
Klustron(原KunlunBase) 数据库服务器集群初始化
Klustron(原KunlunBase) 数据库服务器集群初始化
01 Klustron 集群安装的基本过程
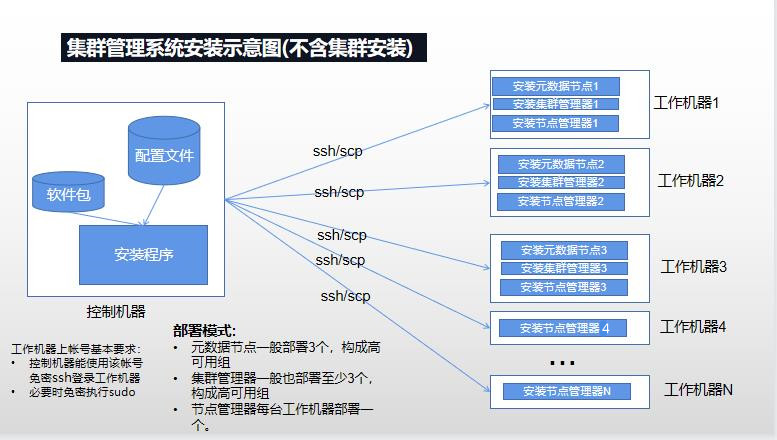
在一组计算机服务器上面安装 Klustron 集群之前, 首先要初始化(bootstrap) 这些计算机服务器。此步骤会把 Klustron 组件安装到每台计算机服务器上面并且确保这些组件可以协同工作,并且配置和启动负责集群管理的相关组件。在初始化完成后,用户就可以使用我们提供的 GUI 工具 XPanel 在这些数据库服务器上面轻松安装若干个 Klustron 集群并且管理这些集群。每台数据库服务器只需要做一次 bootstrap 操作。
本文主要介绍如何初始化数据库服务器,如无特殊说明则适用于 Klustron 所有已发布版本。如果需要用户针对特定版本完成特定操作则文中会有特别说明。关于如何使用XPanel来进行集群管理操作,参见 XPanel 软件使用说明书
- 数据库服务器初始化包括以下简单的步骤:
- 对目标服务器进行必要的环境设置并安装若干个通用的外部组件
- 下载 booststrap 脚本 setup_cluster_manager.py
- 下载 Klustron 发布的组件包
- 使用配置模板文件填写 setup_cluster_manager.py 所需要的配置文件(json格式)
- 运行 setup_cluster_manager.py脚本
setup_cluster_manager.py 初始化数据库服务器的示意图
使用 XPanel 做集群管理和运维的示意图
集群管理和运维操作包括创建集群、增加/删除计算节点/存储节点、增删存储集群、集群物理/逻辑备份和恢复,集群扩缩容,online DDL 和repartition等,并且所有这些操作还可以调用 cluster_mgr API 完成。事实上 XPanel 也是调用 cluster_mgr API 完成这些集群管理操作。
除此之外,用户还可以使用 Klustron 安装的 Prometheus 和 Grafana 来查看集群节点监控状态,使用用户自行安装的 ES 和 Kinaba (Klustron 会自动配置和关联 ES 组件与 Klustron 各组件)查看和检索集群节点运行日志 等。这部分在其他文档中介绍,本文不赘述。

02 基本概念
这部分可以先跳过,在阅读正文时按需查找。对于Klustron略有了解的用户通常无需查阅此列表即可理解正文。
集群管理系统(Cluster Management System - CMS):能够通过集群管理器节点接收来自客户端(这里指 XPanel )的Klustron集群操作请求,以便对Klustron集群进行上述各种集群操作。 集群管理系统包含核心部分和非核心部分。
- 核心部分(CMS core)包含元数据集群和集群管理器组。
- 非核心部分包含被核心部分管理的众多节点管理器。
元数据集群(Metadata shard):由多个存储节点组成的复制组,用于管理Klustron集群的元数据,不用于存储用户业务数据,元数据集群在运行时是一个复制组。可以服务多个Klustron集群。
存储节点(storage node):用于存储用户业务数据,是一个 Klustron-storage 组件的运行实例。若干个存储节点组成一个shard,在shard中作为主节点或者备节点运行。
存储集群(storage shard, 简称shard):一个 Klustron 集群包含一个或者多个 shard, 每个 shard 存储一部分用户数据,不同 shard 存储的用户数据没有交集。每个 shard 有一个主节点和多个备机节点,主备节点通过 binlog 复制实现高可用。
计算节点(Computing Node):用于处理用户业务数据请求的节点,计算节点接收用户业务数据请求,进行相应处理,并将需要存储的内容发送给存储节点,返回处理结果给用户。 当前一个计算节点就是一个 Klustron-server 组件的运行实例。
Klustron集群(Klustron Cluster):包含若干个计算节点和若干个shard 的节点集合。
集群管理器(Cluster Manager, cluster_mgr):该节点负责接收客户端的Klustron集群操作和管理请求,通过将实际动作发送给各个节点管理器,来完成请求。
集群管理器组(Cluster Manager Group):由至少三个集群管理器构成的高可用组,其中具有 LEADER 角色的集群管理器将实际处理客户端的Klustron集群操作请求。可以服务多个Klustron集群。
节点管理器(Node Manager):每台工作机器都需要部署的一个的本地命令执行节点,该节点将接收来自集群管理器的请求,针对存储节点、计算节点、以及 Klustron 在本机的其他组件执行各种操作,包括但不限于安装,删除,停止,备份等。
工作机器(Working Machine):可以是一台物理机或一台虚拟机,其上将运行元数据节点或者存储节点或者计算节点。
XPanel: 一个 Web 应用程序,运行在 docker 镜像中,用户可以使用浏览器连接 XPanel 来执行集群管理操作。
03 功能说明
本脚本分为五种执行动作:下载,安装,停止,启动,删除,脚本每次运行都执行其中一种动作,一次动作执行中可以完成多项任务:
下载动作(download):该动作需要在安装前执行,用于下载安装动作所需要的软件包。当前下载动作默认会检查文件是否存在,并跳过已经存在的文件,可以用--overwrite选项来修改该行为,开启强制覆盖。
安装动作(install):该动作中可以执行集群管理系统核心,一个或多个节点管理器的安装,每次可以安装两种对象的一种或多种,只要遵循以下要求:
- 集群管理系统核心必须在第一次安装动作中执行,且只能安装一次
启动动作(start):该动作可以启动集群管理核心,节点管理器。通常用于机器重启或机房断电重启后,也用于手动停止后需要重新拉起的情形。类似停止动作,启动动作也具有一些特点和建议:
- 节点管理器会自动启动其管理的所有元数据节点,存储节点和计算节点。所以启动整个系统,仅需要启动所有节点管理器和集群管理器即可,无需一个个启动Klustron集群。
停止动作(stop):该动作可以停止节点管理器和停止集群核心。 停止动作主要有以下特点和建议:
- 停止节点管理器将停止该工作机器上其管理的所有存储节点,计算节点和元数据节点。因此停止节点管理器一般和停止集群核心一起使用或者机器需要维护时使用,否则有可能导致Klustron集群或集群核心工作不正常。
- 停止集群管理核心将使得所有Klustron集群处于无法正常使用的状态,所以停止集群管理核心一般是需要运维所有Klustron集群时才使用。
清理动作(clean):该动作可以清理节点管理器,和清理整个集群管理系统。清理动作主要有以下特点:
- 清理节点管理器,将清理对应机器上其管理的所有元数据节点,存储节点和计算节点,所以清理节点管理器一般在清理整个系统中使用。
- 清理集群管理核心。仅在清理整个系统中才执行。
- 命令也常用于安装失败后的处理,即安装失败查明原因(比如选择的端口被占用,磁盘空间不足等)后,使用清理删除安装产生的遗留,而后修复问题(比如修改配置文件,清理出空间),重新执行安装动作。
本脚本用于以下场景:
安装集群管理系统核心
在集群管理核心安装的同时或之后可以多次执行以下功能
- 初始化工作机器,包括安装 Klustron 的节点管理器及其他组件
- 必要时停止节点管理器以便对对应的工作机器进行运维操作,运维完毕后重新启动节点管理器。
启动集群管理系统
- 例如如果遇到机房断电这种大范围故障,则在故障后需要如此。
当所有的Klustron集群和集群管理系统都不需要时,清理整个集群管理系统和数据库服务器上所有集群计算节点和存储节点。
- 执行此步骤务必小心,因为没有任何权限检查和较验,执行后也没有办法撤销
集群安装涉及的所有机器分为两类:
工作机器,安装系统各种节点和Klustron集群各种节点的机器,从控制机器接受指令来完成所安排的动作。一般有多台工作机器。当前本文涉及的安装脚本要求所有工作机器具有统一的处理器架构, 且该架构在支持列表之中。当前支持的架构有x86_64和aarch64(即arm64)。龙芯的loongarch64架构,暂时不支持。
控制机器,即运行安装脚本所在机器。在该机器上,需要从 gitee 下载安装脚本和从 Klustron下载站点 下载相关软件包,而后该机器将对工作机器发出各种命令来安装节点。在实际部署中,一般选择众多工作机器中的一台,作为控制机器。当然,也可以选择工作机器之外的某台机器作为控制机器。
04 服务器建议配置
4.1 开发和测试环境
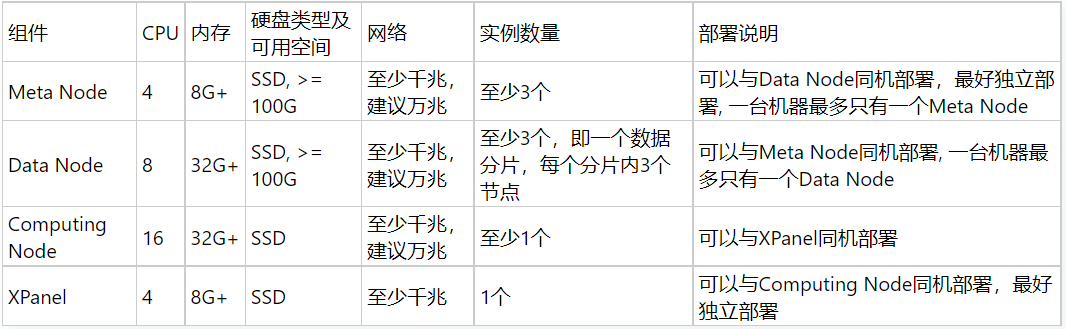
对于开发和测试环境,建议至少使用三台机器,每台机器上可以部署多种类型的组件, 以下是各种组件的具体要求:

4.2 生产环境
对于生产环境,至少需要4台机器,机器资源足够时,建议使用8台机器,以下是各种组件的具体要求:
05 准备工作
