
MySQL Technology Insider Series Sharing: Detailed Explanation of JSON-Related Features
MySQL Technology Insider Series Sharing: Detailed Explanation of JSON-Related Features
This issue's golden quote:
With the gradual improvement of MySQL's official support for JSON data processing, using JSON data in MySQL will become increasingly convenient and fast.
With the rapid development of Internet applications, the storage and application of semi-structured and unstructured data have brought new demands to all database systems. MySQL has also developed rich features to handle such data according to its own characteristics. This sharing will provide a detailed introduction to how MySQL processes JSON data, with a focus on JSON data indexing. Hopefully, through this sharing, everyone can gain a relatively comprehensive understanding of how MySQL handles JSON data.
1 JSON Data Processing in MySQL
JSON (JavaScript Object Notation) is a lightweight data interchange format primarily used for Internet application services. It is generally considered a form of semi-structured data.
In order to adapt to the rapid development of internet applications, MySQL has also supported the processing of JSON data starting from MySQL version 5.7, and has added more support for JSON data in subsequent versions;
Using JSON in MySQL brings the following benefits:
• Data can be handled flexibly: The contents of fields can be quickly expanded, avoiding the need to add columns; JSON data is organized in key-value pairs, and the information within it can be flexibly increased or decreased as needed, so there is no need to add or remove columns like in traditional tables to add or remove new data information.
• Reduce unnecessary storage space: Avoids NULL values in sparse fields, reducing the storage space they occupy; JSON data can avoid using space to store NULL value information, thereby saving some storage space for such data.
• Support for indexing JSON elements: Compared to JSON in string format, the JSON type supports indexing for specific query optimizations; the official version 8.0 now supports indexes based on generated columns and multi-valued indexes, making queries on JSON data faster and more efficient.
• Cross-data-type queries: It is more convenient to query structured and unstructured data together. Because structured data and unstructured data can be placed in the same table, a single SQL statement can be used to query these data together.
Methods for accessing JSON in MySQL:
• Create a table with JSON fields;

• Like other types of fields, directly insert or modify JSON data;

• Query JSON field content as easily as string types;

• You can directly query the corresponding property value by specifying the attribute name of the JSON field.

• Remove JSON values using JSON_REMOVE

• Update attribute values through JSON_SET, JSON_INSERT, JSON_REPLACE

In addition, MySQL also provides the following commonly used functions to handle JSON data:
• JSON_EXTRACT : Used to extract the required field content from JSON data
• JSON_UNQUOTE : Its function is to remove the outermost double quotes
• MEMBER OF: Can only be used on JSON arrays, returns 1 if the element exists in the array, 0 if the element does not exist in the array
• JSON_CONTAINS: Can be used with JSON arrays and JSON objects. For JSON arrays, it checks whether one or multiple elements exist. For JSON objects, it checks whether a specific value exists at a specified path or whether a specific path (key) exists.
• JSON_OVERLAP: Compares whether two JSON arrays have at least one element in common; if so, returns 1, otherwise returns 0. If it is a JSON object, it checks whether there is a pair of key-value that matches.
• JSON_KEYS: Returns the keys of a JSON object, can also be nested JSON objects
2 MySQL JSON Data Indexing
In order to more conveniently and quickly query information within JSON data, MySQL also provides indexing features for JSON data. This section will focus on introducing how MySQL creates indexes on JSON data.
Indexing Based on Generated Columns ( Indexing JSON via a generated column)
1: MySQL can index JSON data by creating generated columns and adding indexes on them, for example;
ALTER TABLE customers ADD COLUMN zip_code INTEGER GENERATED ALWAYS as (user_info->"$.zipcodel");
ALTER TABLE customers ADD INDEX zip_code (zip_code) USING BTREE;
2: In versions of MySQL after 8.0.13, JSON data can be indexed by directly creating function indexes, for example;
ALTER TABLE customers ADD INDEX zip_code (CAST(user_info->"$.zip_code" as INTEGER)) USING BTREE;

As shown in the figure above, users can create a generated column on the user_info JSON field, and then create a B-tree index on this column, as shown on the right, to achieve fast search of the zip_code information within user_info.
Multi-valued Indexing
Versions of MySQL after 8.0.17 can index JSON array data by directly creating multi-valued indexes, for example;
• Create a multivalued index:
CREATE INDEX zips ON customers ( (CAST(custinfo->'$.zipcode' AS UNSIGNED ARRAY)) );
ALTER TABLE customers ADD INDEX comp(id, modified, (CAST(custinfo->'$.zipcode' AS UNSIGNED ARRAY)) );
• Query using an index:
SELECT * FROM customers WHERE 94507 MEMBER OF(custinfo->'$.zipcode’);
SELECT * FROM customers WHERE JSON_CONTAINS(custinfo->‘$.zipcode’,CAST(‘[94507,94582]’ AS JSON));
SELECT * FROM customers WHERE JSON_OVERLAPS(custinfo->'$.zipcode',CAST('[94507,94582]' AS JSON));

