
查询优化流程
大约 2 分钟
查询优化流程
Klustron(原KunlunBase)是计算和存储分离的分布式数据库系统,当一条查询 SQL 发送到 KunlunBase 任一计算节点(CN)时,Klustron语法解析器(Parser)首先会对原始查询文本做出解析以及一些简单的合法性验证,之后会对查询做逻辑优化:如查询重写,分区修剪,列裁剪,谓词下推等。
Klustron在逻辑优化过程中会采取最大下推的策略。
计算下推不但可以避免 CN 和 DN 间数据网络交互还可以充分利用多分片并发执行的能力和各个 DN 资源,加速查询。
优化后的算子分为两类:
可以下推的算子:RemoteScan 将该算子推送到对应的数据节点上执行,执行完成后拉取相应的数据到计算节点做后继处理。支持下推的算子包括:过滤条件,如 WHERE 或 HAVING 中的条件。聚合算子,如 COUNT,GROUP BY 等,会分成两阶段进行聚合计算。排序算子,如ORDER BY,JOIN和子查询。Project,投影操作。Distinct排重。
无法下推的部分算子:如跨 shard 的join,需要将数据从数据节点拉取到计算节点做计算,优化器会选择最优的方式来执行,如选择合适的并行度策略等
全局执行流程如下:
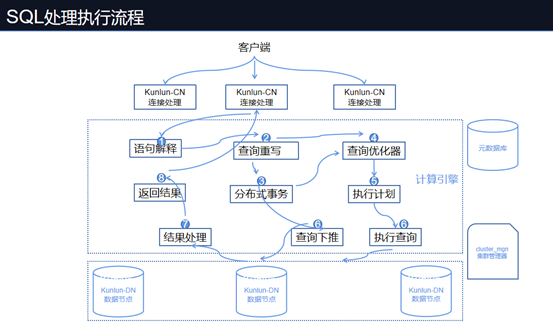
优化流程如下:

最大下推策略如下:

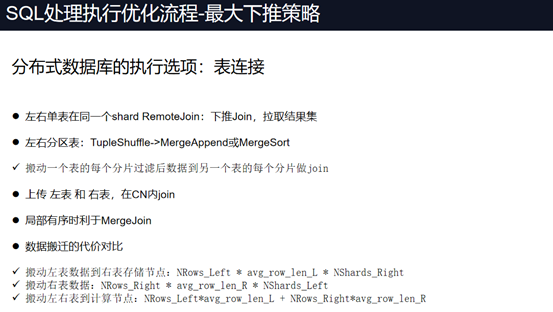
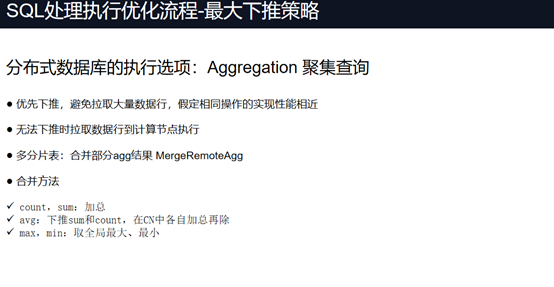
综述:为获取最大性能,在定义分区键时要充分考虑业务在执行SQL 语句的场景,以最大限度避免跨节点数据操作。