安装前确认 - 工作机器(参见前面示意图)
所有需要安装节点(核心部分节点,非核心部分节点)的机器都是工作机器。
配置时间服务,保证各个节点时间戳同步,比如在centos7上,可以这样做:
sudo yum install -y chrony
sudo timedatectl set-timezone Asia/Shanghai
sudo systemctl enable chronyd
sudo systemctl start chronyd
- 要么关闭防火墙,要么需要对安装在该台机器上的所有类型的节点指定的所有监听端口(包括默认端口,参见配置文件详细说明)设置防火墙允许的规则。比如,可以用 root 用户运行以下命令关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
每台工作机器需要安装 python2或者python3, 并且 python或python2或python3 在使用指定用户名非交互式登陆后的 PATH 中能被找到. 当前的查找顺序为python -> python2 -> python3. 下面以安装python2为例:
- 对于 Centos7,运行命令: yum install python
- 对于 Centos8/Kylin V10, 运行命令: yum install python2
- 对于 Ubuntu 20.04 及以上版本,运行命令: apt install python2
- 对于 opensuse 15,运行命令: zypper install -y python2
- 其他系统需要在 python 官网上或操作系统官网上查阅python2的安装文档。
- python3的安装方式类似,需要在python官网或操作系统官网上查找python3的安装文档
每台机器安装aio库,和en_US.UTF-8语言包,保证各组件能够正常启动。比如在centos7/8上,相应的命令为:
[root@kunlun-test2]# yum install -y libaio libaio-devel glibc-langpack-en
- 在每台机器上创建一个用户(各台机器可以不同,但建议统一,本文中标记该用户名为kunlun)用于运行Klustron 的所有的相关程序, 并为该用户设置密码。这里称为工作用户,该用户名对应后续机器配置中的user属性:
[root@kunlun-test3 /]# useradd --create-home --shell /bin/bash kunlun
[root@kunlun-test3 /]# passwd kunlun
强烈建议系统管理员在部署Klustron集群的各个服务器上面创建专用的操作系统用户用于启动和运行Klustron 各个组件,而不是使用现有的操作系统用户。并且Klustron的各组件的数据目录的所有者也将是这个用户。这样才符合Klustron的数据安全的基本条件。
- 为该工作用户临时增加免密执行sudo的权限,该权限在Klustron集群初始化完毕后即可撤销
比如,用root进行以下操作来为上述 kunlun用户设置免密sudo:
vi /etc/sudoers
#在最后加上下面的内容:
Kunlun ALL=(ALL) NOPASSWD: ALL
仅在要安装Klustron集群的所有服务器上面安装Klustron集群期间临时需要免密sudo的权限,因为Klustron安装工具需要在安装Klustron集群期间,copy Klustron组件的文件到这些服务器上面,以及ssh连接到各个服务器执行如下段所述的一些命令。当Klustron集群安装完成后,可以在所有这些服务器上撤销kunlun用户的免密sudo权限。
当前安装工具会自动在每台工作机器上创建工作目录(即JSON配置文件模板中的 machines配置里面的basedir), 以及修改目录Owner等操作, 当传递了--sudo给安装工具(setup_cluster_manager.py), 它就会以sudo的方式执行这些特权命令,以避免安装过程因为指定的kunlun 用户权限不足而失败。 如果在部署Klustron集群的各个服务器上面,设置的工作目录(basedir), 都是kunlun用户(即machines配置里面指定的user)具有权限去创建和管理的,那么这个kunlun用户可以不需要设置免密sudo。
另外,安装 XPanel 的服务器上面需要运行docker, 所以需要在这台机器上给kunlun 用户添加免密运行docker的sudo权限,而不需要完整的免密sudo权限。并且此权限需要始终保留,安装完成后不能撤销。
- 建议在每台机器上创建一个空目录(建议为 /kunlun ), 并且将该目录的 owner 设置为前面创建的工作用户名。该目录对应后续机器配置中的 basedir 属性。
[root@kunlun-test3 /]# mkdir -p /kunlun
[root@kunlun-test3 /]# chown -R kunlun:kunlun /kunlun
- 确保对应用户的最大文件打开数设置足够,以保证程序不会因为文件句柄资源数不足而工作不正常。一般建议的数值最少为 65536。在机器上可以使用 ulimit -n 来显示当前用户的打开数设置,当显示的值 <63336 时,一般建议将以下行加入 /etc/security/limits.conf 中:
* soft nofile 65536
* hard nofile 200000
- 对于安装XPanel或ElasticSearch/Kibana的机器,除了python2/python3外,还需要安装docker(20以上)。关于Docker安装,可以参见docker engine安装的官方文档: https://docs.docker.com/engine/install 。比如对于centos7可以这样安装docker:
$ sudo yum remove docker docker-client docker-client-latest docker-common docker-latest \
docker-latest-logrotate docker-logrotate docker-engine
$ sudo yum install -y yum-utils
$ sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
$ sudo yum install docker-ce docker-ce-cli containerd.io docker-compose-plugin
- 安装docker之后,还需要启动 docker,并设置其随操作系统自启动,比如可以这样做:
systemctl enable docker
systemctl start docker
安装前确认 - 控制机器(参见前面示意图)
- 该机器需要安装 python2/python3。Python2 安装方式参见前面。
- 需要安装git/wget. 例如在centos7/8上可以这样做:
yum -y install git wget
在控制机器上选择一个已有用户或者新创建一个用户作为控制用户。后续各种控制操作,都使用该用户执行。虽然允许,但一般不建议使用root作为控制用户。当控制机器本身也是工作机器时,一般建议使用前面创建出来的工作用户作为控制用户。
确保在控制机器上的控制用户 能够使用指定账户(工作机器上创建的用户, 比如前面的kunlun,在配置文件中指定)通过ssh免密登录到所有安装涉及的工作机器上(如果本机同时也是工作机器,则也包含本机)。比如centos7/8上,可以这样做:
# 产生rsa公私钥对,如果$HOME/.ssh已有该公私钥对,则此步可以省略。
[kunlun@kunlun-test12 ~]# ssh-keygen -t rsa
... 命令输出省略, 提示输入passphrase时,直接回车 ...
# 设置当前机器当前用户(这里是kunlun)到kunlun@192.168.0.125的免密ssh登录(注意,此步需要知道相应的登录密码)
# 注意目标机器是本机时,应使用本机在集群中的ip地址,而不要使用localhost或127.0.0.1, 除非其在集群中的地址就是localhost或者127.0.0.1
[kunlun@kunlun-test12 ~]# ssh-copy-id -i .ssh/id_rsa.pub kunlun@192.168.0.125
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: ".ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
kunlun@192.168.0.125's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'kunlun@192.168.0.125'"
and check to make sure that only the key(s) you wanted were added.
