
KunlunBase多层级并行查询处理技术
KunlunBase多层级并行查询处理技术
背景
本文重点介绍KunlunBase如何在全集群范围内把分布式查询任务在多层级并行执行,充分利用计算节点和多个存储节点中的大量CPU核心,内存和存储资源,实现优秀的查询处理性能。在最理想的情况下,KunlunBase可以做到用集群所有的服务器资源执行同一条查询语句,实现极致的性能。
KunlunBase多层级并行查询处理技术概况
KunlunBase多层级并行查询处理架构分为三个层级 --- 在计算节点内,计算节点与存储节点之间和存储节点内都可以并行执行同一个用户查询语句的多个子任务。下面分别简介这三个层级的并行查询机制。
在计算节点内,KunlunBase继承了PostgreSQL的并行查询架构,并对它做了增强和扩充。PostgreSQL支持使用多进程并行执行符合要求的查询任务,所以优化器会根据查询语句和数据的特征,以及进程数资源限制决定是否使用并行查询处理机制。如果使用的话,那么它会创建若干个工作线程,为它们分配查询计划中可以并行执行的子任务,实现并行查询处理。
计算节点和存储节点之间的并行查询能力,是KunlunBase团队全新设计和开发的,可独立于计算节点的并行查询框架工作,也可与之协作。
KunlunBase的计算节点如果插入、更新、删除多行数据,并且这些行分布在位于多个shard的表分片中,那么计算节点就会异步发送数据读写语句给目标存储节点,而不是依次发数据读写语句给一个存储节点并等待返回结果再发到下一个存储节点。这样,多个存储节点就可以并行地执行数据读写语句。
KunlunBase团队在存储节点kunlun-storage中,研发了一系列新功能,来支持KunlunBase的多层级并行查询处理技术,以便同一个存储节点的多个连接中执行同一个查询的多个只读查询子任务。同时在kunlun-storage中我们实现了新的高性能增量式执行技术来改进prepared statement的fetch()性能,这样可以大幅提升含有limit子句和子查询(无法转为semi-join时)的查询语句的执行性能。
