
Klustron Read-Write Splitting Solution
Klustron Read-Write Splitting Solution
Klustron cluster supports read-write splitting within the database and is transparent to the application. Users do not need to make any modifications to use the read-write splitting function of the database, thereby improving the performance and return on investment of the entire system.
1. Product Architecture
The overall architecture of Klustron consists of a computing layer and a storage layer. The computing layer is responsible for SQL response, interpretation, execution, etc., and the storage layer is responsible for data storage management. The data in the storage layer is stored using a multi-replica storage mechanism, and the slave node (slave replica) maintains data consistency with the master node through strong synchronization technology.
The hardware configuration of the slave storage node is consistent with that of the master node. In general production usage, the main purpose of the slave node is to serve as a replacement node when the master node fails, and it does not directly handle data processing requests from applications. Therefore, in the case of non-fault switch, the storage node resource utilization of the slave is relatively low.
Klustron's read-write splitting solution routes read-only operations to the slave nodes, which can reduce resource competition on the computing nodes and reduce the load on the master node.

2. Implementation Principles
Klustron's read-write splitting is implemented in the remote query optimizer of the computing layer. When the user's SQL meets the following conditions at the same time:
- The current SQL type is select;
- The SQL does not contain user-defined functions (i.e., functions created by the create function statement), unless the current transaction is a read-only transaction;
- If the statement is not in a transaction (autocommit=on), read-write splitting is allowed. If the statement is in an explicit transaction, it must meet the following requirements:
- If in a read-only transaction, read-write splitting is allowed;
- If in a read-write transaction, the transaction has not updated any data yet;
The remote query optimizer will then push the corresponding SQL execution plan to the slave node for execution.
Klustron-server chooses which slave node to send select statements to based on the following rules:
- Select according to node weight value (ro_weight)
- According to network latency (ping)
- According to the data consistency delay of the master-slave replica (latency)
3. Configuration Implementation
Scenario: A certain OLTP business system has a large number of query operations. During the business peak period, the database response speed slows down, causing performance problems in the business. After inspection, it was found that the IO resource utilization of the storage node of the master node of the storage node reached a bottleneck, but the IO resource utilization of the slave node was low.
The above scenario can be solved by the read-write splitting solution, without modifying the application or adding hardware configurations. By implementing read-write splitting, performance problems can be solved.
Implementation Steps:
Step 1: Set parameters and enable read-write splitting. (Choose one level according to the situation)
Set enable_replica_read = on (on to enable read-write splitting and off to disable).
Enable at User Level: (Effective after user login)
alter user abc set
enable_replica_read = true;
Enable at Session Level: (Effective for the current session)
set enable_replica_read=on;
Enable at Database Level: (Effective for all sessions of the computing node)
Set in pg_hba.conf file
enable_replica_read=on;
Step 2: Log in to the database and configure the read-write splitting strategy.
Set the following parameters to start the read-write splitting strategy:
replica_read_ping_threshold, Ping delay threshold from the computing node to the slave node, where 0 indicates that it is not concerned;replica_read_latency_threshold, Threshold for the delay of master-slave synchronization, where 0 indicates that it is not concerned;replica_read_order, Priority for selecting the slave machine: 0, by weight; 1, by ping delay; 2, by master-slave synchronization delay;replica_read_fallback, The fallback strategy for selecting slave machines (if the slave machine cannot be accessed);replica_read_fallback=0, report an error directly;replica_read_fallback=1, select any slave machine to access;replica_read_fallback=2, select the master machine to access.
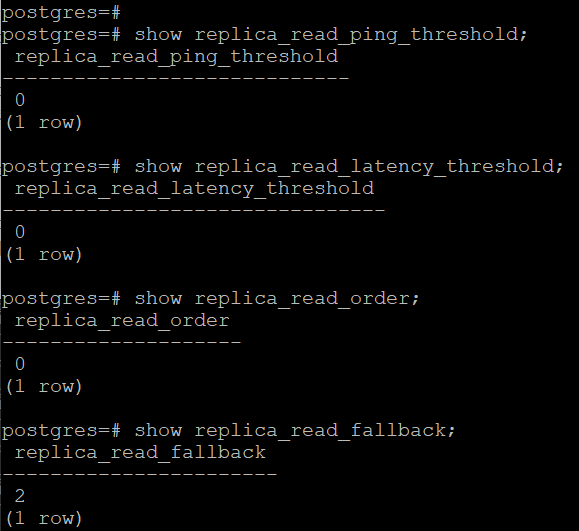
Step 3: Check & set weights (optional).