控制机器上的控制用户的公钥文件,需要始终存在于Klustron集群所部署的所有服务器,这样才可以执行集群整体或者其中部分组件的启停等操作。
登录到控制机器,切换到控制用户,从gitee上拉取安装脚本, 而后下载软件包
- 从gitee上拉取安装脚本并运行脚本下载软件包:
cd $HOME
git clone -b v1.3.2 https://gitee.com/zettadb/cloudnative.git
cd $HOME/cloudnative/cluster
mkdir -p clustermgr
# 由于官网下载站 downloads.Klustron.com 的网络带宽有限,下载速度慢,所以这里选择从公司对外公开的研发下载站 http://klustron.cn:14000/ 下载
# 如果所有工作机器的处理器指令集属于x86_64,主要是Intel, AMD, 海光,兆芯等, 则下载x86_64指令集对应的软件包
python setup_cluster_manager.py --action=download --downloadsite=devsite --downloadtype=release --targetarch=x86_64
# 否则,如果所有工作机器的处理器指令集属于aarch64指令集,主要是鲲鹏,飞腾,阿里倚天等。则下载aarch64指令集对应的软件包。
python setup_cluster_manager.py --action=download --downloadsite=devsite --downloadtype=release --targetarch=aarch64
06 示例安装
这里给出一个最简集群管理系统的安装示例, 使用三台机器(192.168.0.110/111/100)作为工作机器。 具体部署为:
- 其中元数据节点和集群管理器节点每台机器上部署一个, 元数据集群使用 rbr(即Klustron自研的FullSync) 作为复制方式。
- 每台机器上都部署有一个节点管理器和集群管理器
- XPanel 部署在第一台机器(192.168.0.110)上
- ElasticSearch/Kibana 部署在第二台机器(192.168.0.111)上
- 第三台工作机器(192.168.0.100)同时也作为控制机器
- 工作用户和控制用户都是 kunlun, 所以需要在 192.168.0.100 上的 kunlun 用户下,配置到 kunlun@192.168.0.110, kunlun@192.168.0.111 和 kunlun@192.168.0.100 的免密 ssh 登录。
6.1 编辑配置文件
注:配置文件的详细规格要求将在后面说明,本处给出的是框架性的规格说明。
配置包含以下几个部分:
机器配置(machines), 用于设置工作机器上的工作目录以及连接信息等,所有的工作机器都应当有相应的条目。
集群管理系统核心的相关配置,主要有:
- meta: 用于设置元数据集群, 作为集群管理系统的数据核心,存储管理系统中的所有数据,为系统中的所有Klustron集群共用。应该至少配三个,以保证高可用, 本例配置3个。
- cluster_manager: 集群管理器的配置,如果机器数至少有三台,则一般建议至少配三个节点,以保证高可用,否则一般配一个。 本例配置3个。
node_manager: 节点管理器的配置,所有集群Klustron集群涉及的工作机器,都应配置一个条目。本例在三台机器上安装Klustron集群,所以配置 3 个。
xpanel: XPanel 的设置,最后的 XPanel 地址为
http://${xpanel.ip}:${xpanel.port}/KunlunXPanel, 这里 xpanel.port 使用了默认值18080elasticsearch: 设置ElasticSearch/Kibana, 其中ElasticSearch使用默认的9200端口,Kibana使用默认的5601端口
配置文件中各元素和属性,通常都带有默认值,如果该属性或元素没有设置,则一般使用默认值。
根据具体部署说明和配置文件说明,在多数元素使用默认值的情况下,最后的配置文件内容可以为(即其中的 cluster_and_node_mgr.json 文件):
{
"machines":[
{
"ip":"192.168.0.110",
"basedir":"/kunlun",
"user":"kunlun"
},
{
"ip":"192.168.0.111",
"basedir":"/kunlun",
"user":"kunlun"
},
{
"ip":"192.168.0.100",
"basedir":"/kunlun",
"user":"kunlun"
}
],
"meta":{
"ha_mode": "rbr",
"nodes":[
{
"ip":"192.168.0.110"
},
{
"ip":"192.168.0.111"
},
{
"ip":"192.168.0.100"
}
]
},
"cluster_manager": {
"nodes": [
{
"ip": "192.168.0.110"
},
{
"ip": "192.168.0.111"
},
{
"ip": "192.168.0.100"
}
]
},
"node_manager": {
"nodes": [
{
"ip": "192.168.0.110"
},
{
"ip": "192.168.0.111"
},
{
"ip": "192.168.0.100"
}
]
},
"xpanel": {
"ip": "192.168.0.110",
"image": "registry.cn-hangzhou.aliyuncs.com/kunlundb/kunlun-xpanel:VERSION"
},
"elasticsearch": {
"ip": "192.168.0.111"
}
}
6.2 执行具体动作
注:操作同一批对象的各个动作,一般应该使用同一个配置文件
安装
cd $HOME/cloudnative/cluster
python setup_cluster_manager.py --autostart --config=cluster_and_node_mgr.json --action=install
bash -e clustermgr/install.sh
使用 XPanel 操作集群,即使用浏览器( firefox/edge/chrome )打开如下网址
http://192.168.0.110:18080/KunlunXPanel
如果出错后,在查明错误原因并修复问题后,需要清理后,重新执行安装,清理命令为:
cd $HOME/cloudnative/cluster
python setup_cluster_manager.py --autostart --config=cluster_and_node_mgr.json --action=clean
bash clustermgr/clean.sh
6.3 安装错误日志查看
在使用上述 json 文件进行安装,出现安装错误时,除了 clustermgr/install.sh 脚本在执行过程中显示的日志信息外,对于节点安装错误的情形,通常还需要查看该节点的日志文件,才能知道安装失败的具体原因。
本例中,对于元数据节点而言,节点日志文件路径为安装失败机器上的:BASEDIR/storage_logdir/PORT/mysqld.err, 其中 BASEDIR 为 machines 里对应机器条目下的 basedir 属性, 而 PORT 则是该元数据节点或存储节点配置的监听端口( port 属性)。 比如对于第二个元数据节点安装失败的情形,则其对应的日志文件路径为 192.168.0.111 这台机器上的
/home/kunlun/basedir/storage_logdir/6002/mysqld.err本例中, 对于集群管理器而言, 其日志文件所在目录为:
BASEDIR/kunlun-cluster-manager-$VERSION/log, 其中,BASEDIR 如前所述,$VERSION表示产品版本号,前面下载软件包时提到过。 里面一般有若干个日志文件,不同的文件名前缀表示不同功能的日志。本例中, 对于节点管理器而言, 其日志文件所在目录为:
BASEDIR/kunlun-node-manager-$VERSION/log, 其中,BASEDIR 如前所述,$VERSION表示产品版本号,前面下载软件包时提到过。里面一般有若干个日志文件,不同的文件名前缀表示不同功能的日志。由于这里安装了elasticsearch/kibana, 所以也可以通过Kibana来查看所有节点的日志信息, 即通过
http://${elasticsearch.ip}:${elasticsearch.kibana_port}来查看各种日志信息, 此处的elasticsearch.kibana_port端口为默认的5601
07 拓展内容
7.1 setup_cluster_manager.py 的命令行参数
setup_cluster_manager.py 的命令行参数
- 当前 setup_cluster_manager.py 支持的参数为:
usage: setup_cluster_manager.py [-h] [--config CONFIG]
[--action {download,install,clean,start,stop}]
[--product_version PRODUCT_VERSION] [--defuser DEFUSER] [--defbase DEFBASE]
[--pyexec {none,python2,python3}] [--autostart] [--sudo] [--verbose]
[--small] [--setbashenv]
[--defbrpc_http_port_clustermgr DEFBRPC_HTTP_PORT_CLUSTERMGR]
[--defbrpc_raft_port_clustermgr DEFBRPC_RAFT_PORT_CLUSTERMGR]
[--defpromethes_port_start_clustermgr DEFPROMETHES_PORT_START_CLUSTERMGR]
[--defbrpc_http_port_nodemgr DEFBRPC_HTTP_PORT_NODEMGR]
[--deftcp_port_nodemgr DEFTCP_PORT_NODEMGR]
[--defstorage_portrange_nodemgr DEFSTORAGE_PORTRANGE_NODEMGR]
[--defserver_portrange_nodemgr DEFSERVER_PORTRANGE_NODEMGR]
[--defprometheus_port_start_nodemgr DEFPROMETHEUS_PORT_START_NODEMGR]
[--defraft_port_cdc DEFRAFT_PORT_CDC] [--defhttp_port_cdc DEFHTTP_PORT_CDC] [--download]
[--downloadsite {public,devsite,internal}]
[--downloadtype {release,daily_rel,daily_debug}] [--targetarch TARGETARCH] [--overwrite]
[--multipledc]
Specify the arguments.