下面详细介绍这三个部分内容。
KunlunBase计算节点并行查询处理
PostgreSQL的多进程并行查询处理架构中,处理用户连接的进程称为backend进程,它负责接收用户的SQL请求,执行请求并最终返回查询结果给客户端,作为执行请求的一部分,它会做查询优化,和串行的查询执行。
如果查询计划有可以并行执行的子树(parallel executable sub-plan, PESP),那么backend进程也称为leader进程。作为查询执行的一部分,leader进程就会根据实例的并行查询资源配置,创建若干个worker子进程执行这个PESP的不同数据区间,每个数据区间称为一个partial plan。
Leader进程按照PESP要读取的数据范围划分子任务(partial plan),并且分配给worker进程去执行。每个worker进程执行的PESP子任务(即partial plan)的树结构完全相同,只是数据区间不同,各自返回没有交集的子结果集给Gather或者Gather Merge 节点来收集workers的结果集。
比如leader进程在查询优化期间把一个要扫描的10万行数据的seqscan串行执行节点转为为4个25000行的Parallel_seqscan子任务,在查询执行时分配给4个worker进程去执行。每个worker执行的都是Parallel_seqscan,只是参数不同,要扫描的数据区间不同。leader进程也会作为一个worker进程来执行其中一个子任务。执行完子任务后,leader进程就执行Gather或Gather Merge节点收集每个worker进程的子结果并且合并为这个PESP的结果,传递给上层节点。
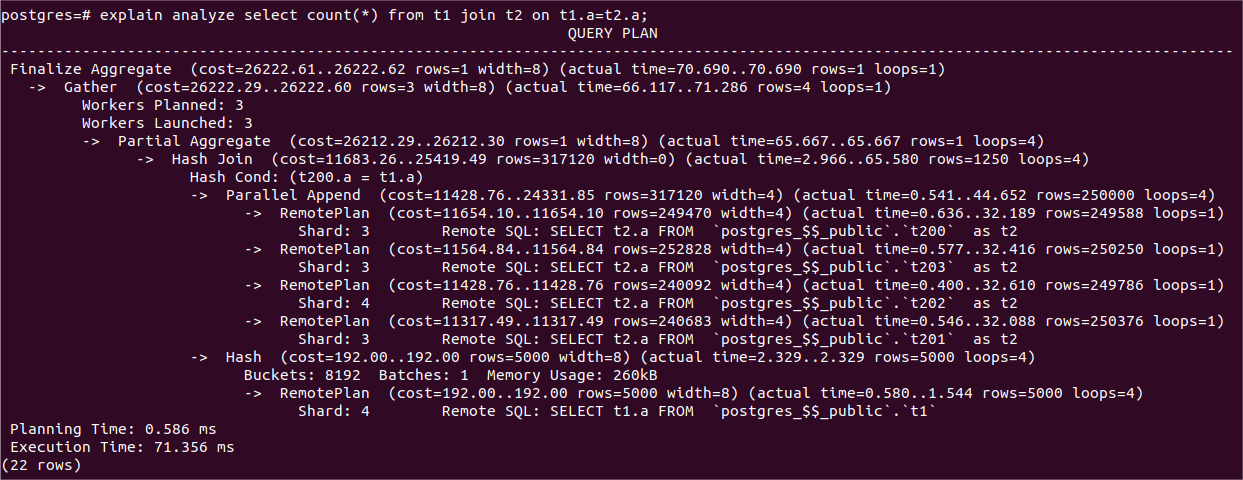
(并行查询示例1)
上图是一个KunlunBase的一个分布式并行查询计划示例,后文内容会逐步涉及到其中的内容,并且会详细分析讲解。
