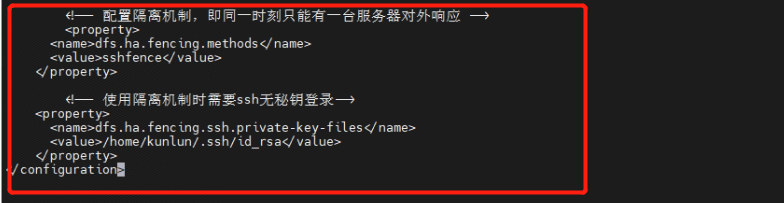
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/kunlun/.ssh/id_rsa</value>
</property>
</configuration>

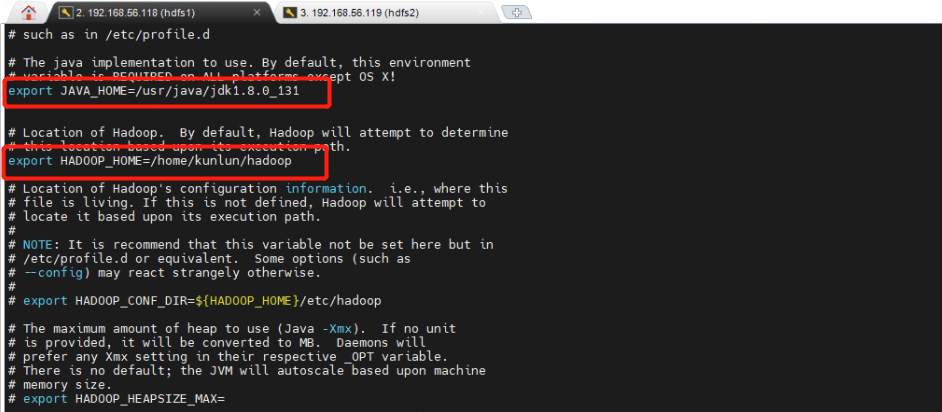
3.5 [hdfs1] 服务器上修改 hadoop 环境变量配置文件hadoop-env.sh,设置JAVA_HOME环境变量。使用kunlun用户执行以下命令。
[kunlun@hdfs1 hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_131
export HADOOP_HOME=/home/kunlun/hadoop
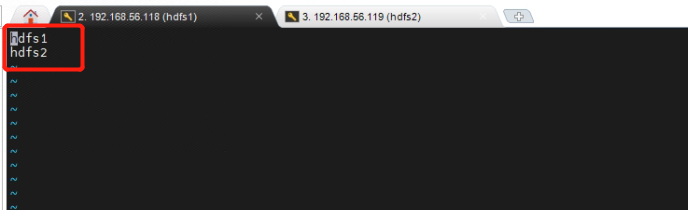
3.6 [hdfs1]服务器上修改workers配置文件。使用kunlun用户执行以下命令。
[kunlun@hdfs1 hadoop]$ more workers
hdfs1
hdfs2
3.7 [hdfs1] 服务器上将配置好的 Hadoop 程序目录拷贝到集群中其他节点 [hdfs2] 服务器上。使用 kunlun 用户执行以下命令。
[kunlun@hdfs1 hadoop]$ scp -rq /home/kunlun/hadoop 192.168.56.119:/home/kunlun/

3.8 [hdfs1,hdfs2] 服务器上分别输入以下命令启动 JournalNode 服务。使用 kunlun 用户执行以下命令。
[kunlun@hdfs1 hadoop]$ hdfs --daemon start journalnode
[kunlun@hdfs2 hadoop]$ hdfs --daemon start journalnode


3.9 [hdfs1] 服务器上对 NameNode 进行格式化,并启动 NameNode。使用 kunlun 用户执行以下命令。
[kunlun@hdfs1 hadoop]$ hdfs namenode -format
[kunlun@hdfs1 hadoop]$ hdfs --daemon start namenode


3.10 在 [hdfs2] 服务器上同步 NameNode 元数据信息,然后启动 NameNode。使用kunlun用户执行以下命令。
[kunlun@hdfs2 ~]$ hdfs namenode -bootstrapStandby
[kunlun@hdfs2 ~]$ hdfs --daemon start namenode


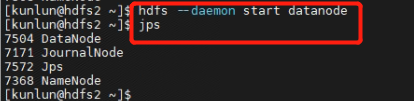
3.11 [hdfs1,hdfs2] 服务器上分别启动 DataNode。使用 kunlun 用户执行以下命令。
[kunlun@hdfs1 hadoop]$ hdfs --daemon start datanode
[kunlun@hdfs2 ~]$ hdfs --daemon start datanode