optional arguments:
-h, --help show this help message and exit
--config CONFIG The config path
--action {download,install,clean,start,stop}
The action
--product_version PRODUCT_VERSION
kunlun version
--defuser DEFUSER the default user
--defbase DEFBASE the default basedir
--pyexec {none,python2,python3}
specify the python version to use
--autostart whether to start the cluster automaticlly
--sudo whether to use sudo
--verbose verbose mode, to show more information
--small whether to use small template
--setbashenv whether to set the user bash env
--defbrpc_http_port_clustermgr DEFBRPC_HTTP_PORT_CLUSTERMGR
default brpc_http_port for cluster_manager
--defbrpc_raft_port_clustermgr DEFBRPC_RAFT_PORT_CLUSTERMGR
default brpc_raft_port for cluster_manager
--defpromethes_port_start_clustermgr DEFPROMETHES_PORT_START_CLUSTERMGR
default prometheus starting port for cluster_manager
--defbrpc_http_port_nodemgr DEFBRPC_HTTP_PORT_NODEMGR
default brpc_http_port for node_manager
--deftcp_port_nodemgr DEFTCP_PORT_NODEMGR
default tcp_port for node_manager
--defstorage_portrange_nodemgr DEFSTORAGE_PORTRANGE_NODEMGR
default port-range for storage nodes
--defserver_portrange_nodemgr DEFSERVER_PORTRANGE_NODEMGR
default port-range for server nodes
--defprometheus_port_start_nodemgr DEFPROMETHEUS_PORT_START_NODEMGR
default prometheus starting port for node_manager
--defraft_port_cdc DEFRAFT_PORT_CDC
default raft_port for cdc
--defhttp_port_cdc DEFHTTP_PORT_CDC
default http_port for cdc
--download whether to download before install operation
--downloadsite {public,devsite,internal}
the download base site
--downloadtype {release,daily_rel,daily_debug}
the packages type
--targetarch TARGETARCH
the cpu arch for the packages to download/install
--overwrite whether to overwrite existing file during download
--multipledc whether used for installation in multiple datacenters
主要参数介绍如下:
--config CONFIG 参数文件的路径,当action不是download时,是必须项
--action {install,clean,start, stop, download} : 指定动作,当前支持 install,clean,start,stop, download 必须项
--product_version PRODUCT_VERSION: 产品版本,不指定则当前默认为 1.3.2
--defuser DEFUSER: 指定连接机器的默认用户名,不指定该选项则默认为 kunlun
--defbase DEFBASE: 指定默认工作目录,当相应机器该设置时,则使用默认工作目录,不指定该选项则默认为 /kunlun,若指定,则必须是绝对路径。
--pyexec {none,python2,python3}: 指定python程序的版本,默认为none, 表示选择顺序为python -> python2 -> python3, 可以修改该选项来指定python版本。
--autostart: 指定是否开启自启动,即机器重启后,进程将会自动被拉起,不传入该参数时,默认为false,即不开启自启动。
--sudo : 是否使用 sudo 来运行必要命令,当用户没有权限创建相应目录时,就需要使用 sudo 了,需要用户运行免密 sudo,默认为否
--verbose : 是否在执行操作时,显示更详细的信息。默认只显示阶段性信息,不显示每条执行的命令。
--small: 是否使用 template-small.cnf 来安装元数据节点,默认是否[false]
--setbashenv 是否修改用户 $HOME 目录下的 .bashrc, 以辅助 DBA 的手动操作。使用该选项可能会影响工作机器上对应用户下的 bash 环境变量,一般不设置 [false]
--defbrpc_http_port_clustermgr DEFBRPC_HTTP_PORT_CLUSTERMGR: cluster_mgr 节点默认的 brpc_http_port [58000]
--defbrpc_raft_port_clustermgr DEFBRPC_RAFT_PORT_CLUSTERMGR: cluster_mgr 节点默认的 brpc_raft_port [58001]
--defpromethes_port_start_clustermgr DEFPROMETHES_PORT_START_CLUSTERMGR: cluster_mgr 默认的 prometheus 端口 [59010]
--defbrpc_http_port_nodemgr DEFBRPC_HTTP_PORT_NODEMGR: node_mgr 节点默认的 brpc_http_port [58002]
--deftcp_port_nodemgr DEFTCP_PORT_NODEMGR: node_mgr 节点默认的 tcp_port [58003]
--defstorage_portrange_nodemgr DEFSTORAGE_PORTRANGE_NODEMGR: 存储节点的端口范围,用于自动指定端口。[57000-58000]
--defserver_portrange_nodemgr DEFSERVER_PORTRANGE_NODEMGR: 计算节点的端口范围,用于自动指定端口。[47000-48000]
--defprometheus_port_start_nodemgr DEFPROMETHEUS_PORT_START_NODEMGR: node_mgr默认的 prometheus 端口 [58010]
--defraft_port_cdc DEFRAFT_PORT_CDC:指定cdc节点中raft协议默认监听端口 [58004]
--defhttp_port_cdc DEFHTTP_PORT_CDC: 指定cdc节点中http协议默认监听端口 [58005]
--download: 在install动作中,是否自动执行下载动作,默认false,表示下载与安装分离,以便在安装前对下载内容进行定制化。
--downloadsite {public,devsite,internal}: 指定下载站点,一般服务器在境外则使用public(默认), 在境内建议使用devsite, internal仅用于内部测试。
--downloadtype {release,daily_rel,daily_debug}: 指定软件包类型,一般建议使用release(默认), 表示使用正式发布版本。 daily_rel和daily_debug仅用于内部测试和Beta客户测试。
--targetarch TARGETARCH: 指定软件包架构,当前仅支持x86_64和aarch64, 默认值为运行该脚本所在机器的处理器架构。
--overwrite: download动作时,文件存在是否覆盖,默认为false。
--multipledc: 是否采用多DC模式,默认false。
7.2 关于自启动
当开启自启动后,相关的进程将会以服务的形式安装进入系统,主要具有以下特征和要求:
- 机器发生重启后,相关进程会被自动拉起。
- 配置文件中的全局配置中设置autostart为true或者给setup_cluster_manager.py传递--autostart选项,均可开启自启动。一般建议使用前者,后者为兼容性而保留。
- 如果仅使用--autostart选项来开启自启动,则该选项应该在各个步骤中保持一致:
- 当安装(install)使用 --autostart 选项后,其他所有动作 start/stop/clean 也需要使用 --autostart 选项,才能正常工作。
- 反之,安装没有使用 --autostart 选项,其他所有动作也不应当使用 --autostart 选项。
7.3 关于设置用户登录环境变量
当给 setup_cluster_manager.py 传递 --setbashenv 时,将会设置用户登录时的环境变量中的 PATH 和 LD_LIBRARY_PATH 等,加入 Java 和 Hadoop 的路径。这样用户在使用交互式 bash 时,hadoop 会在 PATH 中。 使用该选项需要注意:
该选项会修改交互式 bash 的环境变量,所有用此账户登录该机器的使用者都会受影响,尤其是当其中已经设置好 java 和 hadoop 时,先前设置好的会被覆盖。
该选项应该在各个步骤中保持一致:
- 当安装(install)使用 --setbashenv 选项后,clean 也需要使用 --setbashenv 选项,这样install设置的环境变量才会被清理。
- 反之,安装没有使用 --setbashenv 选项,clean 动作也不应当使用 --autostart 选项。
- 同台机器上的一对安装 install 和 clean 动作之间,不应该有其他安装中的 install 和 clean 动作出现, 否则该机器上此次的变量设置可能会被覆盖或者清除。
7.4 配置文件详细说明
7.4.1 配置文件用于声明需要操作的对象,是一个 json 对象文件,该 json 对象具有以下一级属性:
machines: 数组类型,用来指定工作机器的连接信息和工作目录。这是一个 json 数组,每个成员用来标识一台工作机器。建议为每台工作机器都设置一个成员。每个成员具有的属性有:
ip:字符串类型,必填项,为工作机器的地址,可以是 ipv4 的地址也可以是 ipv6 的地址,或者 dns 地址,该地址将作为该工作机器的唯一标识。同台机器应当在整个配置文件中使用同一个地址。如果同台机器使用了多个地址(比如 ipv4 和 ipv6 地址),则被认为是多台机器。
basedir:字符串类型,该工作机器上的工作目录,必须是绝对路径,该工作目录将用于存放各种类型节点的程序包以及各种动作辅助文件。工作目录默认为 "/kunlun" , 可以通过给 setup_cluster_mananger.py 传递 --defbase 来更改这两个默认值。
