
Klustron集群两地三中心跨城(IDC)高可用
Klustron集群两地三中心跨城(IDC)高可用
注意:
如无特别说明,文中的版本号可以使用任何已发布版本的版本号代替。所有已发布版本详见:Release_notes。
概述
一个Klustron集群按照多机房模式部署到同城多个机房之后,Klustron多机房高可用能力可以确保一个机房整体故障的情况下,Klustron集群主节点自动切换到另一个机房,并且确保Klustron集群自动从故障中恢复运行,数据不丢失损坏,RPO=0, RTO<30秒。
01 需求背景
Klustron的fullsync 强同步复制技术和fullsync HA 高可用技术,确保kunlun-storage 节点组成的存储集群(storage shard) 的主节点发生故障时,Klustron 可以自动及时发现故障并自动选举出新的主节点持续对外提供数据读写服务,并且不丢失、损坏用户数据。对于大多数应用场景所需的高可靠性要求以及能够提供的资源条件,这样的可靠性级别已经足够了。
然而面对在金融级高可靠性的极致要求,这仍然是不够的,因为如果一个数据中心(IDC)整体失效(比如断电,地震,火灾,水灾等)的情况下,如果一个Klustron 集群所有节点部署在这样一个IDC机房,它们就会同时消失,那么用户数据仍然会丢失,数据库服务也仍然会停止。
为了达到IDC 级别的高可用,Klustron 团队开发了数据中心 (IDC) 级高可用技术。Klustron从 1.2 版本开始,支持数据中心(IDC)高可用功能。
02 功能概览
Klustron IDC 容灾技术可以做到如果主城的主IDC故障,则Klustron 会自动发现此故障并把每个Klustron 的storage shard的主节点自动切换到主城的(某个)备IDC 中该shard的候选主节点,这个操作简称为把这个备IDC升级为主IDC;如果主城所有IDC 全部整体故障,则用户DBA 可以收到告警并且能够手动操作Klustron XPanel GUI或者调用Klustron cluster_mgr API 来切换每个shard的主节点 到该shard在备城的备IDC的候选主节点(此种情况下可能需要少量人工介入的操作),也就是把备城IDC升级为主IDC。
这两种操作本质上都是把一个Klustron集群的所有storage shard以及元数据集群的主节点都整体切换为另一个数据中心(IDC)中该shard的候选主节点。
03 两地三中心架构
_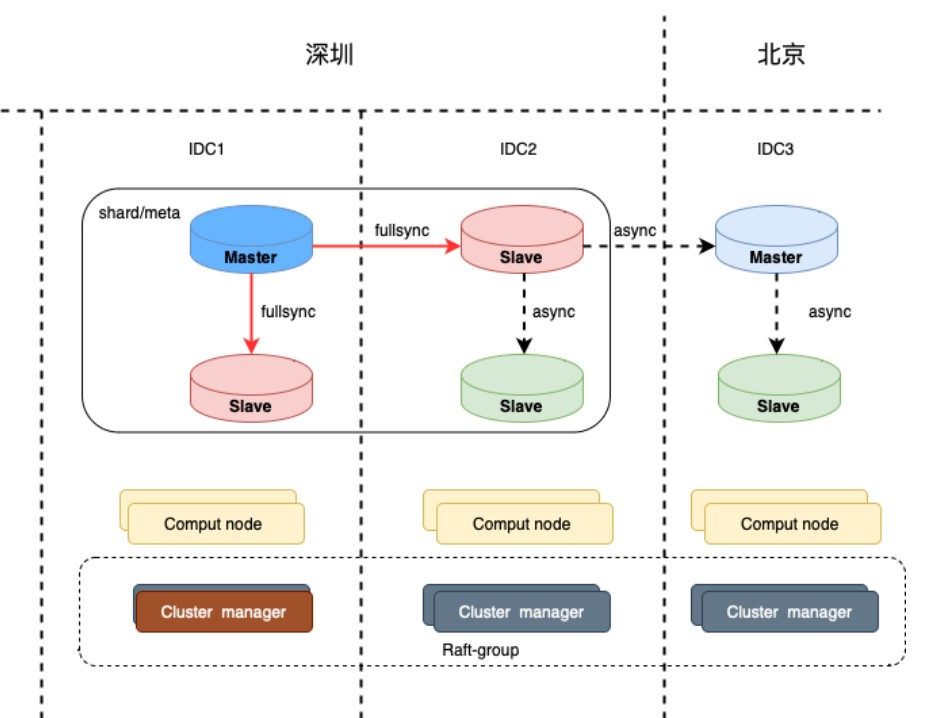