并不是所有的Plan节点都可以并行执行,查询优化器通过获取Plan的并行执行属性来生成查询计划,并行执行属性包括Parallel Safe, Parallel Restricted, Parallel Unsafe三类。Parallel Safe的节点可以位于并行执行计划子树中或者包含并行执行计划的查询计划的其他位置;Parallel Restricted 节点只能位于Gather节点之上,也就是不能位于并行执行计划中;Parallel Unsafe 节点禁止其所属的查询计划被并行执行,含有Parallel Unsafe节点的查询计划完全不可以并行执行;常见的可以并行执行的节点包括:Parallel Append, Partial Aggregate, Parallel Join, Parallel Index/Bitmap/Sequential Scan,不过最后这3类Plan并不会在KunlunBase中用于查询用户数据,因为用户数据存储在存储节点中,不会用到这些Plan节点。
一棵Plan子树的所有Plan节点都可以并行执行(Parallel Safe)时,优化器才有可能把它转换为并行执行计划。不过并行执行计划的所有节点并非都会被拆分为多个子任务来执行,比如hash/nestedloop/merge join的内节点是在每个并行执行的worker中完整执行一遍的,只有外节点的查询执行工作量被拆分为多个子任务分给多个worker进程来执行。只有Paralell Hash Join的内节点是在所有worker 中拆分后由他们并行执行并且共享其数据的。
最后,在查询优化期间和查询执行时,并行执行还受到资源限制变量的限制,包括max_worker_processes,max_parallel_workers_per_gather,max_parallel_workers,这些变量决定了查询优化器会把一个查询计划的可并行的子树拆分为多少个子任务,以及实际执行时会有多少个worker进程来并行执行。
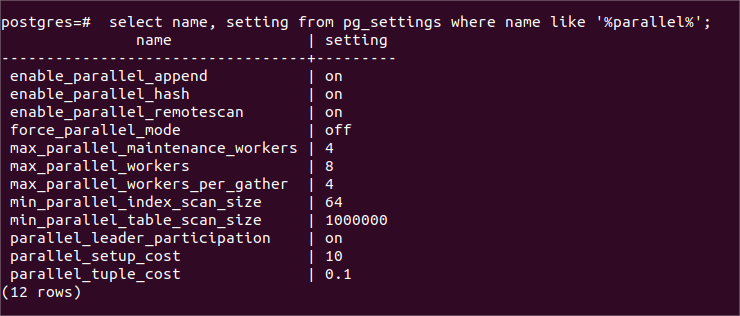
(并行查询的功能开关和资源限制变量)
上图是KunlunBase的计算节点kunlun-server中与并行执行有关的配置变量,包括并行功能开关和并行执行的进程数限制。其中enable_parallel_remotescan是kunlun-server特有的,其余变量继承自PostgreSQL。