sshport: 整型,该机器上 ssh server 的监听端口,默认为 22。
user:指定控制机器用于连接工作机器所使用的用户名,该用户名必须在工作机器上存在,包含安装各种类型节点在内的后续动作基本都使用该用户执行,所以该用户需要有足够的权限,权限方面具有以下特点和要求:
- 如果运行 setup_cluster_manager.py 时没有传递 --sudo 和 --autostart 选项,则执行动作不会使用 sudo,所以要求该用户对配置文件中所有目录具有完整权限,最好是这些目录的 owner. 如果某个目录不存在则要求用户有权限创建该目录。
- 如果运行 setup_cluster_manager.py 是传递了 --sudo 或 --autostart,则必要时使用 sudo 执行命令,此时要求 root 用户具有权限创建这些目录,正常而言,只要不是特殊位置的目录,一般都没问题。 这要求用户具有免密执行 sudo 的权限。
- 该属性值默认是 "kunlun" , 可以通过给 setup_cluster_manager.py 传递 --defuser 选项来更改这个默认值。
- 由于计算节点无法以 root 用户启动,所以要求该属性值不能是 "root"
如果在配置文件其他位置出现的某个工作机器地址,在 machines 中没有对应条目,则脚本会在运行时使用该地址创建一个 user 和 basedir 全部使用默认值的条目。 所以,如果该工作机器上的工作目录和用户与默认值不同的话,必须设置对应条目,本脚本才能正常工作。
config: 对象类型,可选属性,用来对安装进行全局配置。当前具有以下属性:
- autostart: 布尔类型,指定是否开启自启动(即安装系统服务,以便系统重启后,相关进程能够启动启动), 默认为false。
- sudo: 布尔类型,指定是否使用sudo来执行若干命令,当指定user没有权限访问(包括创建)basedir时,将会使用sudo来执行命令。autostart开启会自动开启sudo。默认false。
- enable_rocksdb: 布尔类型,指定是否全局开启rocksdb, 默认值为true。当前,当工作机器中有arm64的机器时,需要设置该值为false,全局范围内关闭rocksdb。
datacenters: 数组类型,用来指定数据中心的信息,该属性只有在多DC模式时才需要设置,普通模式时被忽略。属性值是一个 json 数组,每个成员用来标识一个数据中心,具有的属性为:
- name: 字符串类型,表示数据中心的名字,后续需要引用dc的时候,都是用这里或以前安装使用的名字
- province: 字符串类型,表示数据中心所在的省份,一般建议用小写拼音
- city: 字符串类型,表示数据中心所在的城市,注意只有两个数据中心所在的省份和城市都相同时,两个数据中心才被认为是同城,一般建议用小写拼音
- is_primary: 布尔类型,是否是主数据中心,只能有一个主数据中心。在首次安装时,必须有且只有一个数据中心被设置为主数据中心。
- skip: 布尔类型,默认为false, 当值为true时表示该dc已经安装过了(比如后续给每个DC增加机器),这里仅做说明目的,此时只有name是必须的。
meta:对象类型,指定元数据集群的安装信息,主要具有以下属性:
- ha_mode: 字符串类型,指定元数据节点之间的复制模式,建议明确设置模式,而不依赖于默认值。在1.0及以前一般建议为'mgr', 从1.1开始一般建议设置为 'rbr', 当前默认值为 'rbr' .
- enable_rocksdb: 布尔类型,指定元数据集群是否开启rocksdb支持,默认为true。当安装元数据集群的机器中,有不支持rocksdb的机器(比如arm芯片的机器),需要显式设置该值为false。
- group_seeds: 字符串类型,指定已经安装的元数据集群的地址,setup_cluster_manager.py 首次执行安装动作时,将会产生该地址值,用于后续操作其他批次对象。 操作元数据集群(比如安装)时,不需要设置该属性,设置也会被忽略。
- nodes: 数组类型,指定元数据集群中每个元数据节点的详细配置, 操作元数据集群时(比如安装),必须设置,否则禁止设置。该属性值是一个 Klustron-storage 对象。Klustron-storage 对象详细说明见后文。
- 操作管理系统核心时,必须设置 nodes 属性,而不是操作管理系统核心时,则必须设置 group_seeds 属性。
node_manager: 对象类型,对象类型,指定节点管理器的相关信息,脚本将根据这些信息在指定的工作机器上安装启动节点管理器进程,并适当设置,使得这些工作机器能被集群管理系统所管理。该属性是一个 json 对象,该 json 对象目前具有以下属性:
nodes: 数组类型,数组中每个成员,都表示与一台工作机器对应的节点管理器信息。当前节点管理器具有以下属性:
- ip: 字符串类型,用于表示节点管理器的工作机器地址,必须设置。
- brpc_http_port: 整数类型,指定节点管理器监听的 http 端口,默认值为 58002,可以通过给 setup_cluster_manager.py 传递 --defbrpc_http_port_nodemgr 来更改该默认值。 正常情况下,只要工作机器上该默认端口没被占用并且被防火墙允许,一般不需要设置。否则需要设置该值。
- tcp_port: 整数类型,指定节点管理器监听的 tcp 端口,默认值为 58003,可以通过给 setup_cluster_manager.py 传递 --deftcp_port_nodemgr 来更改该默认值。 正常情况下,只要工作机器上该默认端口没被占用并且被防火墙允许,一般不需要设置。否则需要设置该值。
- storage_datadirs: 字符串类型,该值是一个逗号隔开的目录列表,其中的每个目录都必须是绝对路径。该值用于节点管理器安装存储节点时,选择存储节点的数据目录。 默认值为 BASEDIR/storage_datadir, 其中 BASEDIR 为该工作机器上的默认工作目录。
- storage_logdirs: 字符串类型,该值是一个逗号隔开的目录列表,其中的每个目录都必须是绝对路径。该值用于节点管理器安装存储节点时,选择存储节点的错误日志目录。 默认值为 BASEDIR/storage_logdir, 其中 BASEDIR 为该工作机器上的默认工作目录。
- storage_waldirs: 字符串类型,该值是一个逗号隔开的目录列表,其中的每个目录都必须是绝对路径。该值用于节点管理器安装存储节点时,选择存储节点的重做日志目录。 默认值为 BASEDIR/storage_waldir, 其中 BASEDIR 为该工作机器上的默认工作目录。
- server_datadirs: 字符串类型,该值是一个逗号隔开的目录列表,其中的每个目录都必须是绝对路径。该值用于节点管理器安装计算节点时,选择计算节点的数据目录。 默认值为 BASEDIR/server_datadir, 其中 BASEDIR 为该工作机器上的默认工作目录。
- 对于 storage_datadirs, storage_logdirs, storage_waldirs, server_datadirs,这四个目录,在生产环境或者性能及压力测试环境中如果需要使用多块磁盘设备来提高 IO 操作的性能,一般需要设置这四个属性到不同的磁盘上。非生产环境使用,则一般不需要,使用默认值即可。
- storage_portrange: 表示供存储节点使用的端口范围,字符串类型,元数据节点没有指定端口时,脚本将在该范围内选择端口,cluster_manager也在该范围内为存储节点选择可用端口. 默认值是 “57000-58000”,可以通过 --defstorage_portrange_nodemgr 来修改该默认值。
- server_portrange: 表示计算节点的端口范围,字符串类型,cluster_manager 从该范围内为计算节点选择端口。 默认值是 “47000-48000”,可以通过 --defserver_portrange_nodemgr 来修改默认值。
- total_cpu_cores: 指定机器的 cpu 数量,整型, 该值默认为 8,如实填写即可。
- total_mem: 用于指定机器的内存数,整型。单位为 MB, 默认值为 16384,如实填写即可。
- nodetype: 用于指定机器的用途,字符串类型,当前有 4 个可选值 'none', 'storage', 'server', 'both', 分别表示该机器将不部署任何节点, 用于部署存储节点,用于部署计算节点,以及用于部署存储和计算节点。该值在机器需要安装设置node_mgr时,必须正确设置,否则通过 cluster_manager 接口安装集群可能失败,该值默认为 both。
- prometheus_port_start: 整数类型,用于指定 node_mgr 的 prometheus 端口,默认为 58010, 可以通过 --defprometheus_port_start_nodemgr 来修改该默认值。
- verbose_log: 布尔类型,默认为false。当设置为true时,该node_mgr管理下的所有存储节点将打开general_log, 所有计算节点将打开enble_sql_log, 只对install动作起作用。
- prometheus_datadir: 字符串类型,指定用于存放prometheus数据的目录,不指定则使用默认的目录。
- dc: 字符串类型,指明该工作机器所属dc,多DC模式时该属性必须设置,普通模式时该值被忽略。
cluster_mamanger:对象类型,指定集群管理器的相关信息。该对象具有以下属性:
nodes: 数组类型,指定集群管理器组的各个节点,每个数组成员都表示一个集群管理器节点对象, 其中每个集群管理器节点具有以下属性:
- ip: 字符串类型,用于表示集群管理器的工作机器地址,必须设置。
- brpc_http_port: 整数类型,指定集群管理器监听的 http 端口,默认值为 58000,可以通过给 setup_cluster_manager.py 传递 --defbrpc_http_port_clustermgr 来更改该默认值。 正常情况下,只要工作机器上该默认端口没被占用并且被防火墙允许,一般不需要设置。否则需要设置该值。
- brpc_raft_port: 整数类型,指定集群管理器监听的 raft 端口,默认值为 58001,可以通过给 setup_cluster_manager.py 传递 --defbrpc_raft_port_clustermgr 来更改该默认值。 正常情况下,只要工作机器上该默认端口没被占用并且被防火墙允许,一般不需要设置。否则需要设置该值。
- prometheus_port_start: 整数类型,用于指定 cluster_mgr的prometheus 端口,默认为 59010, 可以通过 --defpromethes_port_start_clustermgr 来修改该默认值。
- prometheus_datadir: 字符串类型,指定用于存放prometheus数据的目录,不指定则使用默认的目录。注意,当该ip表示的机器已经在node_manager中设置过该属性时,这里则不需要设置。
- dc: 字符串类型,指明该工作机器所属dc,多DC模式时如果该ip在node_manager中没有相应条目,则这里该属性必须设置,普通模式时该值被忽略。
backup:对象类型,指定一些备份相关的信息,该属性正确设置后,Klustron集群的自动备份将能够工作, 当前支持 ssh 和 hdfs 两种备份方式:
hdfs: 对象类型,指定使用 hadoop file system 作为备份媒介的相关信息。
- ip: 字符串类型,用于指定 hdfs 服务器的所在地址
- port: 整数类型,用于指定 hdfs 服务器的连接端口,在前面 ip 指定地址的机器上,必须有 hdfs 的服务监听该端口。
- 当前暂时不支持 hdfs federation 的 hdfs 服务器地址形式。
ssh: 对象类型,用于指定使用 ssh/scp 进行复制备份的相关信息,主要属性有:
- ip: ssh 备份的目标机器 ip,字符串类型,必须项。
- port: 该目标机器上的 ssh server 监听端口,默认为 22.