两地三中心是指通过同城两个数据中心(IDC),备城一个数据中心部署实现服务的跨地域 IDC级 高可用容灾。一个 Klustron 集群的每一个 shard 的拓扑如上图所示。用户可以根据需要在每一个 IDC 部署任意数量的计算节点(Klustron-server) 和clusterManager节点。所有计算节点都持续从元数据集群同步用户的元数据更新。两地三中心架构实现了同城任意一个 IDC 灾难高可用自动恢复以及主城灾难下,备城IDC的手动恢复,Klustron 提供工具辅助用户切换。
更多信息详见:https://doc.klustron.com/zh/Klustron_idc_high_availability_architecture.html
04 配置数据中心( IDC )管理
在能访问192.168.56.112的机器上打开浏览器,输入地址:http://192.168.56.112:18080/KunlunXPanel/#/login?redirect=%2Fdashboard
登录后首页显示如下:
_
接下来在数据中心(IDC)管理中添加IDC。
4.1 点击“数据中心(IDC)管理”、“数据中心列表”,数据中心列表界面点击“新增”按钮。
_
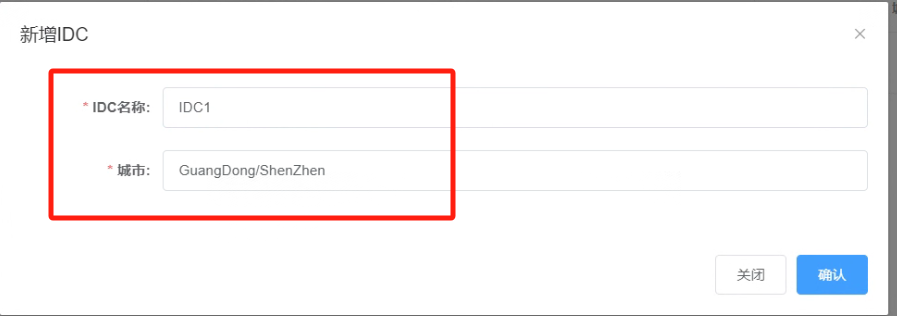
4.2 新增IDC,指定IDC名称“IDC1”,城市“GuangDong/ShenZhen”,然后点击“确认”
_
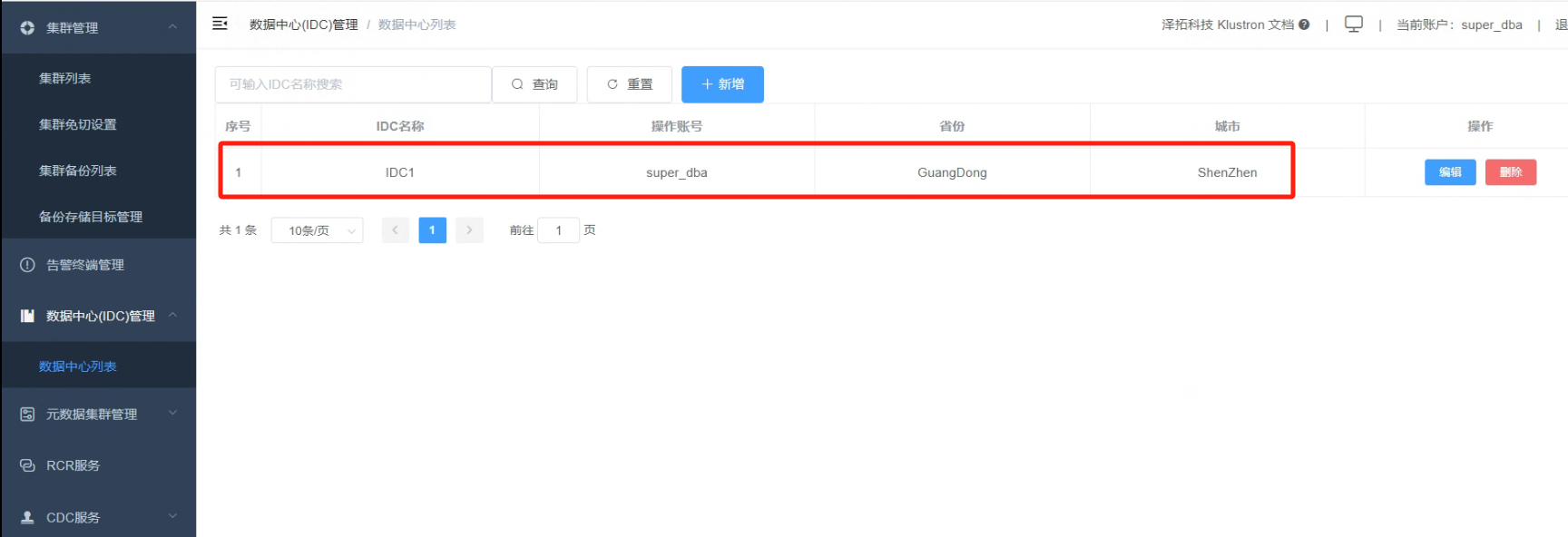
4.3 新增好数据中心“IDC1”
_
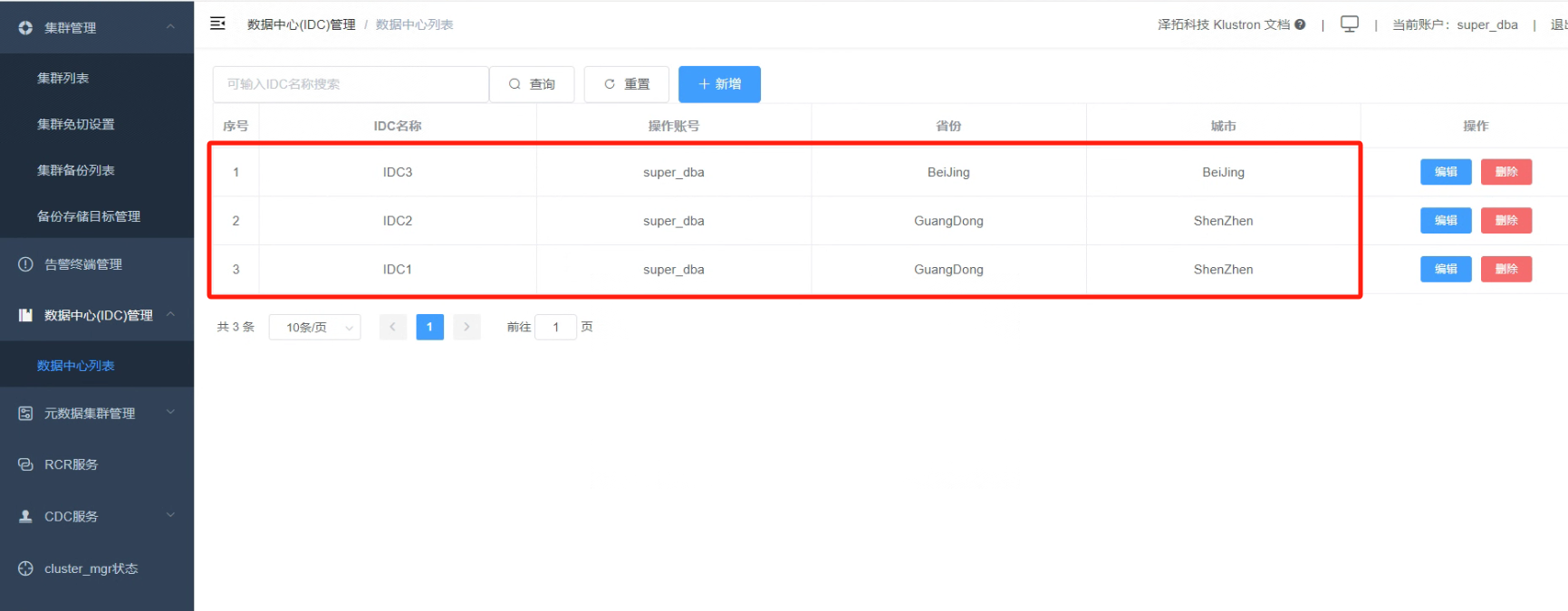
4.4 重复4.1和4.2步骤,新增数据中心“IDC2”和数据中心“IDC3”;新增好后,查看IDC数据中心配置情况
_
接下来在计算机管理中心绑定IDC。
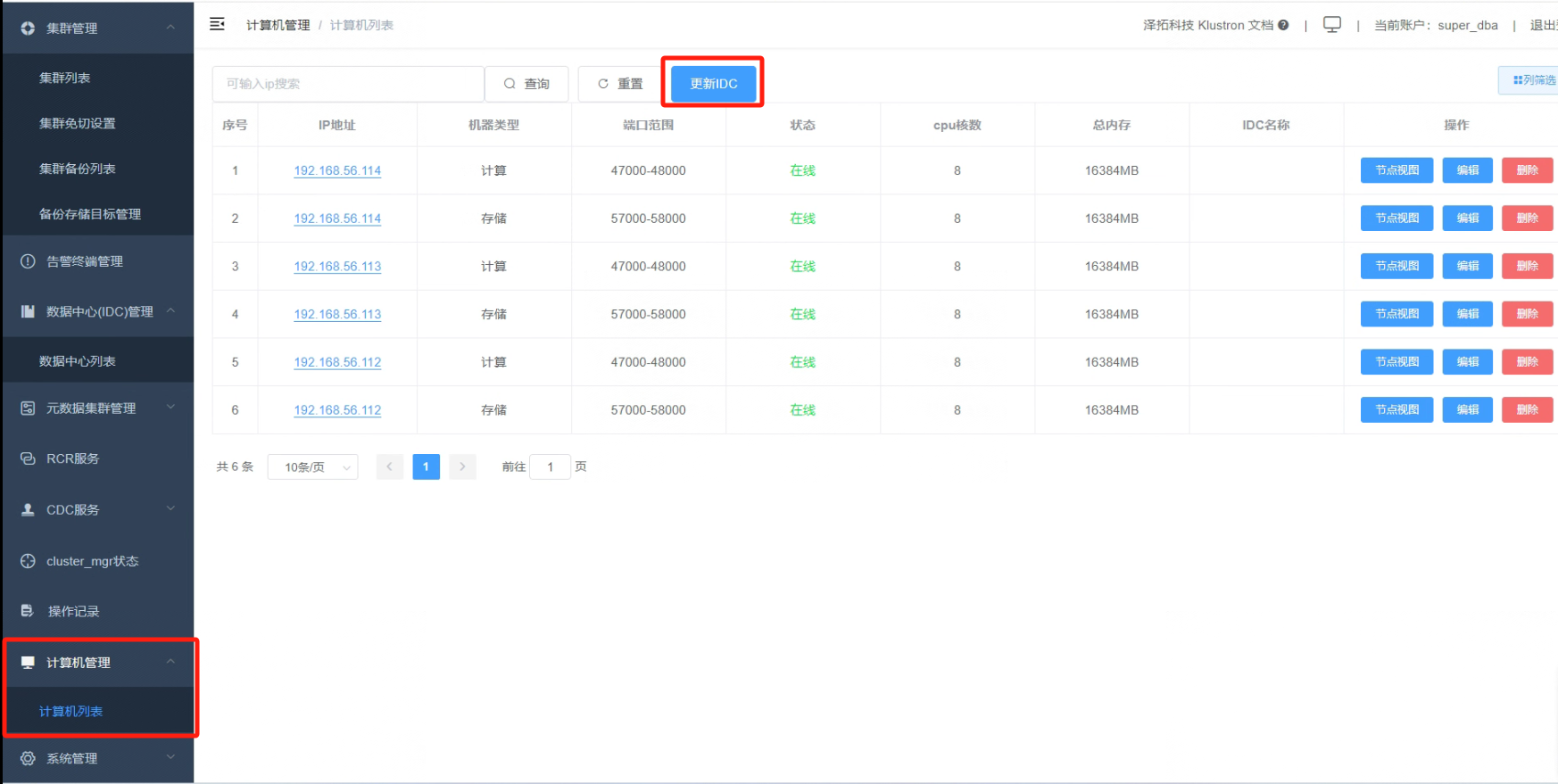
4.5 点击“计算机管理”,“计算机列表”,计算机列表界面点击“更新IDC”按钮。
_
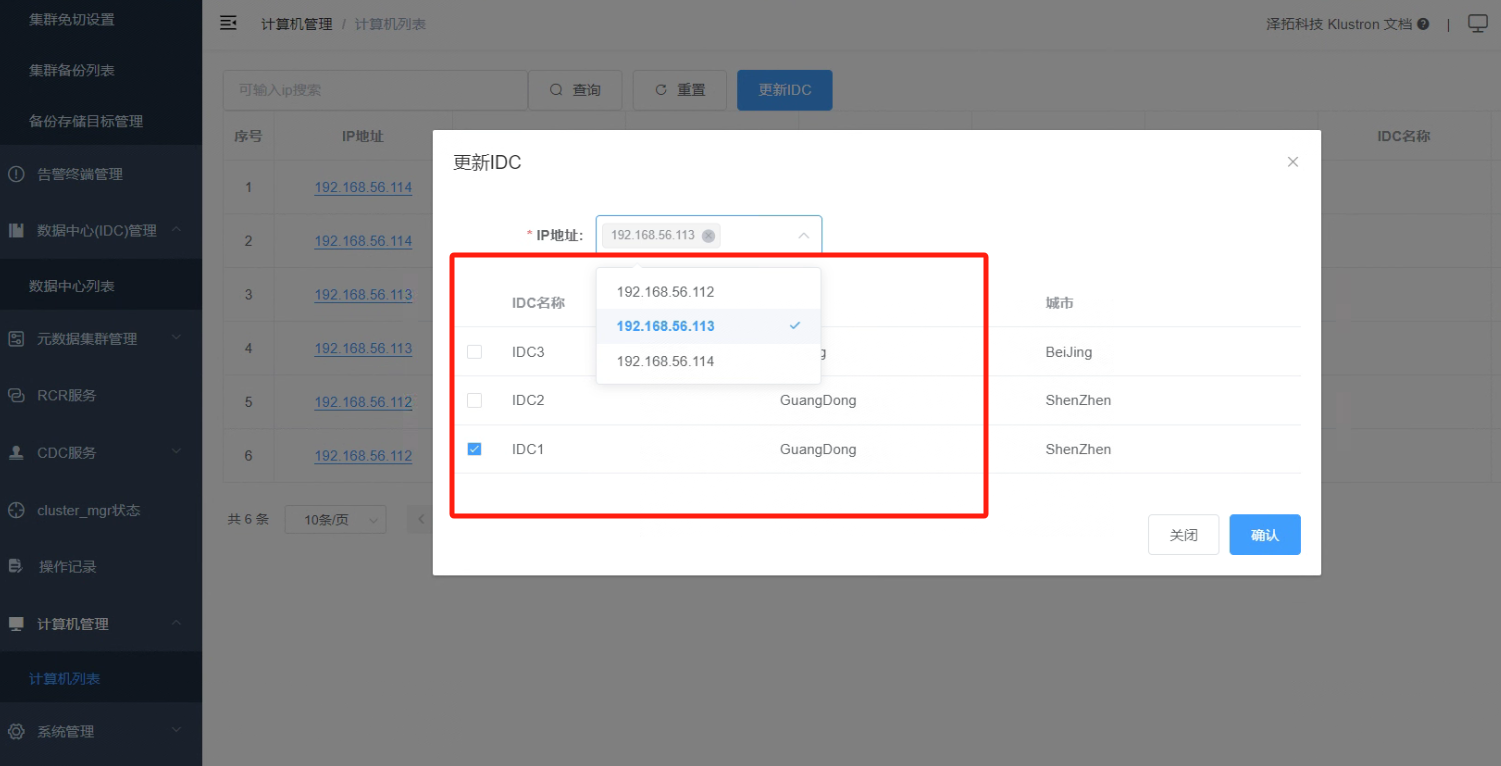
4.6 选择相应的计算机资源绑定到IDC1数据中心。
_
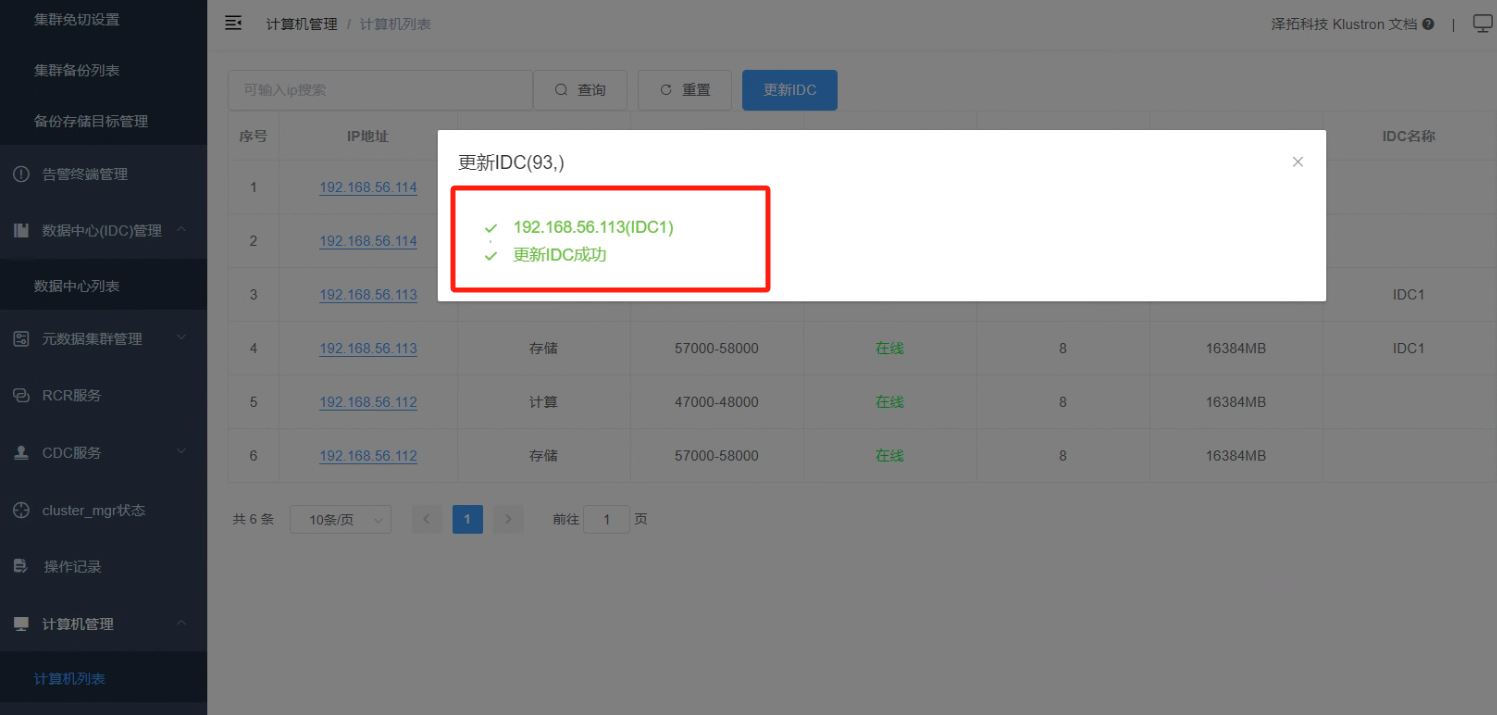
4.7 点击“确认”,查看创建集群任务的完成情况。
_
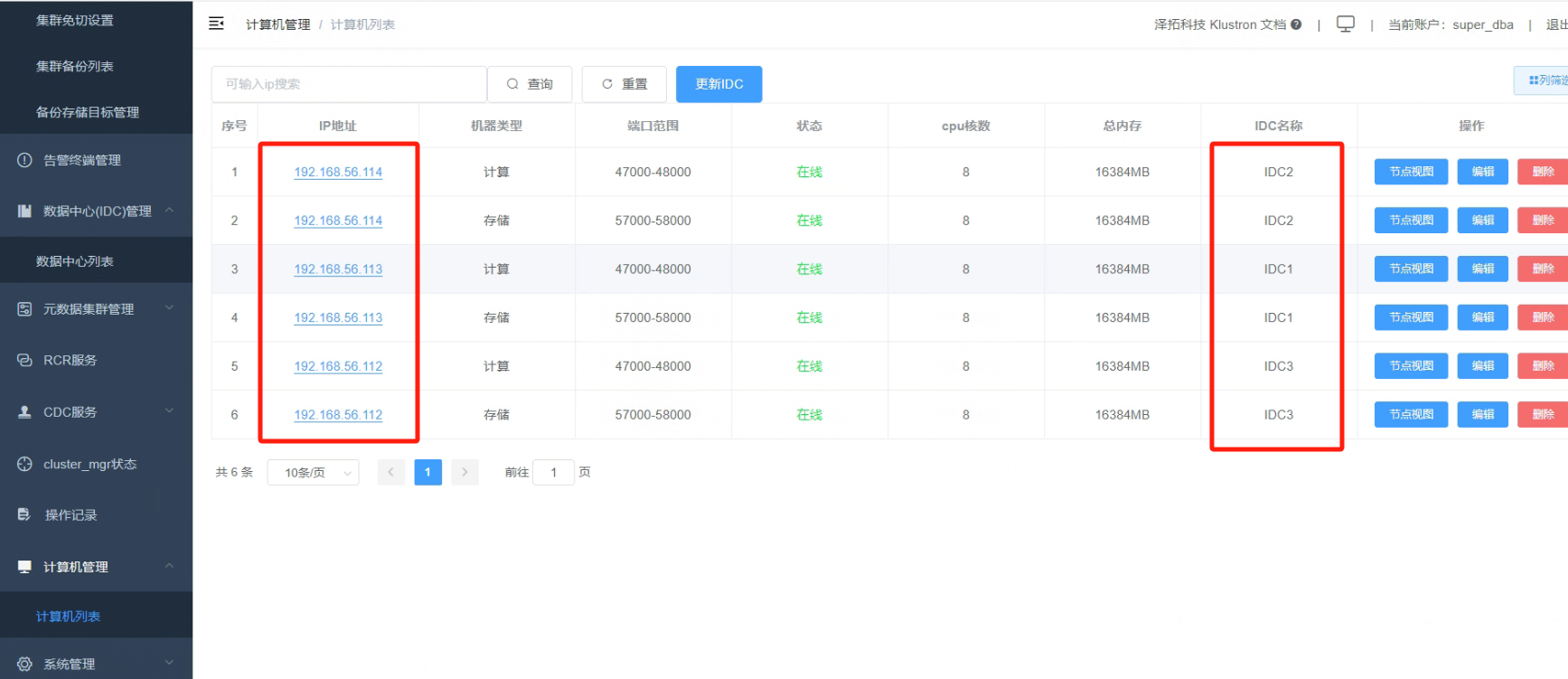
4.8 使用同样的方法绑定计算机资源到数据中心IDC2和数据中心IDC3,绑定IDC好后,查看IDC绑定情况
_
05 创建跨城 IDC HA 集群
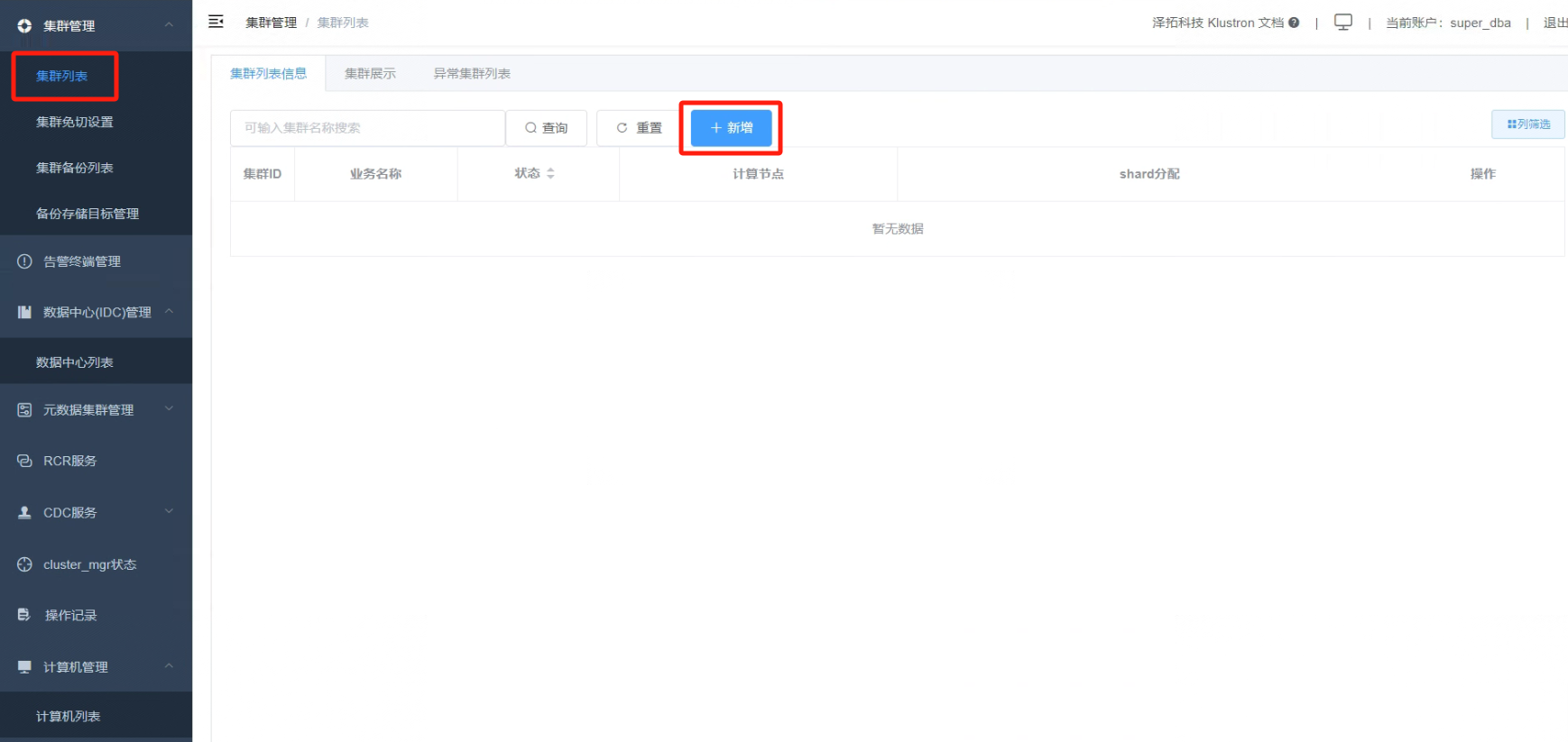
5.1 点击“集群管理”、“集群列表”,集群列表界面点击“新增”按钮