上述内容是PostgreSQL-11.5原本就具备的功能,在kunlun-server(KunlunBase的计算节点)中我们完全继承、发挥和利用了上述能力。同时,我们在kunlun-server的优化器中扩展了上述能力到分布式场景中,详见下节。
并行执行Remote Plan
Remote Plan是KunlunBase新增的查询计划节点,用于获取存储节点上的用户数据。在enable_parallel_remotescan开关打开后,kunlun-server的优化器不仅可以把扫描不同表分区的Remote Plan分配给多个partial plan从而让多个worker进程并行执行,还可以依据统计信息把扫描同一个表分区或者未分区的单表的Remote Plan节点按照需要扫描的行的范围拆分为多个Remote Plan子任务,这样即使Remote Plan 需要扫描的是单表也可以并行执行。
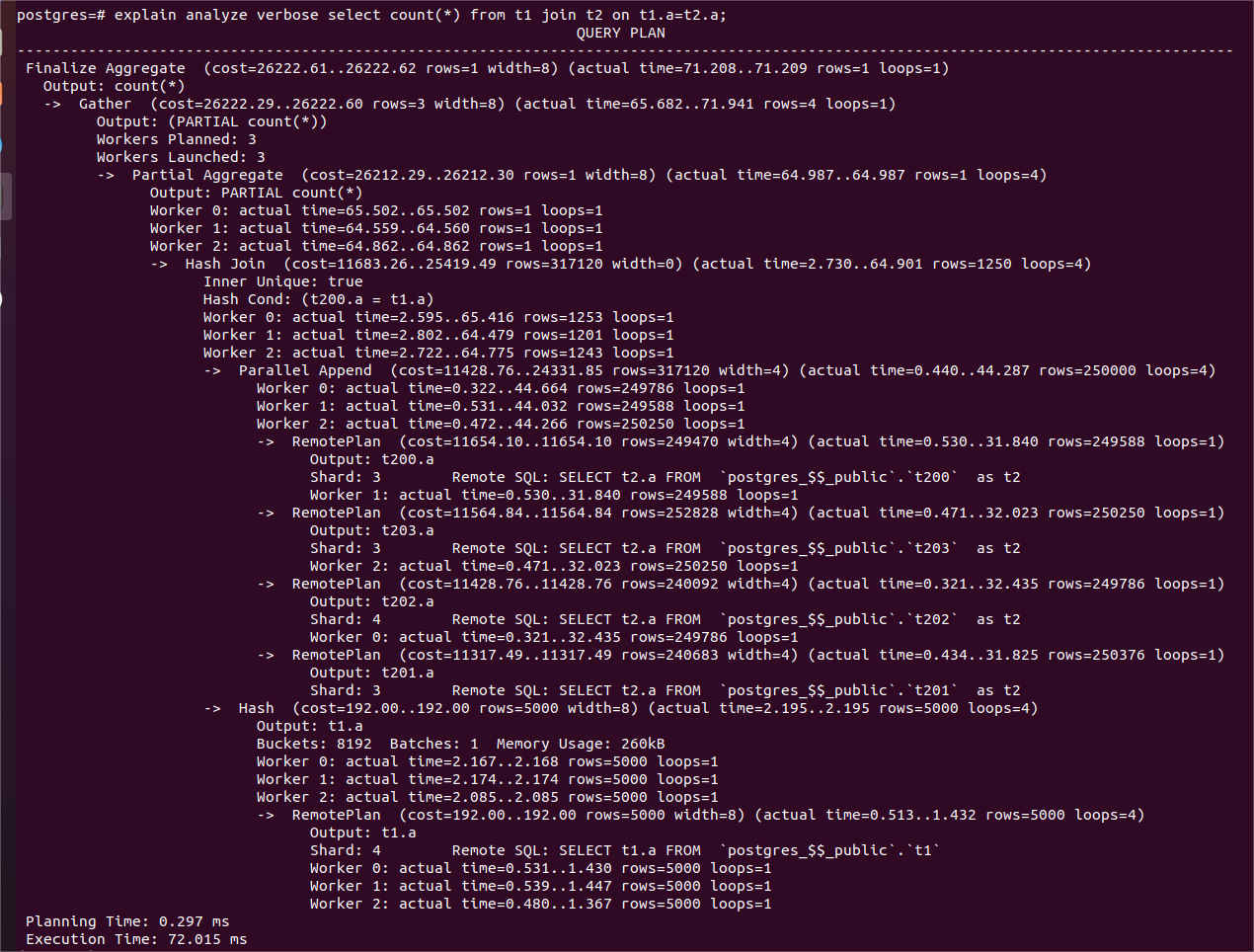
(并行查询示例1的详细信息版本)
上图是kunlun-server产生的一个分布式并行查询计划,从中可以看出:
1、每个worker执行一个RemotePlan 节点扫描t2表的一个表分区,leader进程也执行了一个RemotePlan。
2、T2的3个表分区位于同一个shard 3上面,leader进程和3个worker进程每个各自负责获取一个表分区的数据。他们各自连接到shard 主节点来获取每个表分区的数据,这些连接能够使用相同的快照,从而返回数据具有事务一致性。
3、Hash join的左节点是并行执行的(Parallel Append),而右节点是每个worker都要执行一遍的。所以worker进程没有共享数据,并且造成了一些资源浪费。
4、Partial Aggregate 节点对每个worker自己的Hash Join节点返回的行做了Aggregate。每个worker进程执行的就是Partial Aggregate为root的子树。每个worker的子树扫描的数据集就是每个partial plan的Remote Plan决定的。