- user: 连接该目标机器的用户名,要求所有存储节点所在工作机器的指定用户都具有使用该用户名免密 ssh 连接到目标机器的配置。
- targetDir: 目标机器上的备份文件夹,要求 user 对该目录具有读写的权限。如果该目录不存在,还要求 user 具有创建出该目录的权限。
xpanel: 对象类型,用于指定 xpanel 安装的信息,脚本将根据该设置,在指定的机器上启动 xpanel,以便用户能通过浏览器操作集群。当前具有以下属性:
- image: 镜像 url, 必须指定。可以是一个本地或者远程镜像url,一般使用远程镜像 url,建议设置为:
registry.cn-hangzhou.aliyuncs.com/kunlundb/kunlun-xpanel:VERSION, 脚本将自动将VERSION转化为--product_version 参数指定的版本号。也可以显式设置为当前 1.3.2 对应的远程镜像:registry.cn-hangzhou.aliyuncs.com/kunlundb/kunlun-xpanel:1.3.2。 - imageType: 镜像类型,当前支持 "url" 和 "file", 默认为 "url". 当类型为 "url" 时,镜像必须能被访问到。当类型为 "file" 时,脚本会从指定的文件(见后)中载入该镜像, 但需要用户提前下载好镜像文件到 clustermgr 目录中。
- imageFile: 指定镜像文件名,在 imageType 为 "file" 时起作用,默认为 "kunlun-xpanel-$VERSION.tar.gz", 其中 $VERSION 为 --product_version 参数指定的版本。 该文件使用 docker load 后,需要能产生 image 指定的镜像 url,Klustron 官方产生的镜像文件符合该需求。
- 根据安装模式的不同,剩余的属性略有不同:
- 在多DC模式时,剩余属性为nodes, 是一个对象数组,表示在多台机器上安装xpanel, 数组每个表示一个xpanel对象, 该对象具有的属性为:
- ip: 字符串类型,用于指定安装xpanel的机器的ip地址
- port: 指定 xpanel 在该机器上使用的端口号,整数类型,默认 18080。
- 在普通模式时,当前仅支持安装一个xpanel, 所以剩余属性为ip和port, 其属性值类型和意义与多DC模式下单个xpanel对象的相同。
- 在多DC模式时,剩余属性为nodes, 是一个对象数组,表示在多台机器上安装xpanel, 数组每个表示一个xpanel对象, 该对象具有的属性为:
- 普通模式时,最后的 XPanel 地址为
http://${xpanel.ip}:${xpanel.port}/KunlunXPanel。比如当 ip 为 192.168.0.110,port 为 18000 时,地址为http://192.168.0.110:18000/KunlunXPanel。 多DC模式时,由于可以安装多个XPanel, 所以可以有多个地址。
elasticsearch: 对象类型, 用于指定Elasticsearch/Kibana的安装信息。脚本将根据该信息,在指定的机器上启动Elasticsearch和Kibana(当前elasticsearch和kibana部署在同一台机器上),以便用户能够通过Kibana查看各类节点的日志信息。当前具有以下属性:
- ip: 字符串类型,指定ElasticSearch/Kibana所在机器的ip地址
- port: 整数类型,指定Elasticsearch的监听端口,默认9200
- kibana_port: 整数类型,指定Kibana的监听端口,默认5601
- 最后日志可以通过Kibana进行查看,地址为:
http://${elasticsearch.ip}:${elasticsearch.kibana_port}, 比如当ip为192.168.0.111,kibana_port使用默认值时,地址为http://192.168.0.111:5601
cdc: 对象类型, 用于指定cdc的安装信息,当前具有以下属性:
- nodes: 数组类型,指定cdc节点的详细配置,数组中每个元素表示一个cdc节点的配置。每个节点具有的属性有:
- ip: 字符串类型,必须项,指明安装所在机器,需要注意,machines中需有该ip的条目
- raft_port: 整数类型,设置该cdc进程braft协议监听的端口,当前默认为58004, 可以通过setup_cluster_manager.py的参数--defraft_port_cdc来修改默认值
- http_port: 整数类型,设置该cdc进程http协议监听的端口,当前默认为58005, 可以通过setup_cluster_manager.py的参数--defhttp_port_cdc来修改默认值
对一级属性以及后续的各级属性而言,只有在需要操作该属性表示的对象,或者需要该对象信息协助操作其他对象且该对象具有与默认不同的属性值时,才需要设置对应的对象。 否则不需要设置,脚本在运行时会使用默认值来创建必要的辅助对象来完成任务。例如:
- 集群管理系统的核心必须在首次安装动作中执行,所以 meta.nodes 和 cluster_manager.nodes 必须被正确设置。 对于后续的Klustron集群安装动作, 仅 meta.group_seeds 需要设置, cluster_mamanger 整个一级属性则不需要。 对于 meta.ha_mode 而言,仅首次安装需要设置。
7.4.2 在配置文件中,使用到了 Klustron-storage 对象,这里将做详细解释
Klustron-storage 对象表示一个使用
Klustron-storage-$VERSION.tgz软件包安装运行的实例,基于 MySQL-8.0.26 开发,该对象主要具有以下属性:is_primary: 布尔类型,表示在安装时,该 Klustron-storage 实例在存储集群中是否作为初始的主节点,默认值为 false,组中只能有一个主节点,当没有主节点时,第一个节点将成为主节点。
ip: 字符串类型,指定该 Klustron-storage 实例所在工作机器的地址
port: 整型,指定该 Klustron-storage 实例的对计算节点开放的监听端口,不填写则脚本自动在指定范围内选择一个
xport: 整形,指定该 Klustron-storage 实例用于 clone 的端口,仅在复制模式为 'mgr' 时,才需要设置,不填写则脚本自动在指定范围内选择一个
mgr_port: 整形,指定该 Klustron-storage 实例用于 XCom 通信的端口,仅在复制模式为 'mgr' 时,才需要设置, ,不填写则脚本自动在指定范围内选择一个
innodb_buffer_pool_size:字符串类型,指定该 Klustron-storage 实例的 Innodb buffer pool 大小, 对于元数据节点,该值默认 128MB,对于生产环境可能偏小,一般需要根据需要进行设置。 设置说明参见: Configuring InnoDB Buffer Pool Size
election_weight:整形,值在 1-100 之间,默认 50,用于 mgr 复制模式下的故障选主,一般可以不设置。仅在复制模式为 'mgr' 时才有作用,其他复制模式下,该设置被忽略。
7.5 多DC模式
从1.2.1开始,Klustron支持用多DC模式来安装集群,在多DC模式下,创建出来的集群可以具有双活部署模式和两地三中心模式的独有特征。关于多DC模式下的集群的详细特征,这里不展开介绍,请大家参考本站介绍这方面的文章。这里只介绍多DC模式如何配置和如何开启。
多DC版配置文件,与普通模式的配置文件,基本相同的同时,也具有一些区别。主要区别在如下:
- 多DC版的多了一个顶级成员"datacenters", 用于定义数据中心,具体见前面关于配置文件的详细说明。
- 多DC版中node_manager的每个成员,都要设置"dc"的属性,指明所属的数据中心。 注意node_manager会比cluster_manager先被处理,这与他们出现在配置文件中的顺序无关。
- 多DC版中的cluster_manager每个成员,支持一个可选的"dc"属性。当该成员对应ip已经在node_manager中设置过了dc属性,这里就不需要设置,否则,需要设置。如果同一个ip在node_manager和cluster_manager都设置dc属性,则两个属性值必须相同。
- 多DC版中允许安装多个xpanel, 所以xpanel具有一个nodes属性,是一个数组,数组中每个成员表示一个xpanel的安装实例
- 多DC版中,初始安装阶段,也就是安装meta nodes的阶段,需要每个dc具有至少两个meta nodes和至少两个clustermgr nodes.