_
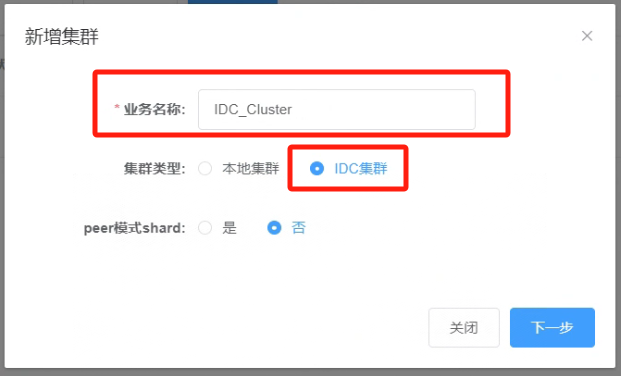
5.2 新增集群,指定业务名称“IDC_Cluster”,集群类型选择“IDC集群”
_
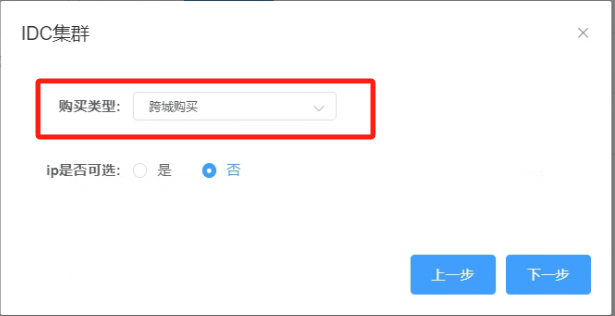
5.3 在IDC集群的购买类型选择“跨城购买”
_
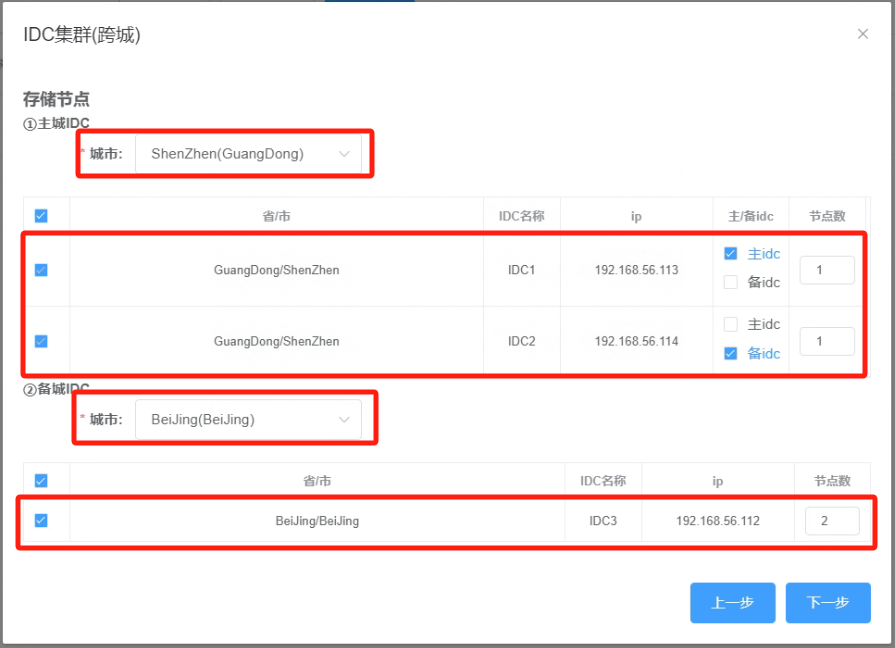
5.4 在IDC集群(跨城)的主城IDC城市选择IDC所在城市“ShenZhen”,并选择主IDC1和备IDC2,在备城IDC城市选择IDC3所在城市“BeiJing”
_
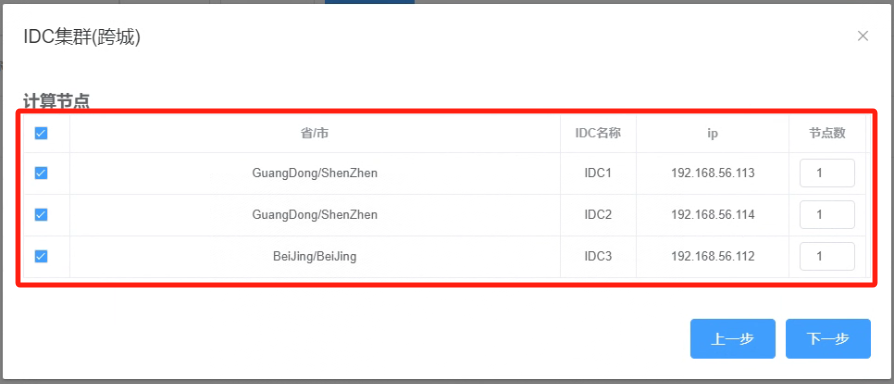
5.5 选择IDC集群(跨城)的计算节点
_
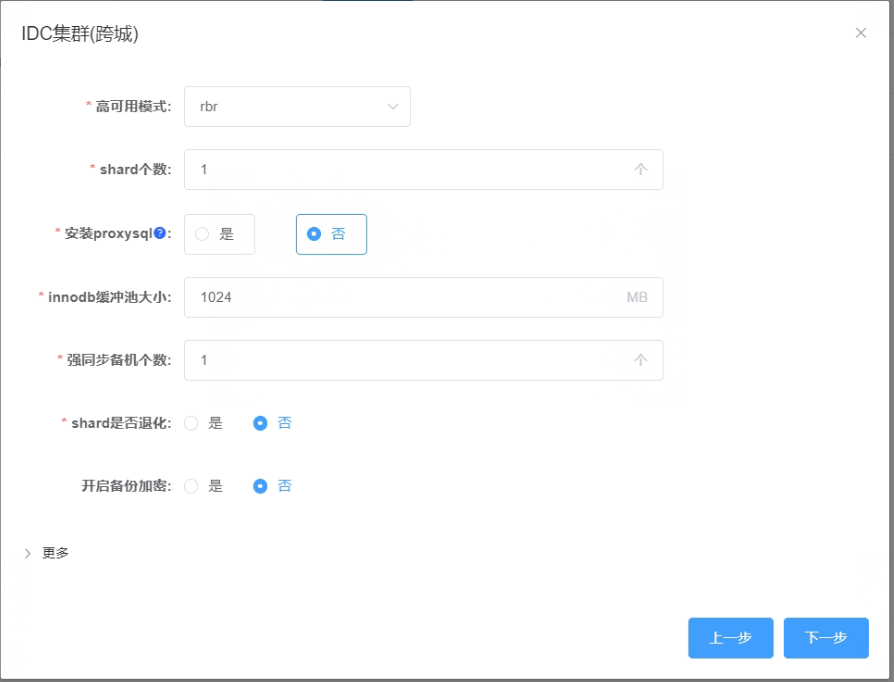
5.6 新建集群配置信息,这里使用默认值
_
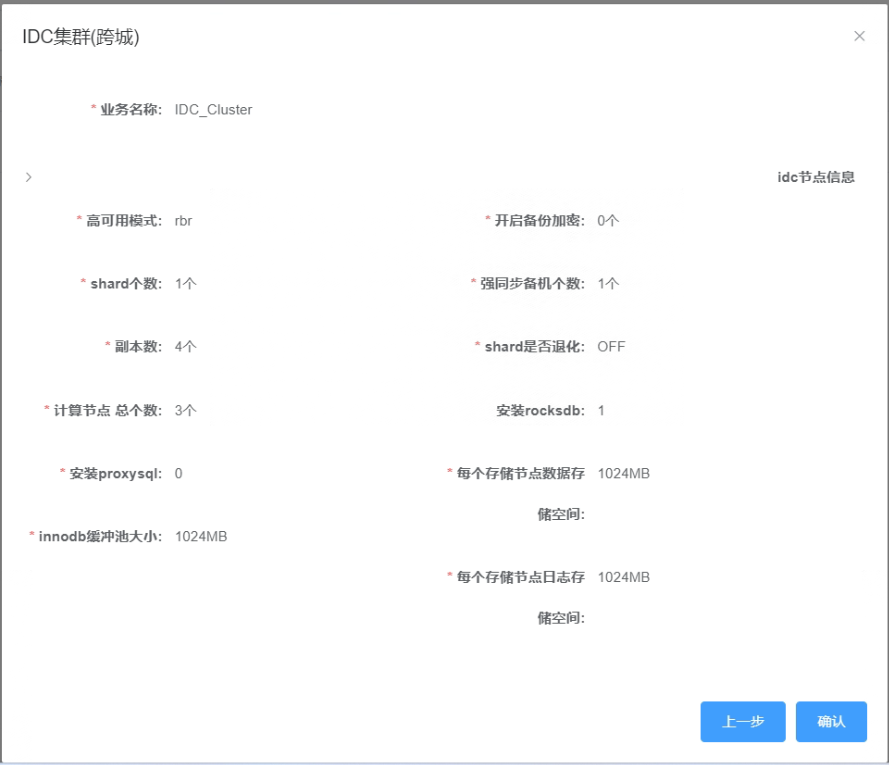
5.7 新建集群概览信息
_
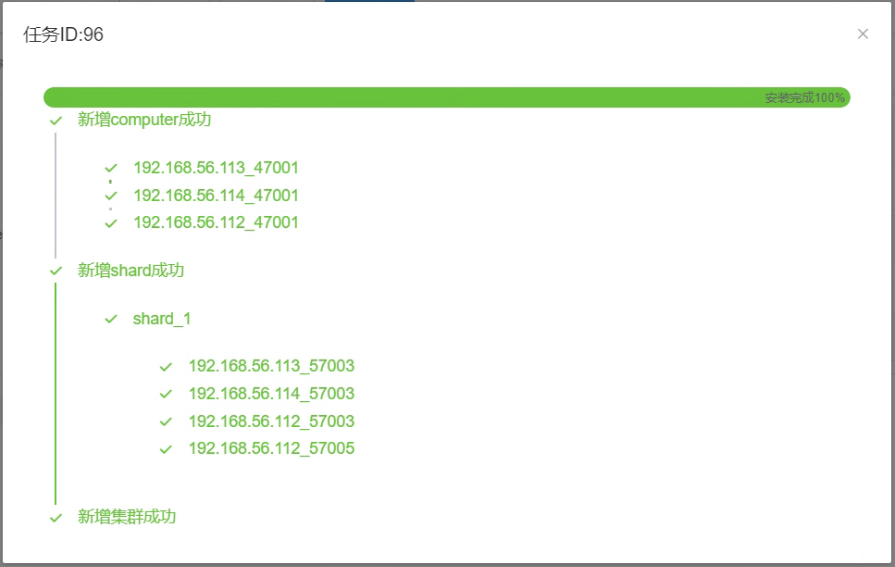
5.8 点击“确认”,查看创建集群任务的完成情况。
_
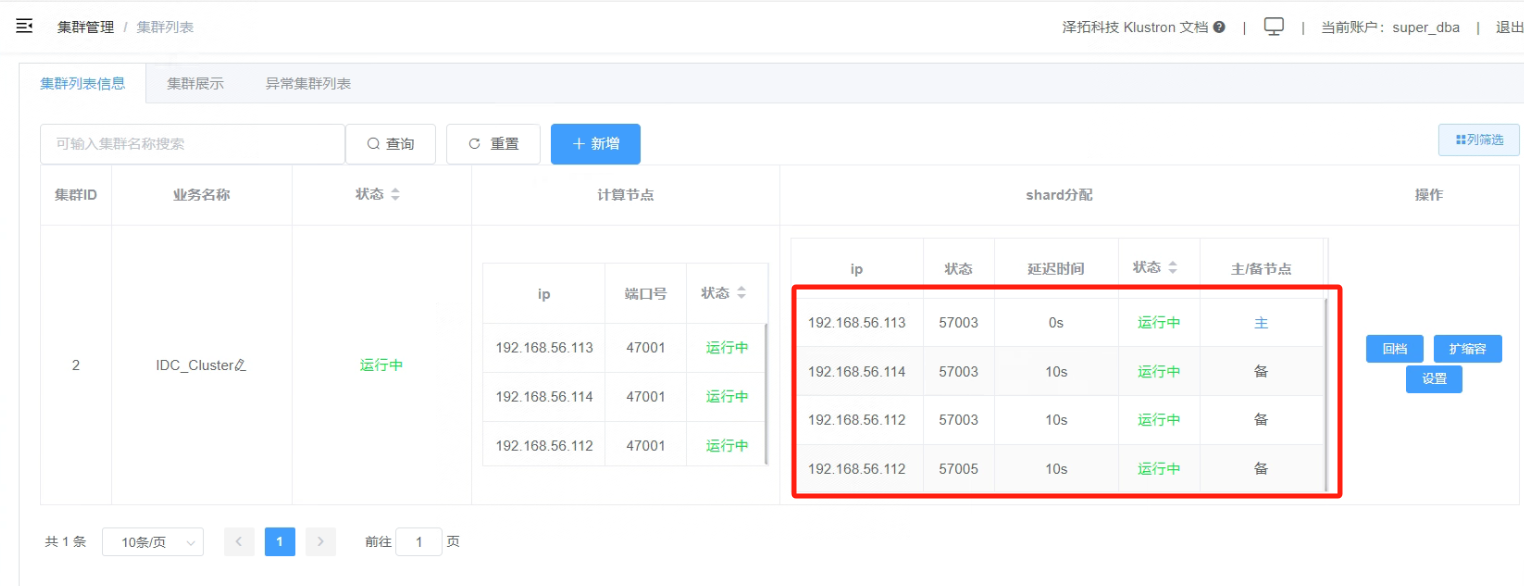
5.9创建配置跨城IDC集群好后,查看IDC集群“IDC_Cluster”的运行状态如下
_
06 跨城 IDC HA 集群同城主备 IDC 切换测试
6.1 准备试验数据,在数据库中创建测试表,并插入测试数据。
[kunlun@kunlun1 ~]$ psql -h 192.168.56.112 -p 47001 -U abc postgres
postgres=# create table prod_part (id int primary key, name char(8)) partition by hash(id);
postgres=# create table prod_part_p1 partition of prod_part for values with (modulus 6, remainder 0);
postgres=# create table prod_part_p2 partition of prod_part for values with (modulus 6, remainder 1);
postgres=# create table prod_part_p3 partition of prod_part for values with (modulus 6, remainder 2);