5、Gather节点收集每个worker进程返回的结果,leader进程执行Gather节点以及Gather之上的部分。Gather需要把结果集送给Finalize Aggregare从而用每个worker的partial aggregate 结果形成最终的Aggregate结果。
另外,在并行查询处理场景下,kunlun-server也仍然能够通过读写分离技术,利用shard的备机执行只读查询,这特别适合OLAP场景,可以避免给主节点造成过重的负载。
并行执行的Remote Plan在worker进程中会各自连接到存储节点执行查询任务,为了得到一致的查询结果,这些worker进程在各自的连接中必须使用相同的快照,因此我们在kunlun-storage中增加了连接快照共享能力来配合kunlun-server执行并行的分布式查询计划。这部分内容在下文讲解。
5 KunlunBase计算节点与存储节点之间的并行查询处理
上述计算节点内的并行查询处理,只能执行只读查询子树。KunlunBase实现了计算节点与存储节点之间的并行查询处理,发给多个shard的insert/update/delete语句,是异步发送的,因此多个shard会几乎同时收到自己的insert/update/delete语句并开始执行,这样就实现了并行执行insert/update/delete 语句。
KunlunBase存储节点的支持功能
MySQL社区版的并行查询能力非常有限,KunlunBase并没有使用。我们开发了一系列技术在kunlun-storage中,用以支持KunlunBase查询性能提升,一些技术在KunlunBase的并行查询处理中使用,另一些技术不仅可以在并行查询处理中使用,也可以在串行查询处理中使用。
事务快照共享技术