一个多DC版配置文件的示例为(config_dcs1.json):
{
"machines":[
{
"ip":"192.168.0.110",
"basedir":"/home/kunlun/mdcbase",
"user":"kunlun"
},
{
"ip":"192.168.0.111",
"basedir":"/home/kunlun/mdcbase",
"user":"kunlun"
},
{
"ip":"192.168.0.100",
"basedir":"/home/kunlun/mdcbase",
"user":"kunlun"
},
{
"ip":"192.168.0.143",
"basedir":"/home/kunlun/mdcbase",
"user":"kunlun"
},
{
"ip":"192.168.0.151",
"basedir":"/home/kunlun/mdcbase",
"user":"kunlun"
},
{
"ip":"192.168.0.117",
"basedir":"/home/kunlun/mdcbase",
"user":"kunlun"
},
{
"ip":"192.168.0.141",
"basedir":"/home/kunlun/mdcbase",
"user":"kunlun"
},
{
"ip":"192.168.0.121",
"basedir":"/home/kunlun/mdcbase",
"user":"kunlun"
},
{
"ip":"192.168.0.137",
"basedir":"/home/kunlun/mdcbase",
"user":"kunlun"
}
],
"datacenters": [
{
"name": "sz-dc1",
"province": "guangdong",
"city": "shenzhen",
"is_primary": true
},
{
"name": "sz-dc2",
"province": "guangdong",
"city": "shenzhen"
},
{
"name": "gz-dc1",
"province": "guangdong",
"city": "guangzhou"
}
],
"meta":{
"ha_mode": "rbr",
"nodes":[
{
"ip":"192.168.0.110"
},
{
"ip":"192.168.0.111"
},
{
"ip":"192.168.0.143"
},
{
"ip":"192.168.0.151"
},
{
"ip":"192.168.0.141"
},
{
"ip":"192.168.0.121"
}
]
},
"cluster_manager": {
"nodes": [
{
"ip": "192.168.0.110"
},
{
"ip": "192.168.0.111"
},
{
"ip": "192.168.0.143"
},
{
"ip": "192.168.0.151"
},
{
"ip": "192.168.0.141"
},
{
"ip": "192.168.0.121"
}
]
},
"node_manager": {
"nodes": [
{
"ip": "192.168.0.110",
"dc": "sz-dc1"
},
{
"ip": "192.168.0.111",
"dc": "sz-dc1"
},
{
"ip": "192.168.0.100",
"dc": "sz-dc1"
},
{
"ip": "192.168.0.143",
"dc": "sz-dc2"
},
{
"ip": "192.168.0.151",
"dc": "sz-dc2"
},
{
"ip": "192.168.0.117",
"dc": "sz-dc2"
},
{
"ip": "192.168.0.141",
"dc": "gz-dc1"
},
{
"ip": "192.168.0.121",
"dc": "gz-dc1"
},
{
"ip": "192.168.0.137",
"dc": "gz-dc1"
}
]
},
"xpanel": {
"image": "registry.cn-hangzhou.aliyuncs.com/kunlundb/kunlun-xpanel:VERSION",
"nodes": [
{
"ip": "192.168.0.110"
},
{
"ip": "192.168.0.143"
},
{
"ip": "192.168.0.141"
}
]
}
}
多DC模式主要通过给setup_cluster_manager.py传递--multipledc选项来开启,一些操作例子为:
- 安装
cd cloudnative/cluster
python setup_cluster_manager.py --config=config_dcs1.json --multipledc --action=install
bash -e clustermgr/install.sh
- 停止
cd cloudnative/cluster
python setup_cluster_manager.py --config=config_dcs1.json --multipledc --action=stop
bash clustermgr/stop.sh
- 断电后或者停止后重新启动整个系统
cd cloudnative/cluster
python setup_cluster_manager.py --config=config_dcs1.json --multipledc --action=start
bash clustermgr/start.sh
- 出错后或者正常清理
cd cloudnative/cluster
python setup_cluster_manager.py --config=config_dcs1.json --multipledc --action=clean
bash clustermgr/clean.sh
7.6 一个分步骤安装集群管理系统的例子
集群管理系统的工作机器并不需要在一开始就全部确定,可以先安装系统的一部分(包含核心),而后逐步向系统中加入新的工作机器。所以这里给出一个分步骤安装集群管理系统的例子。
这里需要注意的是,这里给 setup_cluster_manager.py 传递了 --autostart 选项,使得所有相关进程具有重启后被自动拉起的功能。
本例主要包含以下步骤:
安装管理系统核心部分和设置若干初始工作机器
向管理系统中增加若干台机器,扩大资源池
继续向管理系统中增加若干台机器,扩大资源池
某些机器另作他用,从资源池中删除
删除整个系统。
7.6.1 安装管理系统核心部分和设置若干初始工作机器
第一步,安装集群管理系统的核心部分, 部署在三台机器上 192.168.0.2/3/4 上, 包含三个元数据节点和三个集群管理器节点。另外再设置上三台机器(192.168.0.5/6/7),作为集群管理器部署存储节点和计算节点的备选机器。假设每台机器都是默认的 8 核,16G 内存。
前三台机器每台机器上都有一个元数据节点,每个元数据节点都使用 6001 作为监听端口, 其余端口由脚本自己选择,元数据集群使用rbr(即FullSync) 作为复制模式。 其余都用默认值。
由于前三台每台机器上都有元数据节点, 所以每台机器还需要一个节点管理器,对应的节点管理器使用默认的5800X端口。所有目录全部使用默认。
前三台机器每台机器上都有一个集群管理器节点。 使用默认的 5800X 系列端口
后三台机器要设置,所以也需要各安装一个节点管理器。 这里假设目录和端口设置都使用默认。
备份信息不设置,这一步也不安装任何Klustron集群。
XPanel 安装在第一台机器上,使用远程镜像:
registry.cn-hangzhou.aliyuncs.com/kunlundb/kunlun-xpanel:VERSION,假设 xpanel 不使用的 18080 端口,因为已经被占用了,而使用 18000 作为端口。ElasticSearch/Kibana安装在第二台机器上,ElasticSearch使用默认的监听端口9200, Kibana使用默认的监听端口5601。
每台机器上都安装好了必要的软件,建立了 kunlun 这个用户名,并且使用默认的 /kunlun 作为工作目录,所以 machines 中此处就不需要任何条目。但对 /kunlun, 有两种情况:
- a. /kunlun 由用户手动创建好,并且给 kunlun 用户足够权限来操作这个目录,此时不需要给 setup_cluster_manager.py 传递带特殊权限的选项
- b. /kunlun 用户没有创建好,则脚本会尝试创建,此时需要给 setup_cluster_manager.py 传递 --sudo 选项,并且这些工作机器上的kunlun 具有免密执行 sudo 的权限。
根据上述说明,最后形成的配置文件(假设名为 system.json )为:
{
"meta":{
"ha_mode": "rbr",
"nodes":[
{
"ip":"192.168.0.2",
"port":6001
},
{
"ip":"192.168.0.3",
"port":6001
},
{
"ip":"192.168.0.4",
"port":6001
}
]
},
"cluster_manager": {
"nodes": [
{
"ip": "192.168.0.2"
},
{
"ip": "192.168.0.3"
},
{
"ip": "192.168.0.4"
}
]
},
"xpanel": {
"ip": "192.168.0.2",
"port": 18000,
"image": "registry.cn-hangzhou.aliyuncs.com/kunlundb/kunlun-xpanel:VERSION"
},
"elasticsearch": {
"ip": "192.168.0.3"
},
"node_manager": {
"nodes": [
{
"ip": "192.168.0.2"
},
{
"ip": "192.168.0.3"
},
{
"ip": "192.168.0.4"
},
{
"ip": "192.168.0.5"
},
{
"ip": "192.168.0.6"
},
{
"ip": "192.168.0.7"
}
]
}
}
- 如果 /kunlun 目录在三台工作机器上都已经创建好,并且对 kunlun 用户给与了足够权限则安装命令为:
cd cloudnative/cluster
python setup_cluster_manager.py --autostart --config=core.json --action=install
bash -e clustermgr/install.sh
- 否则,可以让脚本来创建该目录,但需要传递 --sudo, 并且保证这些机器上的 kunlun 具有免密 sudo 的权限,命令为:
cd cloudnative/cluster
python setup_cluster_manager.py --autostart --config=core.json --action=install --sudo
bash -e clustermgr/install.sh