postgres=# create table prod_part_p4 partition of prod_part for values with (modulus 6, remainder 3);
postgres=# create table prod_part_p5 partition of prod_part for values with (modulus 6, remainder 4);
postgres=# create table prod_part_p6 partition of prod_part for values with (modulus 6, remainder 5);
postgres=# insert into prod_part select i,'text'||i from generate_series(1,300) i;
postgres=# analyze prod_part;
_
6.2准备一个python脚本pyprod.py,在IDC HA集群的主备做切换的同时对数据库持续操作,pyprod.py脚本内容如下:
import psycopg2.extras
from psycopg2 import DatabaseError
import time
import datetime
conn = psycopg2.connect(database='postgres',user='abc',
password='abc',host='192.168.56.112',port='47001')
select_sql = ''' select * from prod_part where id=%s; '''
i = 1
try:
while (i <= 1000) :
cursor = conn.cursor(cursor_factory=psycopg2.extras.RealDictCursor)
cursor.execute(select_sql,[i])
res = cursor.fetchall()
print(dict(res[0]))
current_datetime = datetime.datetime.now()
print("当前日期和时间:", current_datetime)
if (i == 1000) :
i = 1
else :
i = i+1
cursor.close()
conn.commit()
time.sleep(1)
except (Exception, DatabaseError) as e:
print(e)
input('Press any key and Enter to continue ~!')