KunlunBase 全新设计和开发的事务快照共享技术,让存储节点的多个工作线程可以执行计算节点的同一个查询计划中的多个Remote Plan,从而让计算节点和存储节点都可以并行执行一个SELECT 查询。所以此技术是计算节点可以并行执行Remote Plan的基础条件。如果没有此技术,那么多个worker进程看到的数据未必是假如串行执行的话同一个快照所看到的数据,那样就造成了查询结果错误。
计算节点在启动事务时在主进程(backend进程,也是Leader进程)中命令存储节点在其主连接中创建快照,然后在并行worker进程发起的连接中,执行特殊的命令来复制和使用主连接的快照,这样worker进程中可以看到的数据与主连接中看到的数据完全相同,确保查询结果的数据一致性。
Prepared statement
如果客户端连接中执行prepared statement,那么计算节点也会向目标存储节点发送若干个prepared statement。客户端为其prepared statement绑定参数后,计算节点内也会把绑定参数命令发送给存储节点为对应的prepared statement绑定参数。这样可以避免反复执行的查询语句做反复的查询解析。
特别是,在下节的增量式执行场景下可以发挥其性能功效的场景下,使用prepared statement的性能优势会特别明显。
增量式按需执行技术
社区版MySQL的prepared statement 在execute()时会把查询语句全部执行完毕并且把全部查询结果存储在一个临时表中,后续使用fetch()来取结果时就从这个临时表中持续不断地获取结果行。这样的问题在于,并没有达到fetch()的本意 --- 增量式按需执行,避免无谓消耗计算资源;同时,把查询结果全部执行出来写入临时表,还会在查询结果集数据量比较大时带来显著的IO带宽消耗和存储空间的临时消耗。
有很多常见的SQL,诸如带有limit子句、exists/any/some/in/not in等子查询且无法转为semi-join、以及带有子查询结果行数限制条件的查询语句,经常会遇到需要fetch()查询结果中的一部分然后停止执行的情况。社区版MySQL的这种prepared statement的执行方式并不能以较好的性能来执行具有这些特征的查询。