In the demo environment, the data cluster consists of two shards (shard1, shard2), where shard1 has a shard_id of 1 and contains three replicas (with ids 1, 2, and 3). Replica 1 is the master node, while replicas 2 and 3 are slave nodes.
By configuring the system, you can set the preferred slave machine for read-only operations.
To set node3 on Shard1 as the preferred slave node (because node2 is located in a different data center and has high latency), execute the following command:
update pg_shard_node set ro_weight=2 where
port=6006;
Select * from pg_shard_node ;
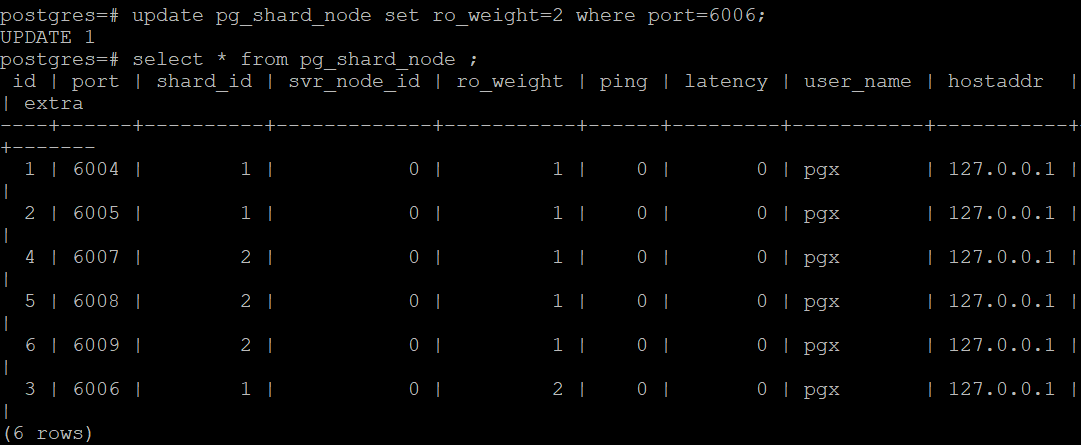
Node3 of Shard1 has the highest weight (ro_weight=2)
Step 4: Execute the query to verify read-write splitting (optional).
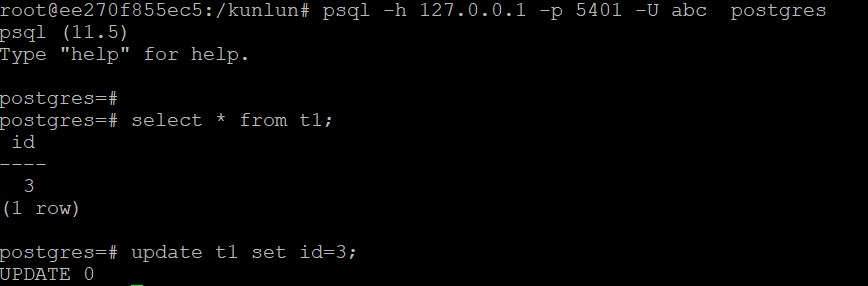
By setting log_min_messages to 'debug1', SQL execution information can be output to the log for checking the target storage node of the SQL execution (do not set it in the production system, otherwise it will affect performance).
Check the logs of the computing node to confirm read-write splitting.
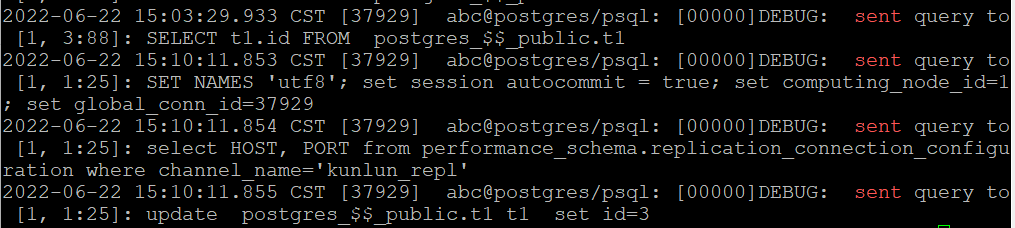
The SQL read-only statement (select ti.id from t1) is sent to shard1, node3 (the replica with the highest weight), while the update statement (update t1 set id=3) is executed on the master node shard1 node1.
Conclusion
The above process verifies the implementation of read-write splitting for the user. The read-only statements will be routed to the slave nodes, reducing the IO resource utilization of the master node and improving the overall system performance.