conn = psycopg2.connect(database='postgres', user='abc',
password='abc', host='192.168.56.112', port='47001')
select_sql = ''' select * from prod_part where id=%s; '''
while (i <= 1000):
cursor = conn.cursor(cursor_factory=psycopg2.extras.RealDictCursor)
cursor.execute(select_sql, [i])
res = cursor.fetchall()
print(dict(res[0]))
current_datetime = datetime.datetime.now()
print("当前日期和时间:", current_datetime)
if (i == 1000):
i = 1
else:
i = i + 1
cursor.close()
conn.commit()
time.sleep(1)
finally:
conn.close()
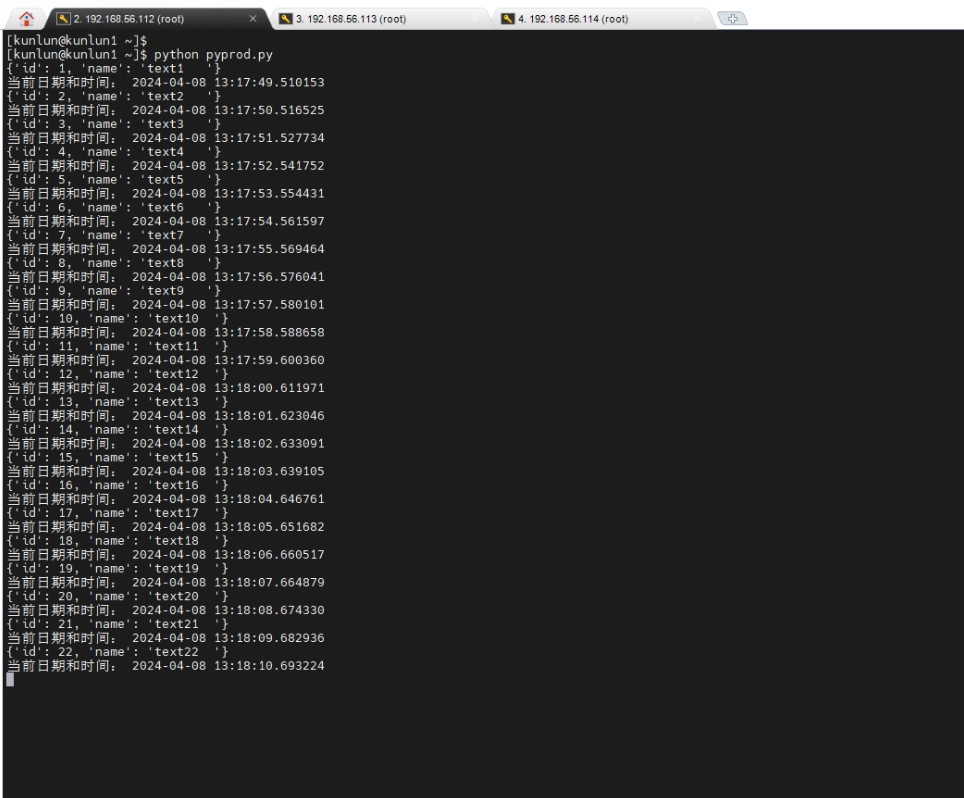
6.3 运行pyprod.py脚本,持续对数据库进行操作
[kunlun@kunlun1 ~]$ python pyprod.py
_