在kunlun-storage中我们设计并实现了一个增量式按需执行查询的技术 --- 客户端(在KunlunBase场景下就是kunlun-server)fetch()多少数据行就执行多少。此时kunlun-storage使用此技术可以达到远优于MySQL的性能,并且完全避免了社区版MySQL的相关性能和资源开销问题。
举一个例子,假设一个分区表t1有1亿行数据,分布在4个shard上的16个表分片中,分区键是id, 执行这样一个语句:
select*from t1 whereage
between 18 and 36 limit 1000;
计算节点使用prepared statement后,它发送给存储节点的查询语句只需要从这16个表分片中总共取出1000行即可,其余的数据行完全没有形成查询结果;而没有kunlun-storage的上述技术的话,那么那些查询语句会被完全执行完毕,因而执行时间显著增加,并且t1表的所有符合过滤条件的行都会返回给计算节点,计算节点收到的行数可能达到了几百万行,但是它只返回前1000行给客户端,然后扔掉其余所有的行。这就造成了大量计算资源(CPU时间片,网络带宽,内存带宽)的浪费。
7 KunlunBase OLAP查询处理的性能及对比
下面我们来试验几个典型的查询在并行和串行执行情况下的性能表现并分析其原因。 基本设置:max_parallel_workers=8; max_parallel_workers_per_gather=4
所以每个查询子树最多4个并行工作的进程,包括leader进程。下面是测试数据准备 --- 定义测试使用的两个数据表并且插入测试数据。
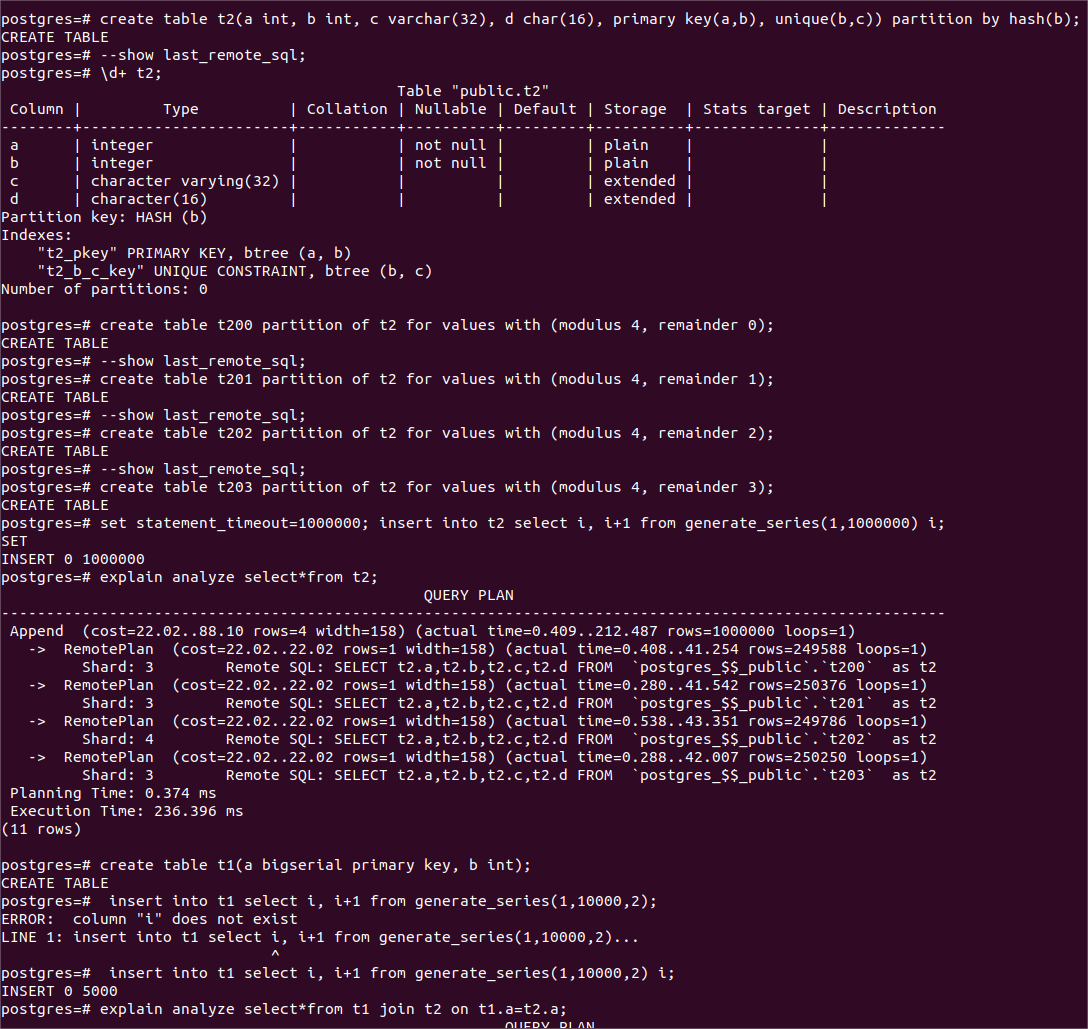 )
)
(数据准备 --- 定义表并且插入大量数据)
1、两表连接,带行过滤(记为查询1,SQL语句及其查询计划和时耗详见下图)
查询结果:并行查询的时耗是串行查询执行的大约1/3(112ms VS 312ms)
这是因为并行执行时,4个表分片中有3个位于同一个shard 3,这个shard在并行执行时的负载过重,因此并行执行的性能并没有提升到串行执行的4倍。另外,build内表hash table是每个工作进程都要做的,这部分时耗并没有因为并行而摊薄。