3.12 将 [hdfs1] 服务器上 nn1 切换为 Active。使用 kunlun 用户执行以下命令。
[kunlun@hdfs1 hadoop]$ hdfs haadmin -transitionToActive nn1

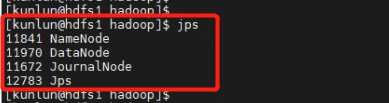
3.13 [hdfs1,hdfs2] 服务器上查看 hdfs 进程启动状态。使用 kunlun 用户执行以下命令。
[kunlun@hdfs1 hadoop]$ jps
[kunlun@hdfs2 ~]$ jps

3.14 在 [hdfs1] 服务器上创建 hdfs 文件系统,并查看创建的 hdfs 文件系统。使用 kunlun 用户执行以下命令。
[kunlun@hdfs1 hadoop]$ hdfs dfs -mkdir /kunlun
[kunlun@hdfs1 hadoop]$ hdfs dfs -ls /

3.15 在 [hdfs2] 服务器上查看 [hdfs1] 上创建 hdfs 文件系统已同步。使用 kunlun 用户执行以下命令。
[kunlun@hdfs2 ~]$ hdfs dfs -ls /

3.16 通过 start-dfs.sh 或 stop-dfs.sh 命令启动或停止 hdfs。
[kunlun@hdfs1 hadoop]$ stop-dfs.sh
[kunlun@hdfs1 hadoop]$ jps
[kunlun@hdfs1 hadoop]$ start-dfs.sh
[kunlun@hdfs1 hadoop]$ jps
[kunlun@hdfs1 hadoop]$ hdfs haadmin -transitionToActive nn1
完成HDFS HA存储配置。
4 配置 HDFS 备份存储配置
4.1 通过登录 XPanel 控制台配置 HDFS 备份存储目标。
XPanel 服务安装的服务器 IP 是 192.168.56.112。