6.4 查看当前跨城IDC HA集群的主备IDC,查看“集群列表信息”,主节点是“192.168.56.113”,同城(IDC2)备节点是“192.168.56.114”和跨城(IDC3)备节点是“192.168.56.112”。然后点击“设置”按钮
_
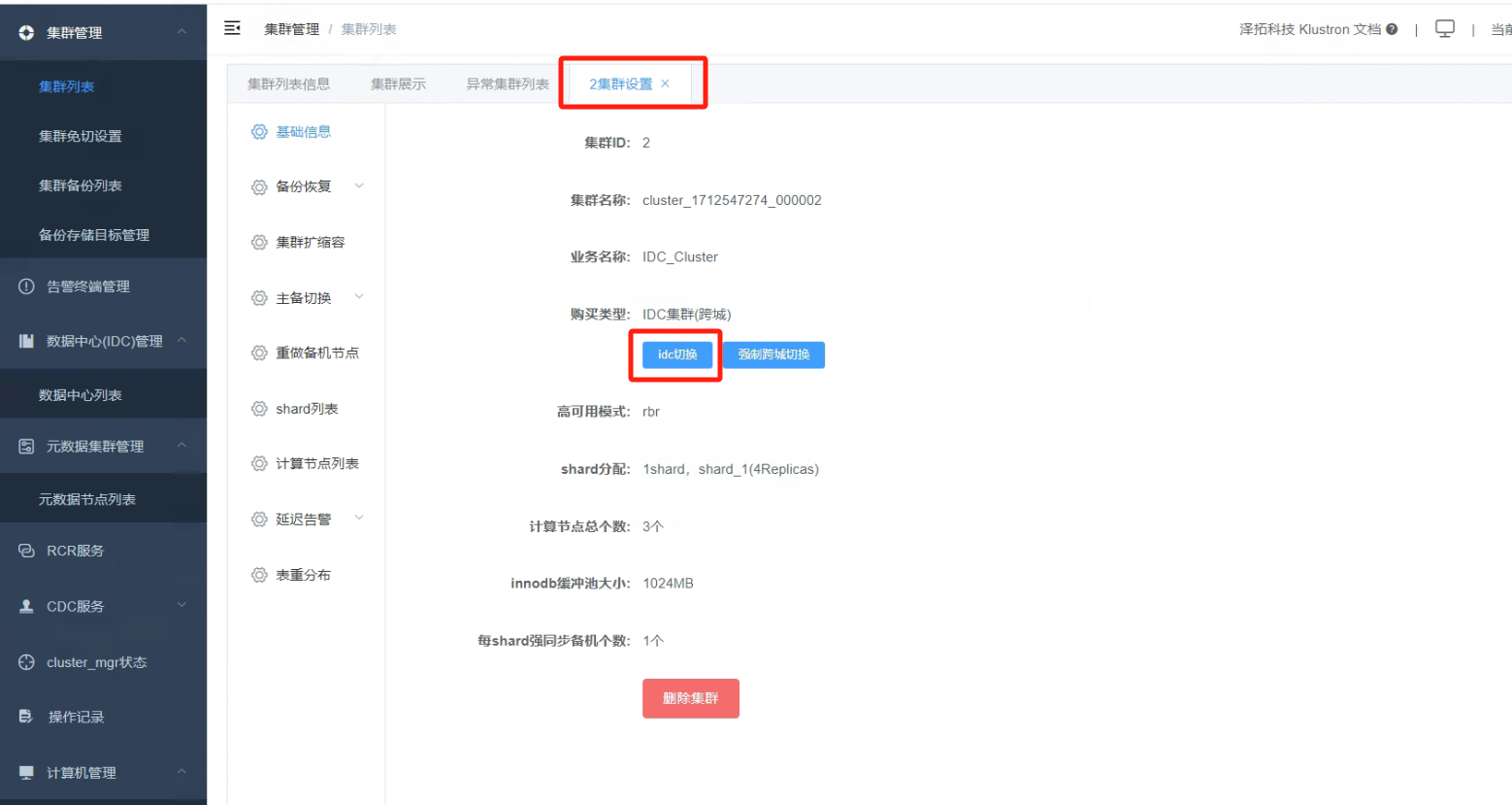
6.5 在“集群设置”界面里,点击“idc切换”按钮,做IDC的主备切换
_
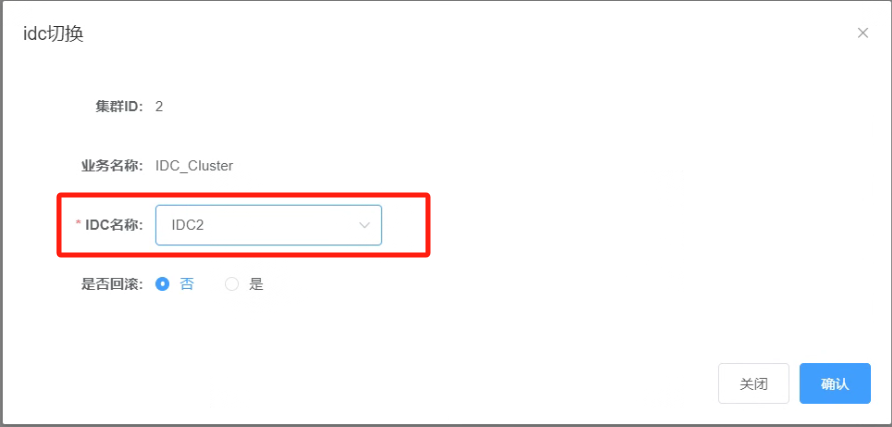
6.6 在IDC切换界面,选择同城IDC名称“IDC2”
_
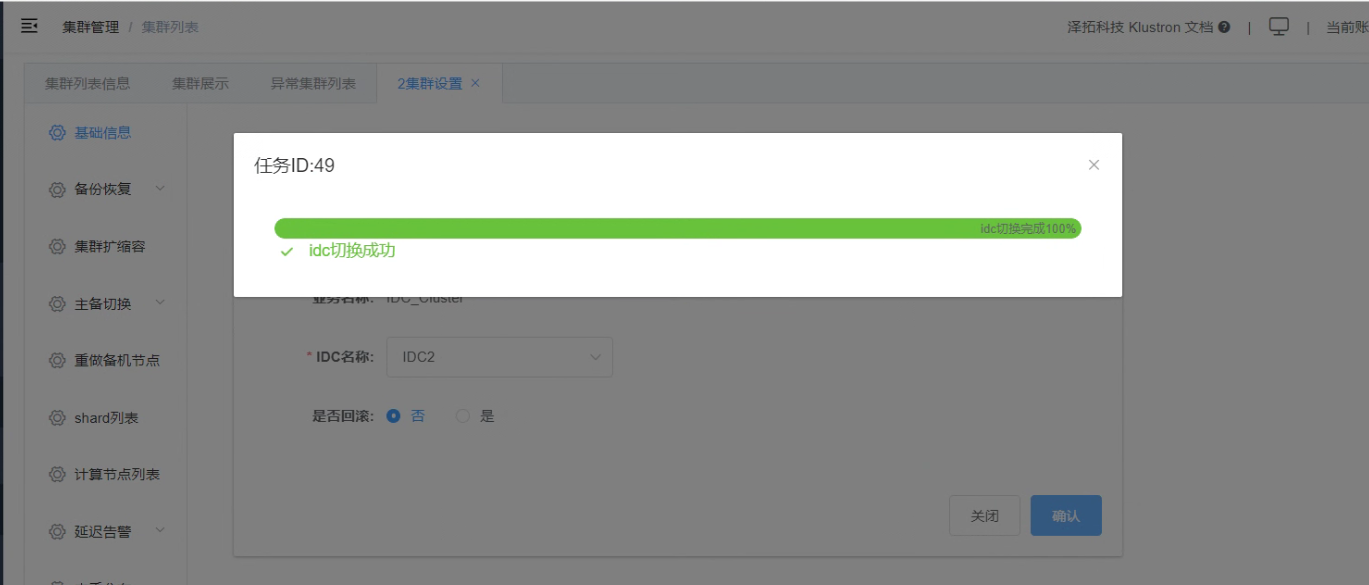
6.7点击“确认”,查看IDC切换任务的完成
_
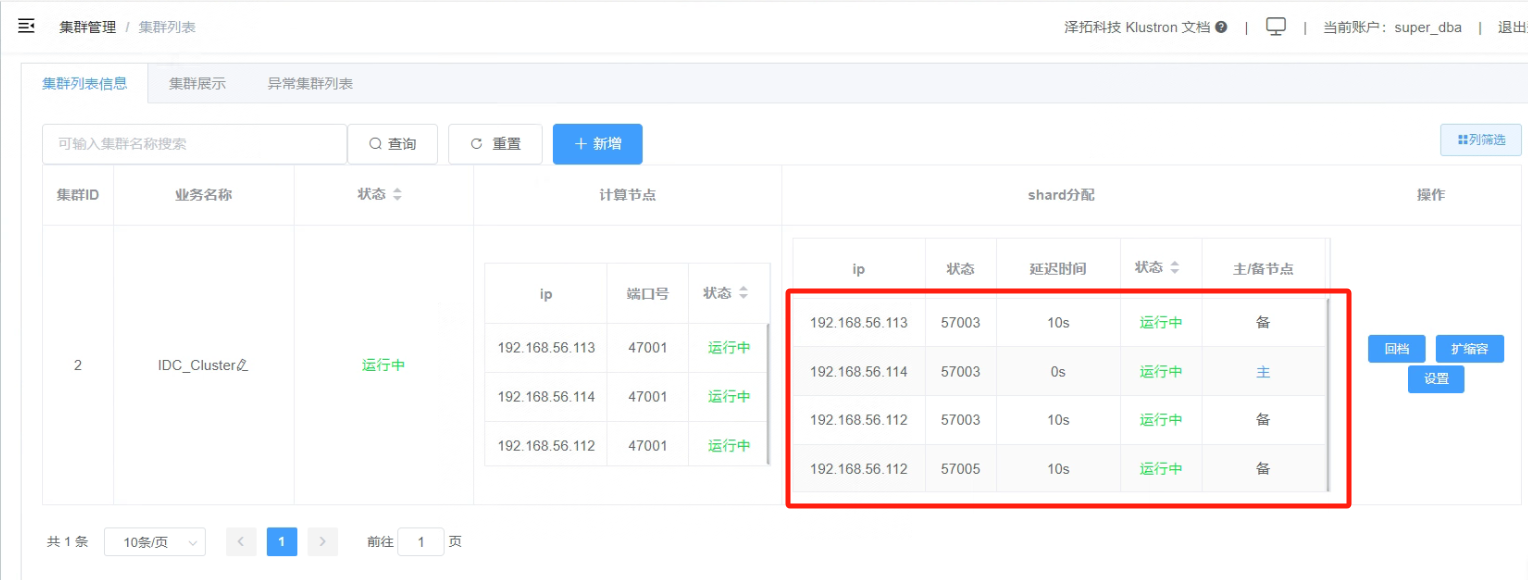
6.8 主备IDC切换完成,查看“集群列表信息”,主节点变为“192.168.56.114”,同城(IDC1)备节点是“192.168.56.113”和跨城(IDC3)备节点是“192.168.56.112”。
_
6.9 主备IDC切换,应用程序继续访问操作数据表,持续对数据库进行操作
_
07 跨城 IDC HA 集群跨城主备 IDC 切换测试
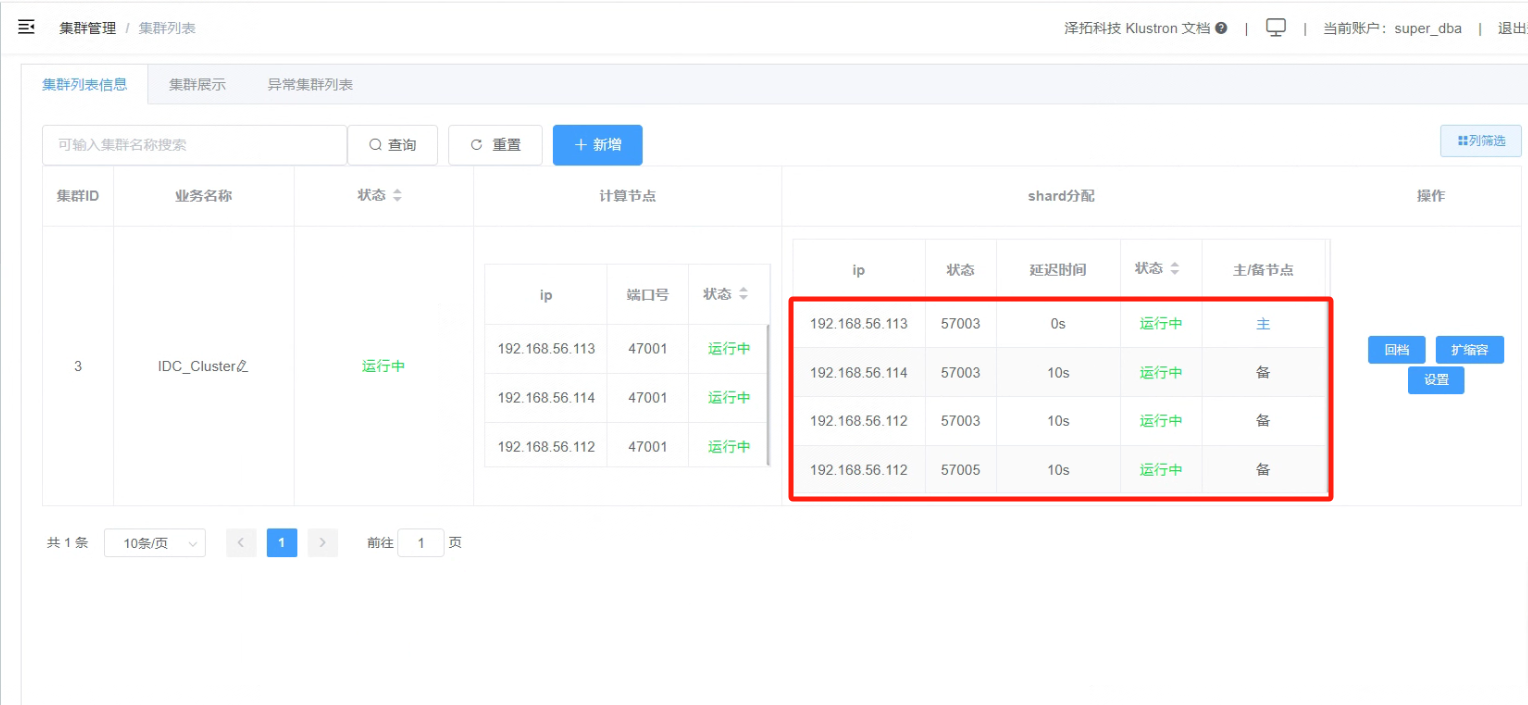
7.1 查看当前IDC HA集群的主备IDC,查看“集群列表信息”,主节点(IDC1)是“192.168.56.113”,同城备节点(IDC2)是“192.168.56.114”,跨城备节点(IDC3)是“192.168.56.112”