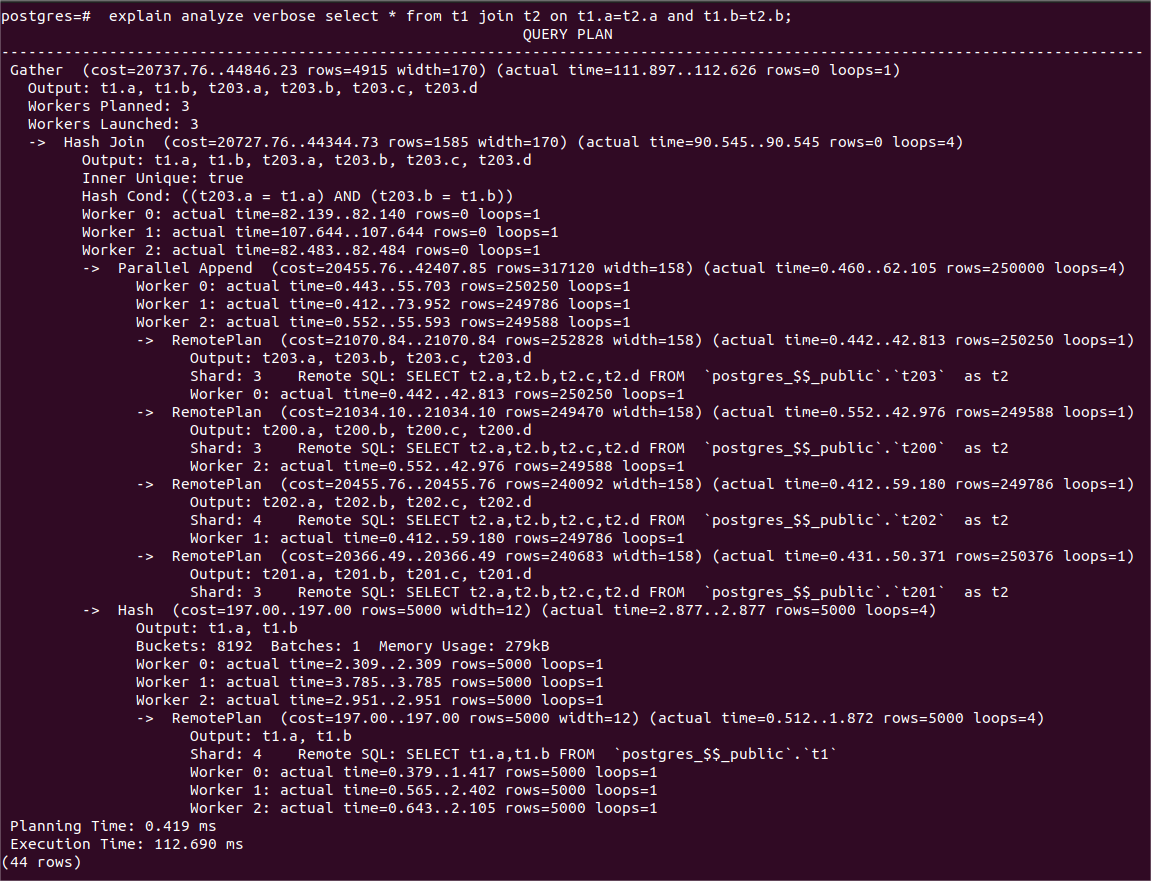
(查询1的并行执行计划和时耗)
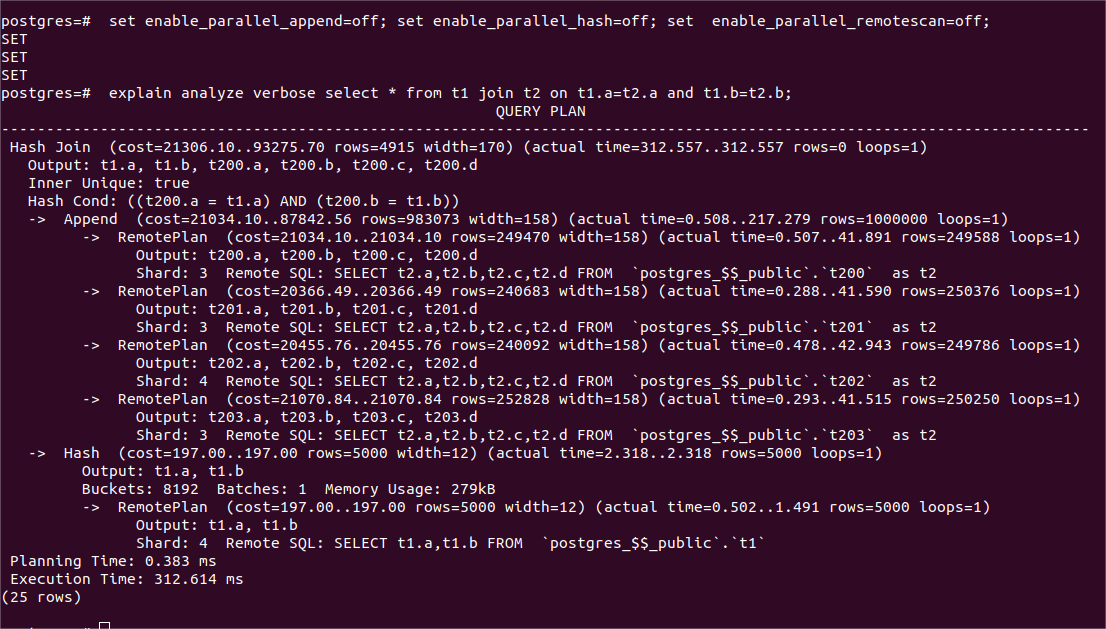
(查询1的串行执行计划和时耗)
2、两表连接后做聚集查询,一个分组(查询2),另一个不分组(查询3)
查询结果如下表,详细的查询语句及其查询计划和时耗见下图。
| 查询 | 并行执行的时耗(ms) | 串行执行的时耗(ms) |
|---|---|---|
| 查询2 | 92 | 250 |
| 查询3 | 72 | 247 |
查询2由于每个worker都要执行基于hash的分组操作,以及对本节点生成的所有的组做排序,导致时耗比查询3大了20毫秒。查询2和查询3都有leader线程需要单独做的Finalize Aggregate操作,以及在每个worker中各自独立执行 hash join 内节点并用其返回的数据行build hash table,因此这部分工作的时耗无法摊薄到4个工作进程,所以时耗比串行时耗的1/4要多一些。
(查询3并行执行计划和时耗)
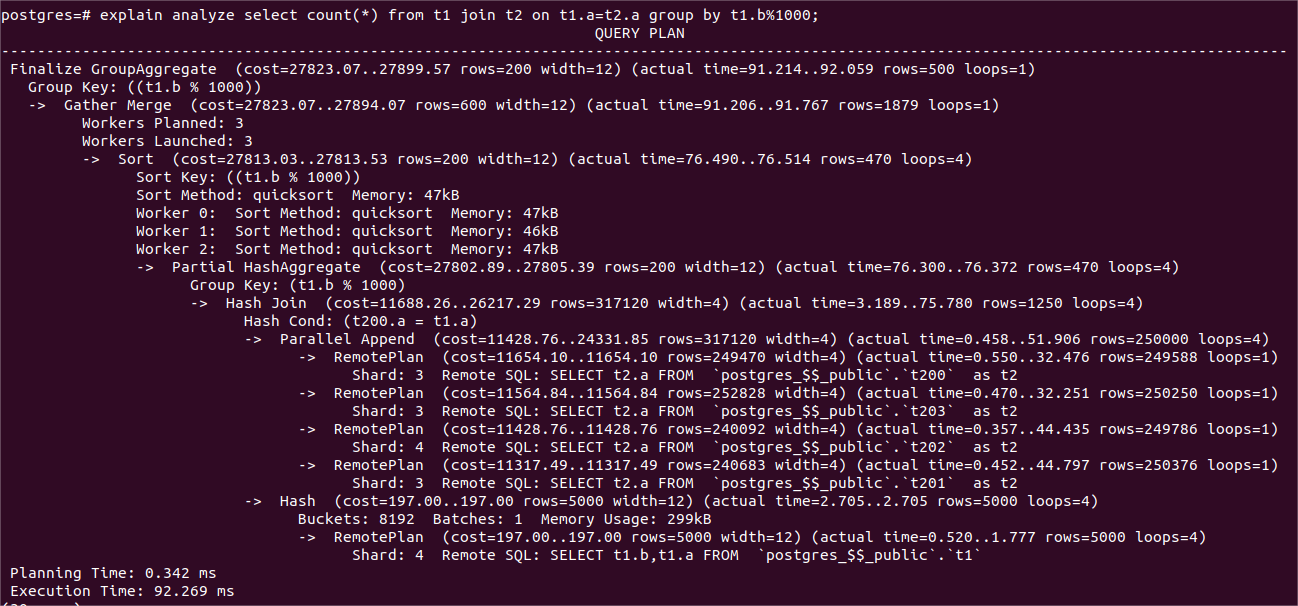
(查询2并行执行计划和时耗)
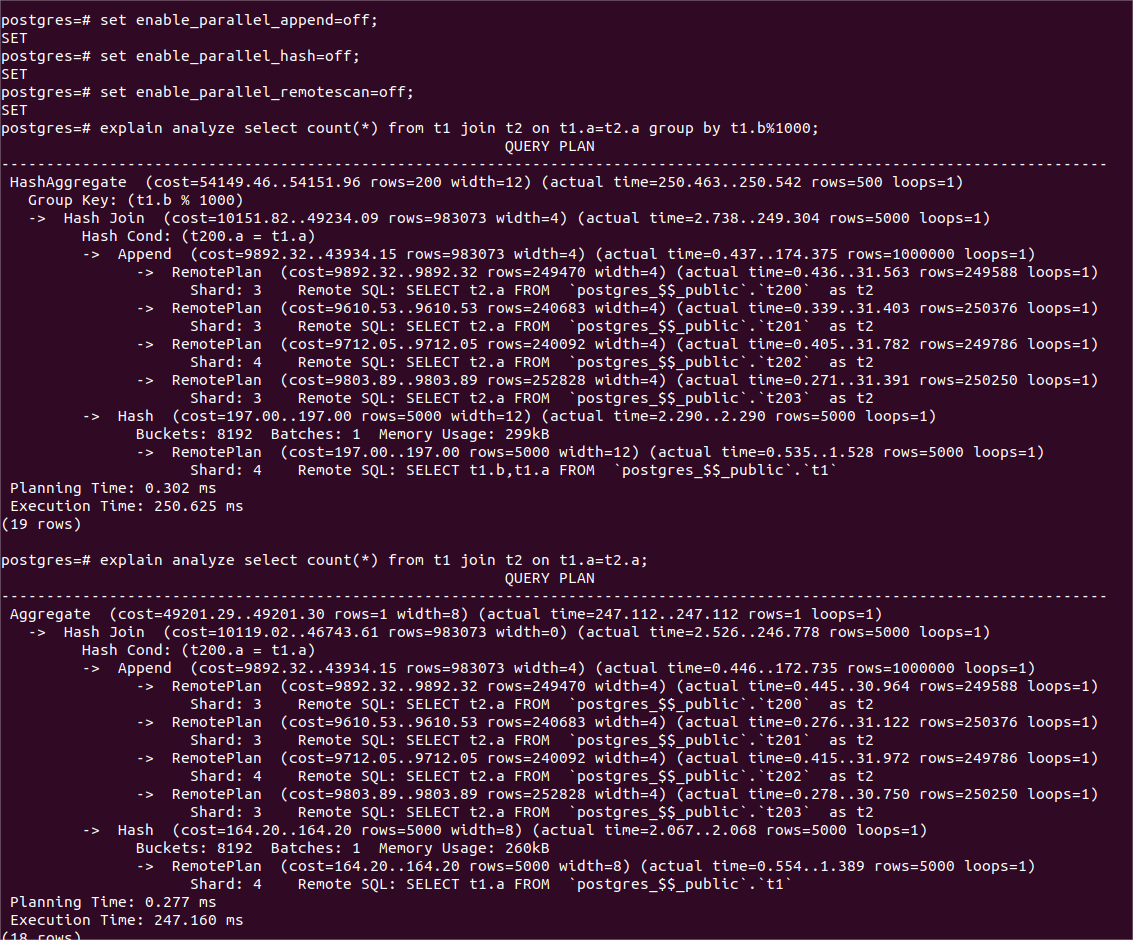
(查询2,、3 串行执行计划和时耗)
总结
KunlunBase的并行查询处理技术,充分利用了PostgreSQL的单机并行查询处理能力,并且把它的能力扩展到分布式查询处理场景;同时我们在kunlun-storage中增强和扩展了社区版MySQL的查询处理能力,为KunlunBase的分布式并行查询处理提供了基础支撑。最终kunlun-storage与kunlun-server有机配合,实现了较好的分布式并行查询处理性能。未来我们还将继续扩展和增强KunlunBase的并行查询处理能力,以便充分发挥分布式数据库集群大量硬件资源的计算能力,实现更好的查询处理性能。