在能访问 192.168.56.112 的机器上打开浏览器,输入地址:http://192.168.56.112:18080/KunlunXPanel/#/login?redirect=%2Fdashboard
初次登录用户名和密码是:super_dba/super_dba,初次登陆需要修改 super_dba 密码。
登录后首页显示如下。
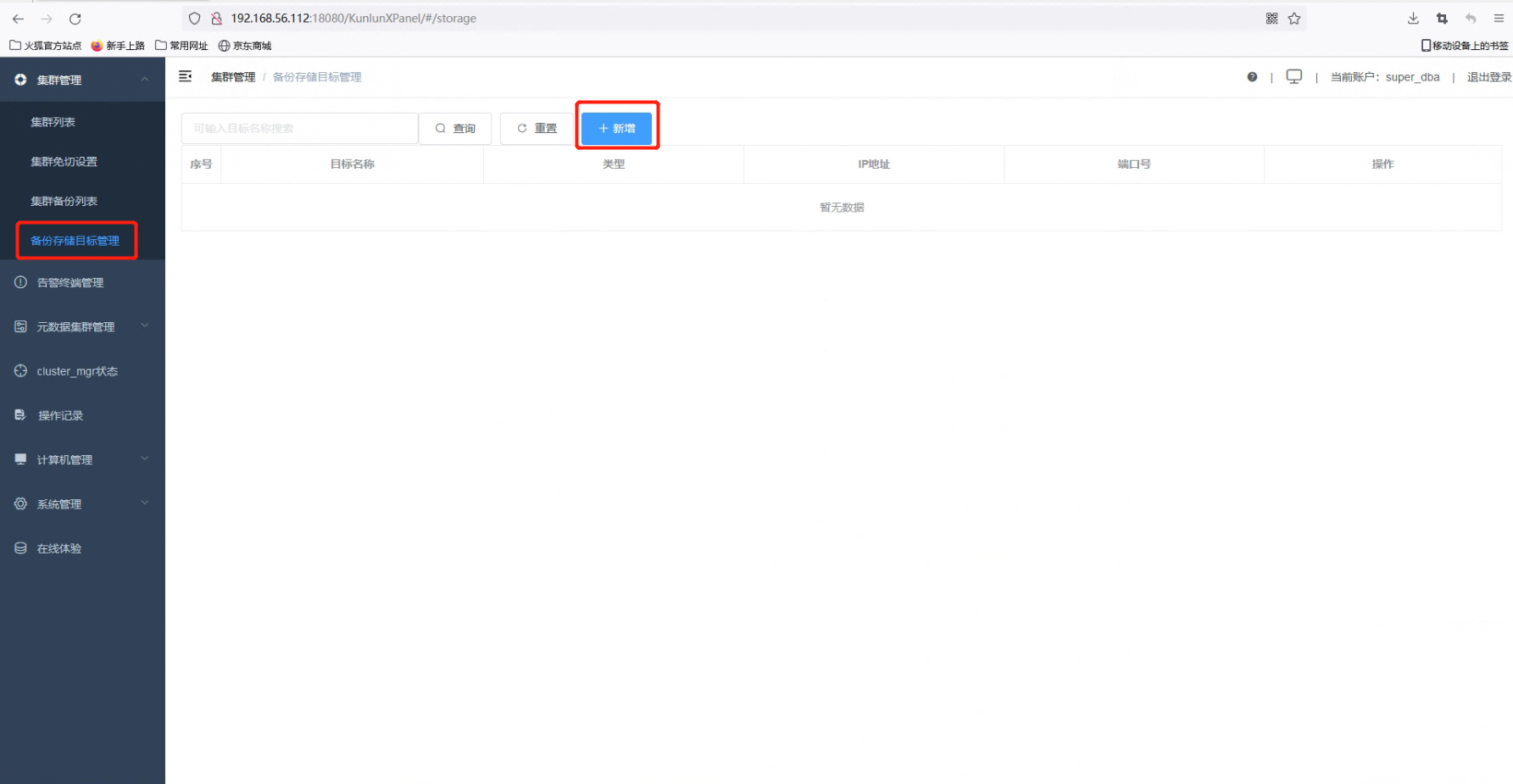
4.2 在 “集群设置” 中点击 “备份存储目标管理”,然后点击 “+新增” 按钮。
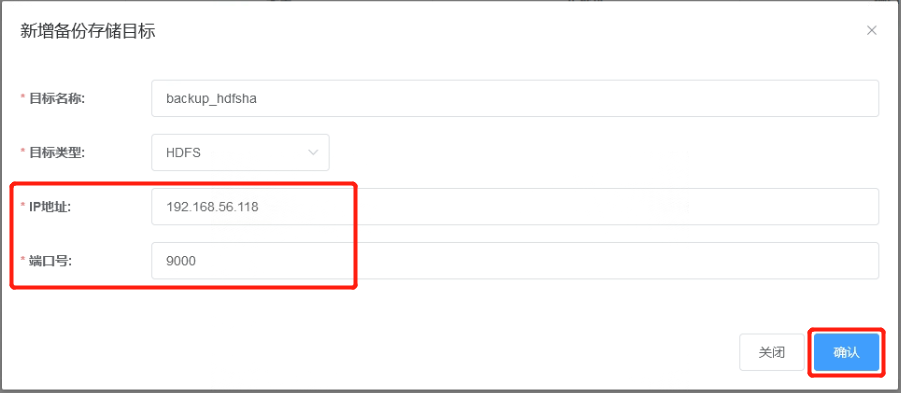
4.3 输入目标名称,目标类型,HDFS 服务器的 IP 地址和端口号,然后点击 “确认” 按钮。
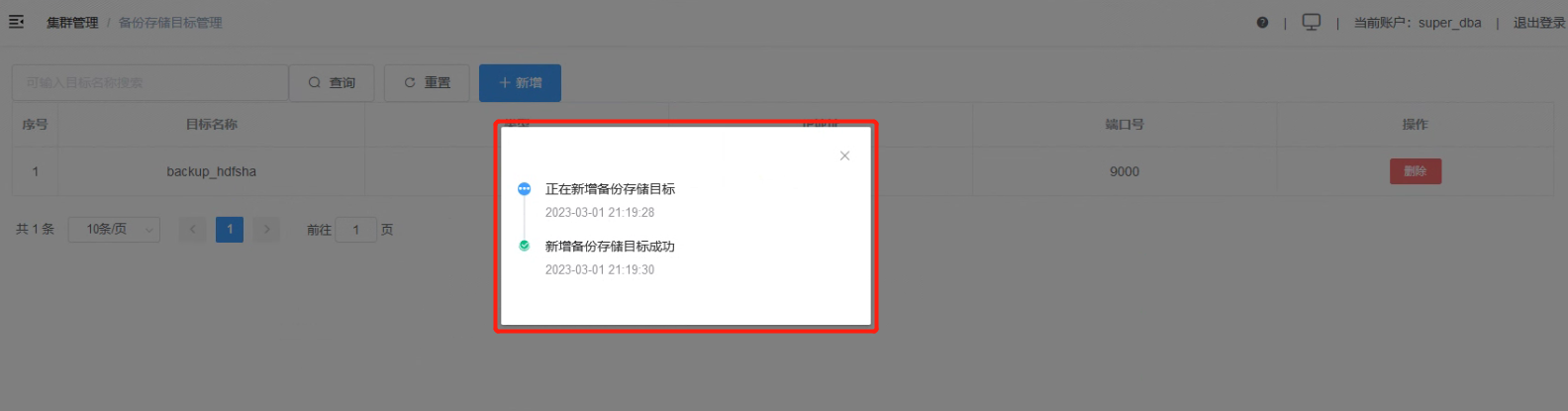
4.4 新增备份存储目标成功。
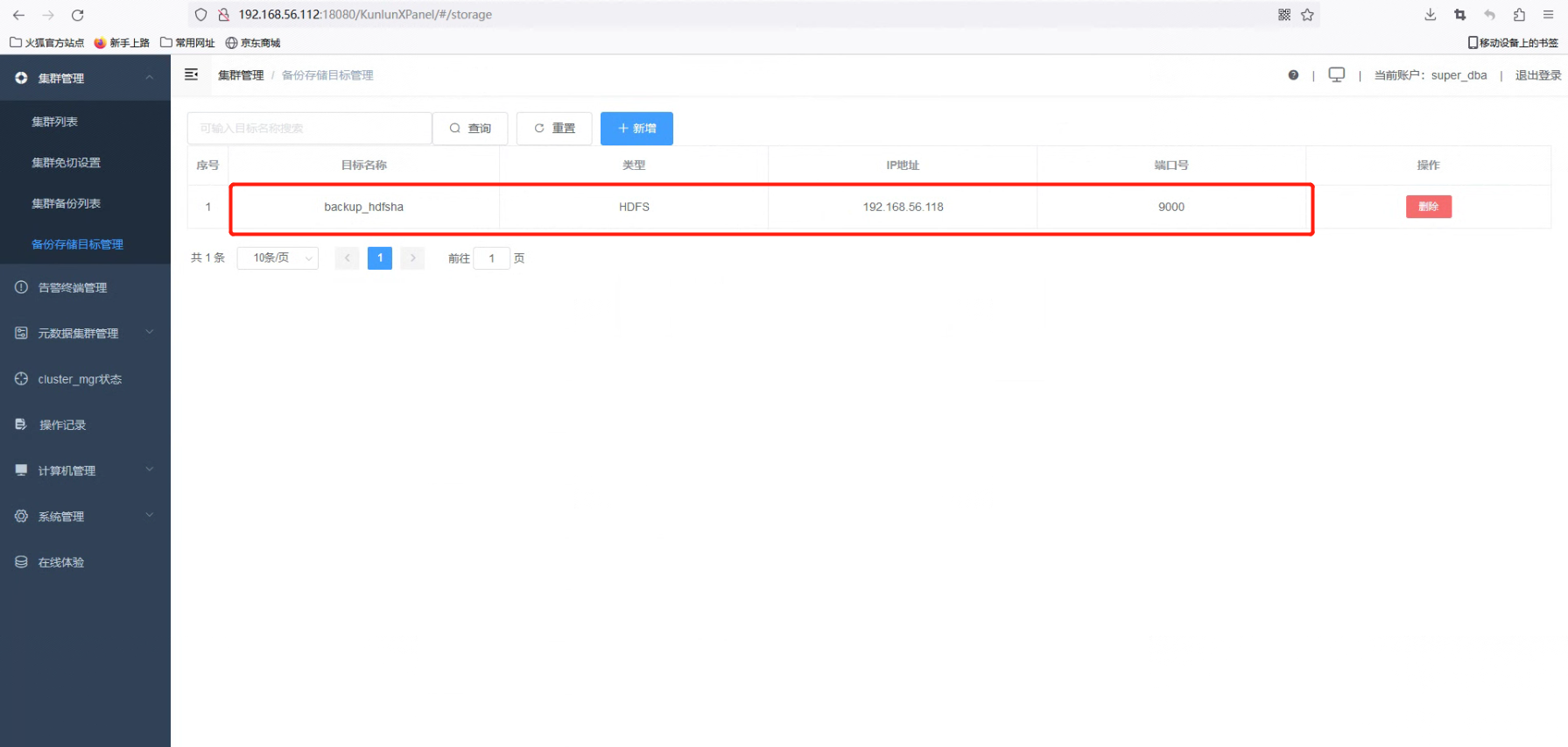
完成 HDFS HA 备份存储目标配置。