_
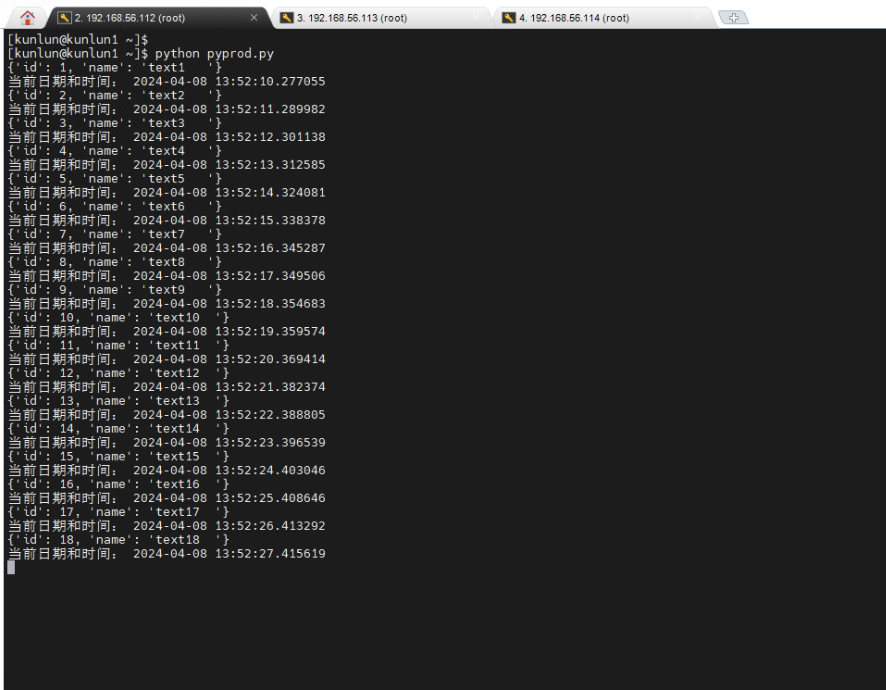
7.2在做跨城IDC切换之前,运行pyprod.py脚本,持续对数据库进行操作
[kunlun@kunlun1 ~]$ python pyprod.py
_
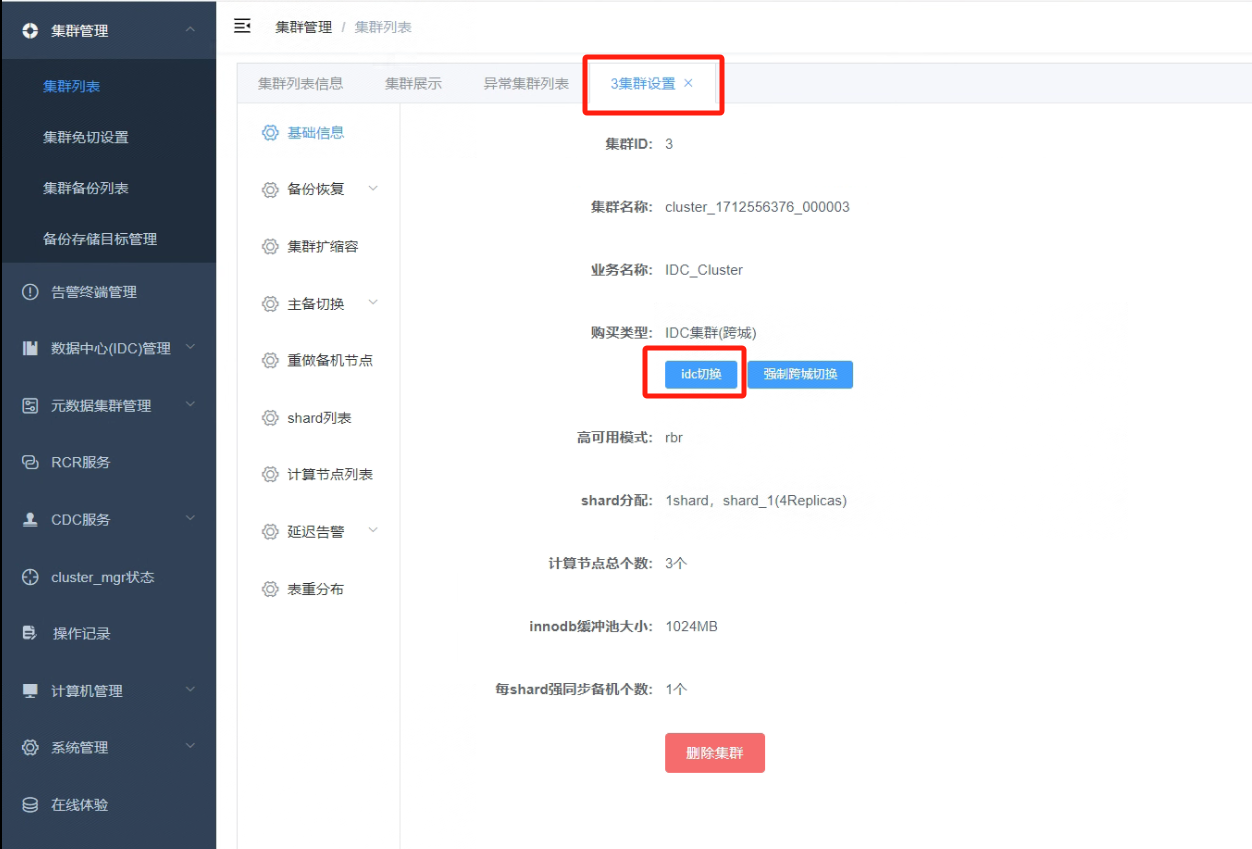
7.3 在“集群设置”界面里,点击“idc切换”按钮,做IDC的主备切换
_
7.4 在IDC切换界面,选择跨城IDC名称为“IDC3”
_
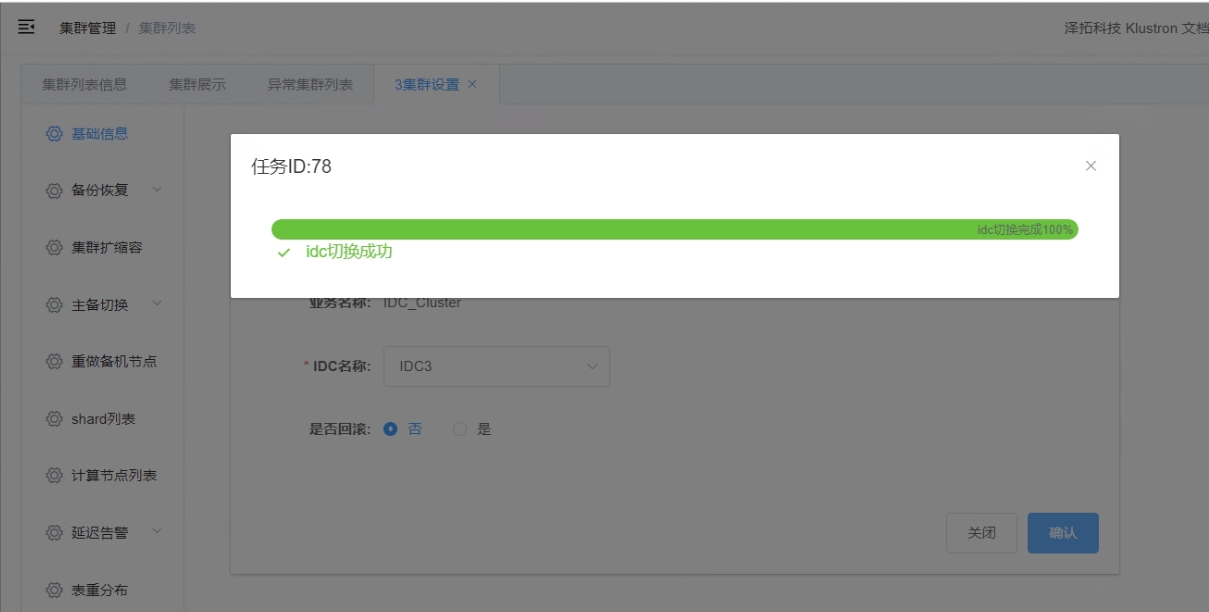
7.5 点击“确认”,查看跨城IDC切换任务的完成
_
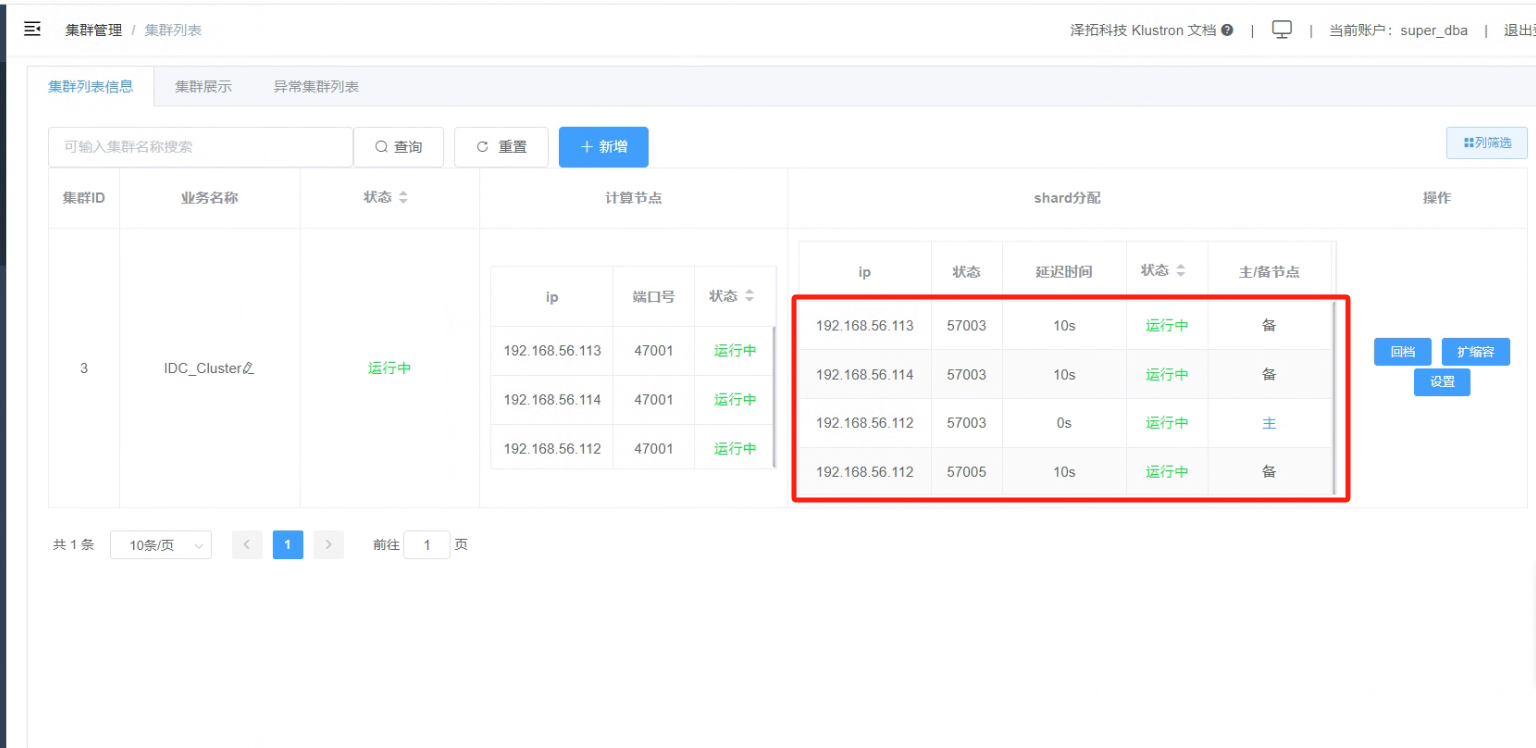
7.6 跨城IDC切换完成,查看“集群列表信息”,主节点变为“192.168.56.112”,备节点变为“192.168.56.113”和“192.168.56.114”
_
7.7 跨城IDC切换,应用程序继续访问操作数据表,持续对数据库进行操作
_
08 跨城 IDC HA 集群强制跨城切换测试
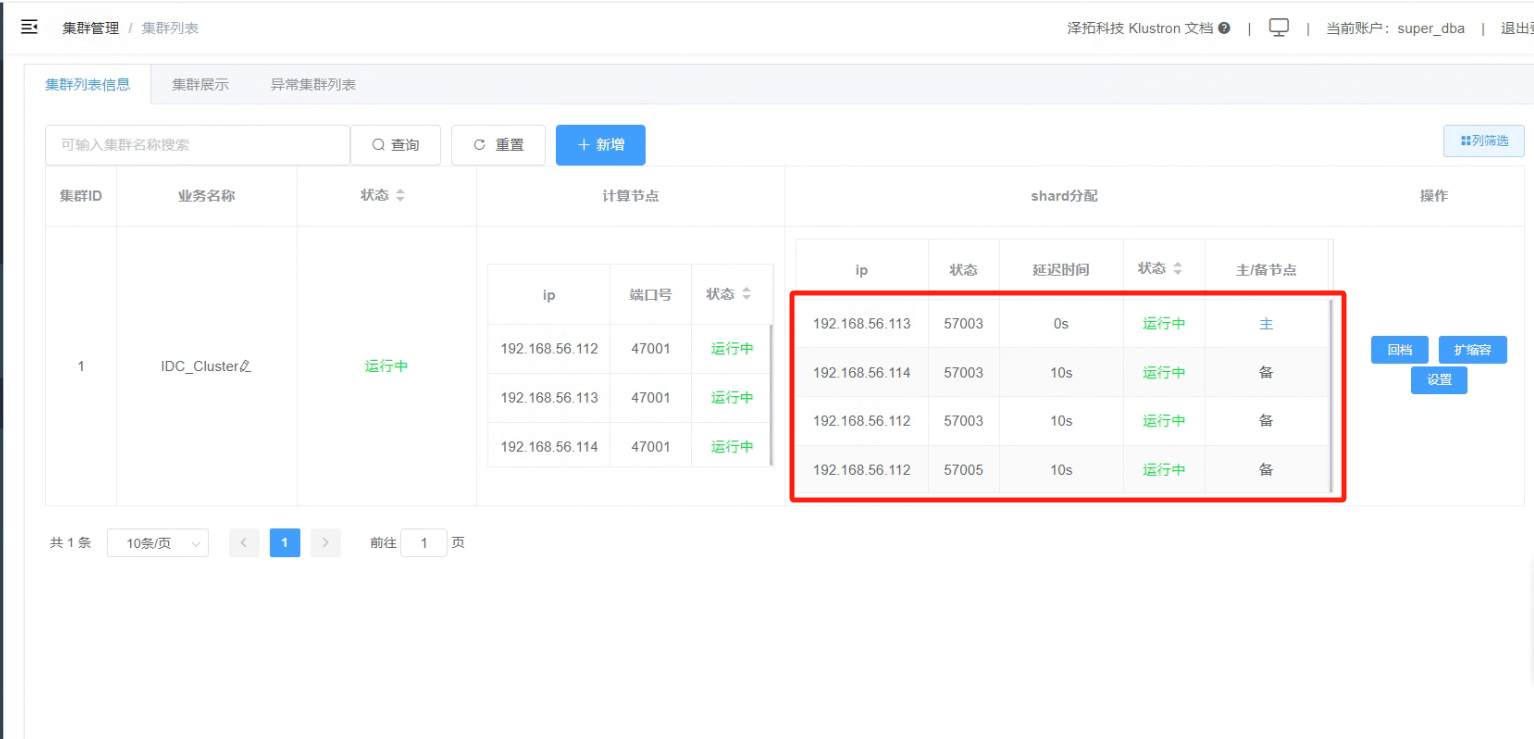
8.1 查看当前IDC HA集群的主备IDC,查看“集群列表信息”,主节点(IDC1)是“192.168.56.113”,同城备节点(IDC2)是“192.168.56.114”,跨城备节点(IDC3)是“192.168.56.112”