- setup_cluster_manager.py 在安装核心时会打印出 metaseeds, 需要记录下来,以便后续安装节点管理器使用,这里打印的内容是:
metaseeds:192.168.0.2:6001,192.168.0.3:6001,192.168.0.4:6001
- 安装完毕后,就可以使用XPanel通过集群管理器发送命令来操作Klustron集群了,包括但不限于创建,删除,修改,备份,恢复等。其中 XPanel 的地址为: http://192.168.0.102:18000/KunlunXPanel
7.6.2 向管理系统中增加若干台机器以扩大资源池
接下来假设要上一个大业务,而为了应对该大业务的数据存储和数据处理的需求,新增加了 6 台(192.168.0.108-113)机器。 于是就需要对这六台机器进行设置,以便集群管理器能够在这些机器上部署Klustron集群的存储节点和计算节点。假设这些机器每台都是 16 核,64G 内存。
这六台机器是新机器,于是要加入资源池,每台机器上都需要部署一个节点管理器。假设其中每台机器为了提高 I/O 效率,所以数据放在单独的磁盘上(假设 mount 路径都是 /data1),于是设置 storage_datadir 为 /data1/datadir, 错误日志,重做日志和计算节点日志由于量不大,就放默认路径上。
假设这些机器用户自己创建好 /kunlun 目录作为工作目录,并且建立好 kunlun 账号。由于和默认值相同,所以 machines 中不需要单独的条目。
元数据节点已经安装过了, 这里只需要其地址信息,就是前面显示的 metaseeds. 集群管理器在第一步时已经装过,所以 cluster_manager 就不需要了。
于是最后形成的配置文件(add1.json)为:
{
"meta":{
"ha_mode": "rbr",
"group_seeds": "192.168.0.2:6001,192.168.0.3:6001,192.168.0.4:6001"
},
"node_manager": {
"nodes": [
{
"ip": "192.168.0.8",
"total_cpu_cores": 16,
"total_mem": 65536,
"storage_datadirs": "/data1/datadir"
},
{
"ip": "192.168.0.9",
"total_cpu_cores": 16,
"total_mem": 65536,
"storage_datadirs": "/data1/datadir"
},
{
"ip": "192.168.0.10",
"total_cpu_cores": 16,
"total_mem": 65536,
"storage_datadirs": "/data1/datadir"
},
{
"ip": "192.168.0.11",
"total_cpu_cores": 16,
"total_mem": 65536,
"storage_datadirs": "/data1/datadir"
},
{
"ip": "192.168.0.12",
"total_cpu_cores": 16,
"total_mem": 65536,
"storage_datadirs": "/data1/datadir"
},
{
"ip": "192.168.0.13",
"total_cpu_cores": 16,
"total_mem": 65536,
"storage_datadirs": "/data1/datadir"
}
]
}
}
- 安装命令
cd cloudnative/cluster
python setup_cluster_manager.py --autostart --config=add1.json --action=install
bash -e clustermgr/install.sh
- 安装成功后,这 6 台机器就已经设置好了,就可以使用 XPanel 通过集群管理器发送命令来操作Klustron集群了。
7.6.3 继续向管理系统中增加若干台机器以扩大资源池
**假设接下来要上一个小业务,并且用三台(192.168.0.14/15/16)已经在跑其他业务(不属于本系统)的机器来部署这个小业务的Klustron集群。本脚本将这些机器加入集群管理系统,而Klustron集群的创建则交由集群管理器。 **
由于这三台机器原来不属于管理系统,所以需要给每台机器安装一个节点管理器。假设这些机器是默认的 8 核,16G 内存的配置。
元数据集群和集群管理器的配置,和前面一样。
由于这三台机器本来在跑业务,假设某些业务用的就是 kunlun 账户,而且目录 /kunlun 上有其他业务的代码包和数据。 为了保证数据库稳定运行不受影响,一般建议使用独立的账号和独立的目录, 所以默认的用户和工作目录就不起作用,假设将默认用户改为 dbuser (已创建), 而默认工作目录改为 /Klustron (已创建)。此时有两种做法:
- 为每台机器在 machines 中创建条目,条目中指定用户名和工作目录
- 不为每台机器创建条目,但是给 setup_cluster_manager.py 传递 --defuser=dbuser 和 --defbase=/Klustron 选项。
同样,假设这三台机器上, 58000-58010 这个范围的端口被占用了,于是节点管理两个默认的端口就不能用了。所以 brpc_http_port改为 35000, 而 tcp_port 改为 35001, 此时有两种做法:
- 给每个节点管理器设置 brpc_http_port 和 tcp_port 属性。
- 不设置这两个属性,但是给 setup_cluster_manager.py 传递 --defbrpc_http_port_nodemgr=35000 和 --deftcp_port_nodemgr=35001 选项。
从表面上看,传递选项的方式更简单。但是对于涉及多台机器,这些机器有自己定制属性的情况,精确设置条目会更合适。本例选择精确设置条目。于是最后的配置文件(add2.json)为:
{
"machines":[
{
"ip":"192.168.0.14",
"basedir":"/Klustron",
"user":"dbuser"
},
{
"ip":"192.168.0.15",
"basedir":"/Klustron",
"user":"dbuser"
},
{
"ip":"192.168.0.16",
"basedir":"/Klustron",
"user":"dbuser"
}
],
"meta":{
"ha_mode": "rbr",
"group_seeds": "192.168.0.2:6001,192.168.0.3:6001,192.168.0.4:6001"
},
"node_manager": {
"nodes": [
{
"ip": "192.168.0.14",
"brpc_http_port": 35000,
"tcp_port": 35001
},
{
"ip": "192.168.0.15",
"brpc_http_port": 35000,
"tcp_port": 35001
},
{
"ip": "192.168.0.16",
"brpc_http_port": 35000,
"tcp_port": 35001
}
]
}
}
- 安装命令
cd cloudnative/cluster
python setup_cluster_manager.py --autostart --config=add2.json --action=install
bash -e clustermgr/install.sh
- 安装成功后,这 3 台机器就已经设置好了, 可以向集群管理器发送请求来在这 3 台工作机器上安装Klustron集群了。
7.6.4 某些机器另作他用,从资源池中删除
假设后面小业务停止运行,后面新增的三台机器将另作他用,在将必要数据备份后,需要将这三台从管理系统中去除,于是需要运行清理动作,来清理必要的数据和程序/进程。
配置文件依然使用(add2.json)
清理命令
cd cloudnative/cluster
python setup_cluster_manager.py --autostart --config=add2.json --action=clean
bash clustermgr/clean.sh
7.6.5 清理整个系统
假设该集群管理系统中所有的Klustron集群都完成使命,需要删除整个系统。
需要整合所有配置文件,形成一个新的配置文件, 配置文件包含所有的元数据节点,集群管理器和节点管理器, 需要注意的是,第二次新增的三台机器,在上一步已经删除,所以这里不需要额外动作。
最后形成的配置文件(clean.json)为:
{
"meta":{
"ha_mode": "rbr",
"nodes":[
{
"ip":"192.168.0.2",
"port":6001
},
{
"ip":"192.168.0.3",
"port":6001
},
{
"ip":"192.168.0.4",
"port":6001
}
]
},
"cluster_manager": {
"nodes": [
{
"ip": "192.168.0.2"
},
{
"ip": "192.168.0.3"
},
{
"ip": "192.168.0.4"
}
]
},
"xpanel": {
"ip": "192.168.0.2",
"port": 18000,
"image": "registry.cn-hangzhou.aliyuncs.com/kunlundb/kunlun-xpanel:VERSION"
},
"elasticsearch": {
"ip": "192.168.0.3"
},
"node_manager": {
"nodes": [
{
"ip": "192.168.0.2"
},
{
"ip": "192.168.0.3"
},
{
"ip": "192.168.0.4"
},
{
"ip": "192.168.0.5"
},
{
"ip": "192.168.0.6"
},
{
"ip": "192.168.0.7"
},
{
"ip": "192.168.0.8",
"storage_datadirs": "/data1/datadir"
},
{
"ip": "192.168.0.9",
"storage_datadirs": "/data1/datadir"
},
{
"ip": "192.168.0.10",
"storage_datadirs": "/data1/datadir"
},
{
"ip": "192.168.0.11",
"storage_datadirs": "/data1/datadir"
},
{
"ip": "192.168.0.12",
"storage_datadirs": "/data1/datadir"
},
{
"ip": "192.168.0.13",
"storage_datadirs": "/data1/datadir"
}
]
}
}
- 清理命令
cd cloudnative/cluster
python setup_cluster_manager.py --autostart --config=clean.json --action=clean
bash clustermgr/clean.sh