As shown in the above figure, for the zip_code information in the JSON data column user_info, because it has multiple values, that is: an array of integers, users create a B-tree multivalue index in MySQL as shown on the right to index this data in order to achieve fast searching of such data.
3 KlustronDB's JSON Data Processing
Currently, KlustronDB also provides basic support for JSON data. First, let's take a look at the overall architecture of KlustronDB:
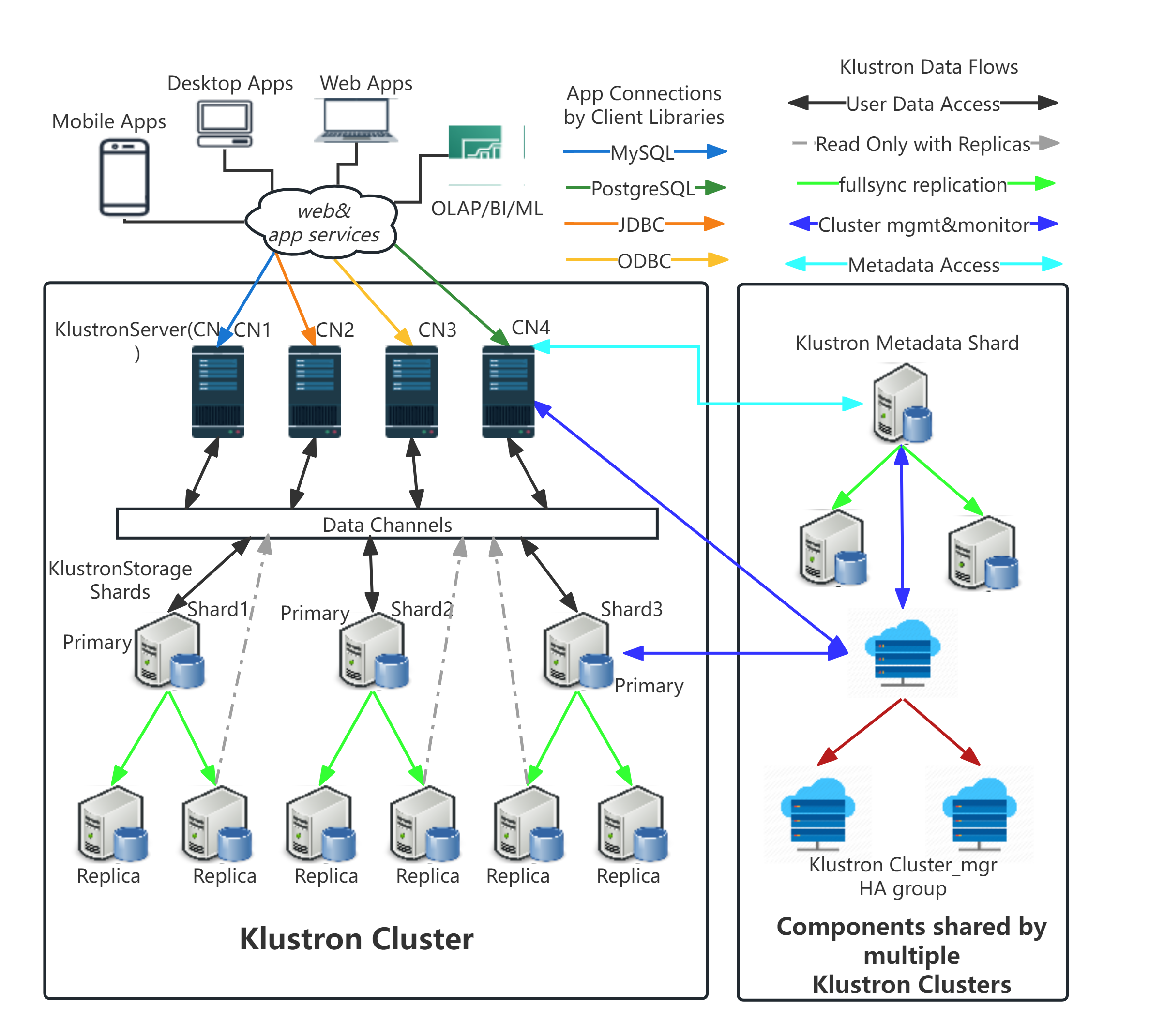
As shown in the picture above, our KlustronDB is a typical distributed database system with separated storage and computing. The computing nodes are implemented based on PostgreSQL, taking advantage of PostgreSQL's powerful query optimization capabilities. The storage nodes, on the other hand, are implemented based on MySQL, which has a better storage engine.
Therefore, at the current stage (KlustronDB version 1.2): it temporarily only supports PG's JSON functions and operators to access JSON data.
We are developing a method that combines computing nodes and storage nodes to process JSON, using the indexes of storage nodes to accelerate JSON data processing to support more efficient JSON data storage and querying.

4 Q&A Discussion
Live Q1: Could you briefly compare how PG and MySQL handle data and indexing?
Answer: As far as I know, MySQL's support for JSON data is relatively slower compared to PostgreSQL. PostgreSQL provided support for JSON data quite early and allows B-tree, HASH, GiST, and GIN indexes on JSON data, whereas MySQL can only create B-tree indexes. So, in terms of features, PostgreSQL's support for JSON data is ahead of MySQL. As for performance, we haven't done a comparison yet; interested readers can run some tests, and it is estimated that each has its strengths, with advantages depending on different scenarios. However, in the future, because of the advantage of being later to develop, MySQL might have more potential for performance optimization.
Live Q2: May I ask how we should choose between using JSON fields or regular fields?
Although using JSON data has some of the benefits mentioned earlier, it is not suitable for all scenarios. Handling JSON data also brings some additional overhead, such as parsing JSON data and converting its data types, which can make accessing data take more time than ordinary field data. Therefore, whether to use JSON data should be considered based on the usage scenario and data characteristics. For example, if the data is rarely changed, table structure changes are uncommon, frequent access is required, and high access performance is necessary, such scenarios still need to use traditional structured data fields. If the data structure changes frequently, access is not particularly frequent, and performance requirements are not very high, such scenarios can consider using JSON.