_
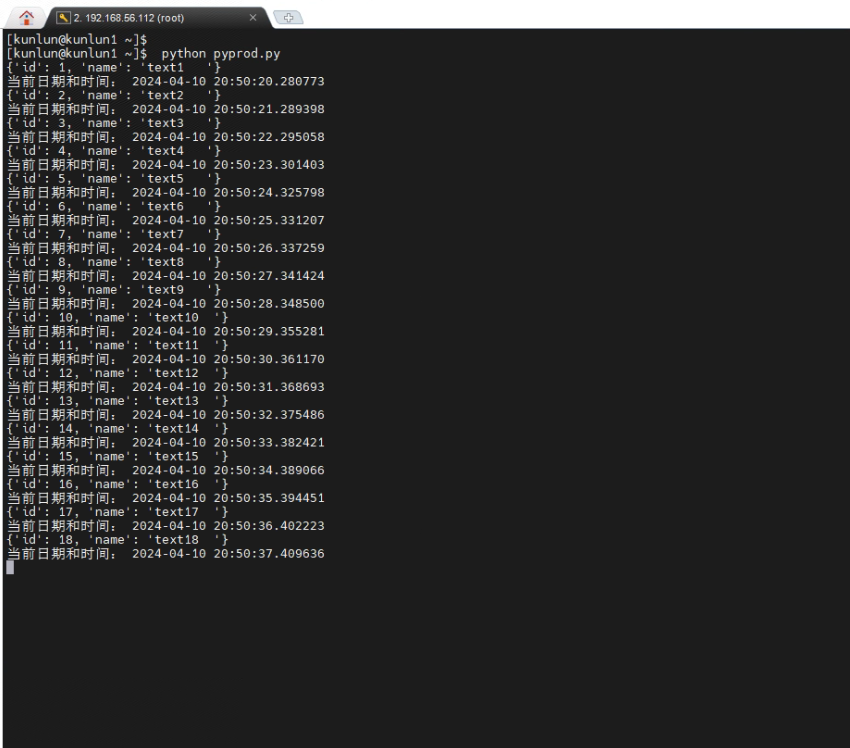
8.2在做跨城IDC切换之前,运行pyprod.py脚本,持续对数据库进行操作
[kunlun@kunlun1 ~]$ python pyprod.py
_
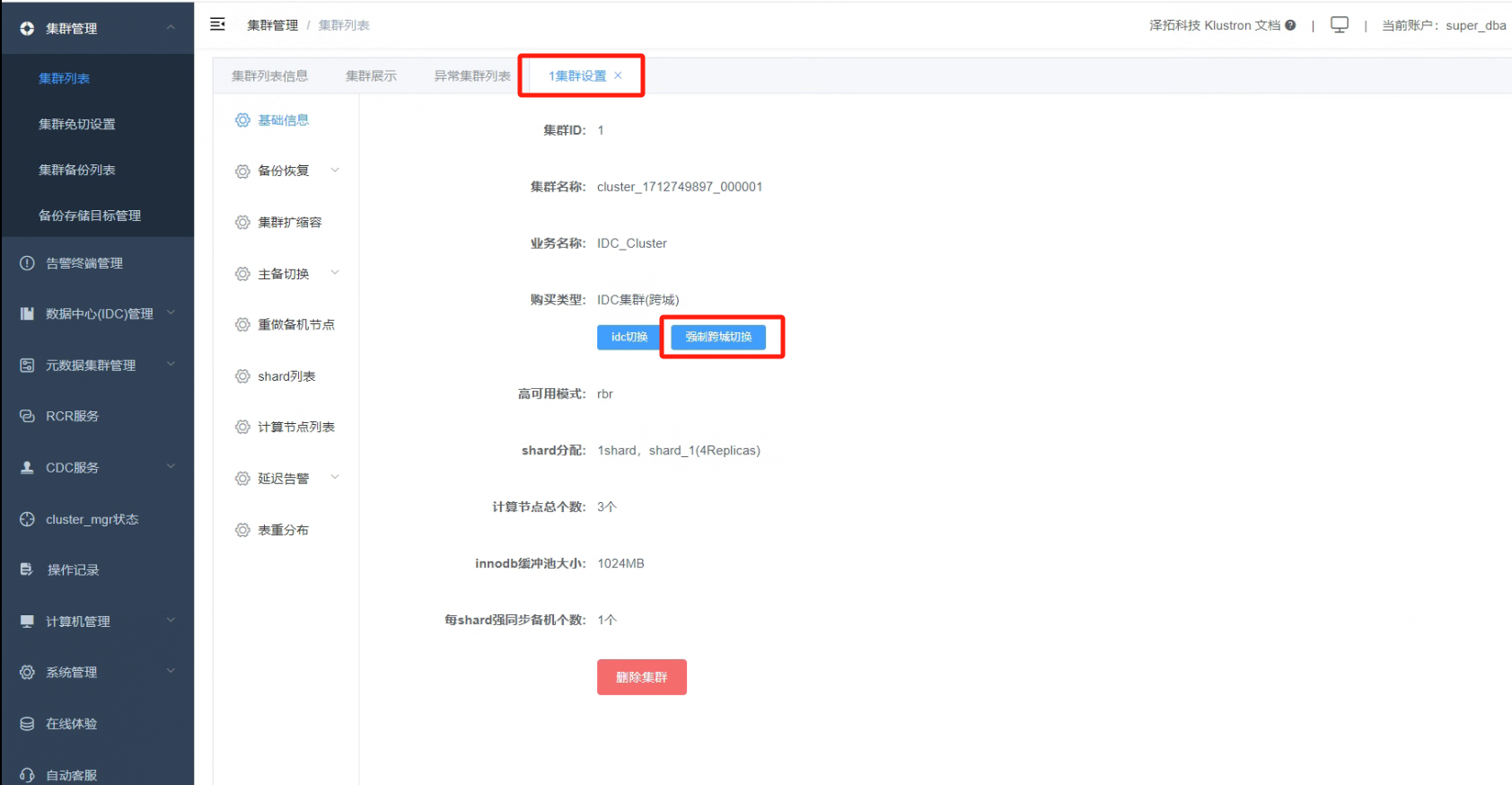
8.3 在“集群设置”界面里,点击“强制跨城切换”按钮,做IDC的主备跨城切换
_
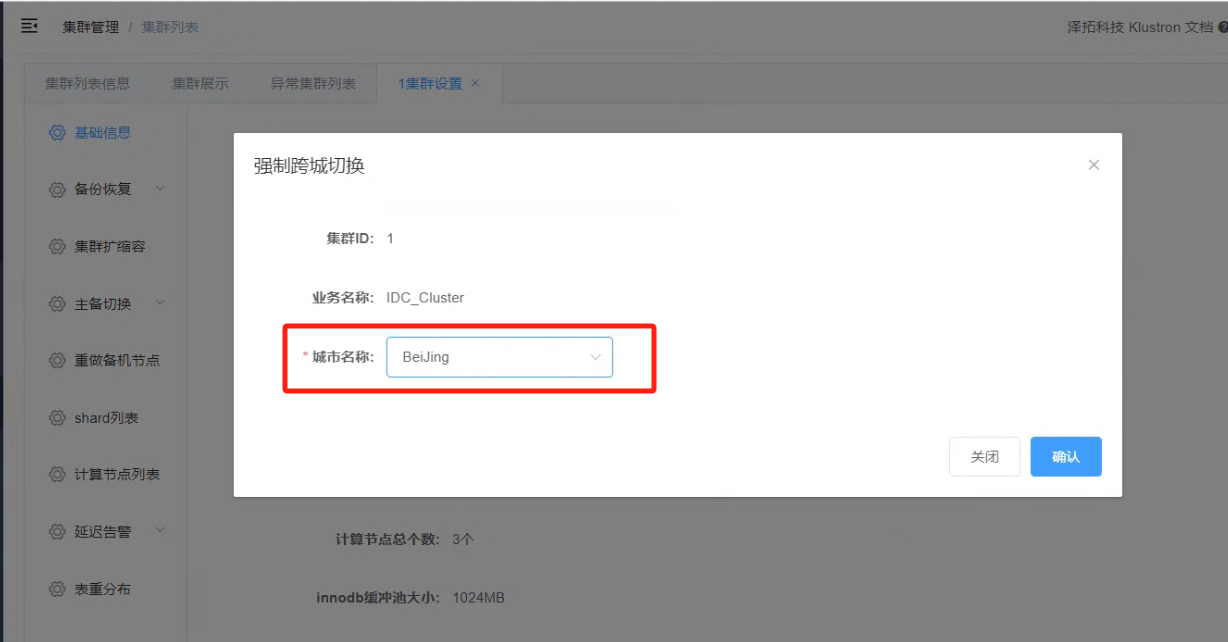
8.4 在强制跨城切换界面,选择跨城城市名称为“BeiJing”
_
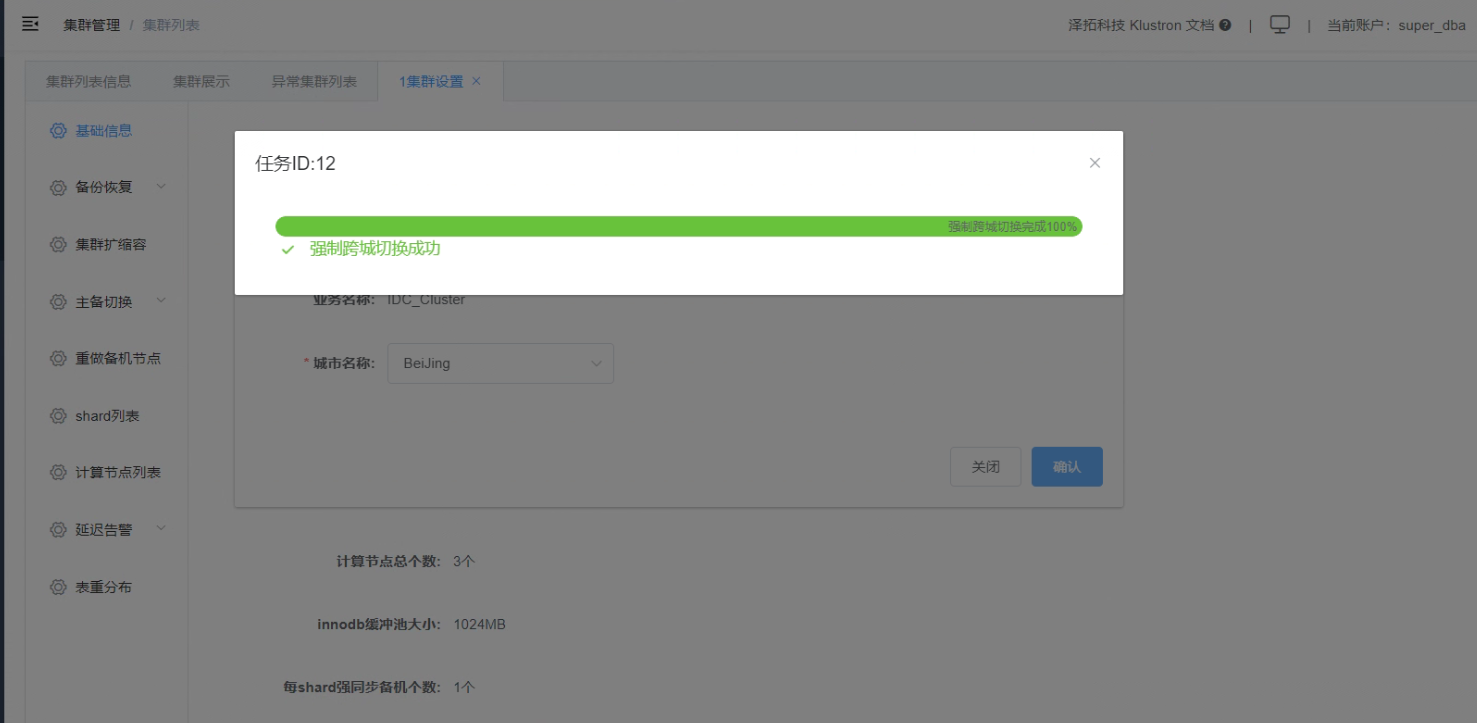
8.5 点击“确认”,查看跨城强制切换任务的完成
_
8.6 跨城IDC切换,应用程序继续访问操作数据表,持续对数据库进行操作
_
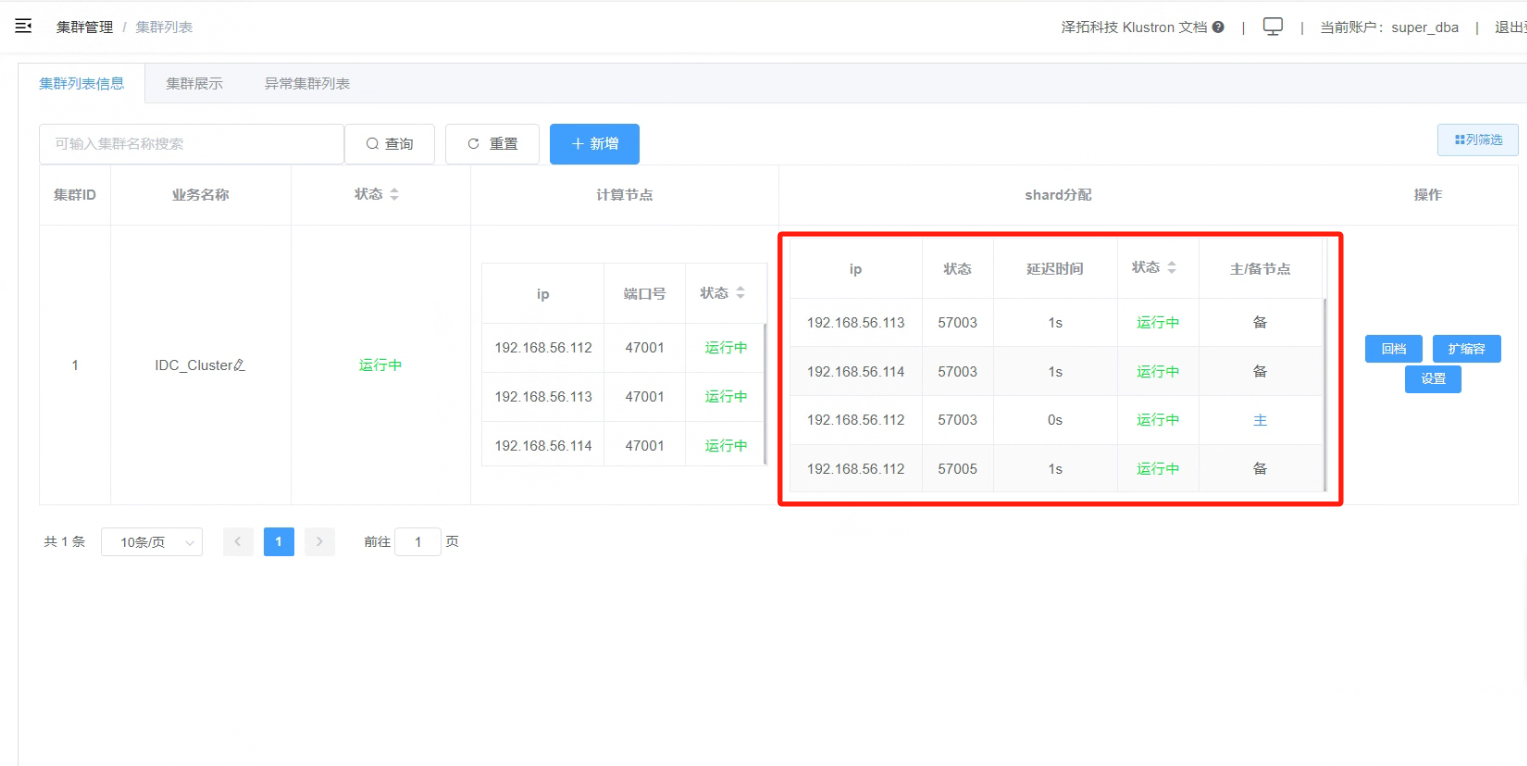
8.7 跨城IDC HA集群强制跨城切换完成,查看“集群列表信息”,主节点变为“192.168.56.112”,备节点变为“192.168.56.113”和“192.168.56.114”
_
至此,两地三中心跨城IDC HA集群创建配置,及跨城IDC HA集群同城主备IDC切换测试、跨城IDC HA集群跨城主备IDC切换测试和跨城IDC HA集群强制跨城切换测试完成。