
Klustron特性系列分享:Online DDL和Repartitioning
Klustron特性系列分享:Online DDL和Repartitioning
本文金句
Klustron的Online DDL及Repartitioning特性可以将所有DDL操作在线化,从而实现便捷地变更表结构,而不会影响业务系统的运行。
关键词:Online DDL、Repartitioning
1 Why?
为什么需要这个特性
业务需求和表的数据量变化导致原先创建的表结构可能不再适合,可能出现的场景例如:
- 由于分区不合理导致查询和插入操作变慢
- 表数据变小不要原先那么多分区
- 需要增删列,修改列的数据类型
- 修改主键,增加索引
有了这些问题那我们就势必需要对表结构进行变更,从而使其能重新适应新的业务需求。
但由于通常情况下,我们需要做变更的表是业务系统正在访问,而且极有可能是热点表,所以,这也给我们带来一个挑战:如何在不影响业务运行的情况下完成表变更操作?
那该如何应对这样一个挑战呢?Klustron团队研发的online DDL和在线更改表分区特性,简称为表重分布(repartition)。
这一功能不仅支持单表到分区表,分区表到单表,修改表分区规则以及修改表分区参数。也支持把所有的DDL操作在线化(不需要锁表,不影响业务系统运行)。
2 HOW?
Klustron是如何做到不影响业务运行的情况下完成表变更操作的呢?
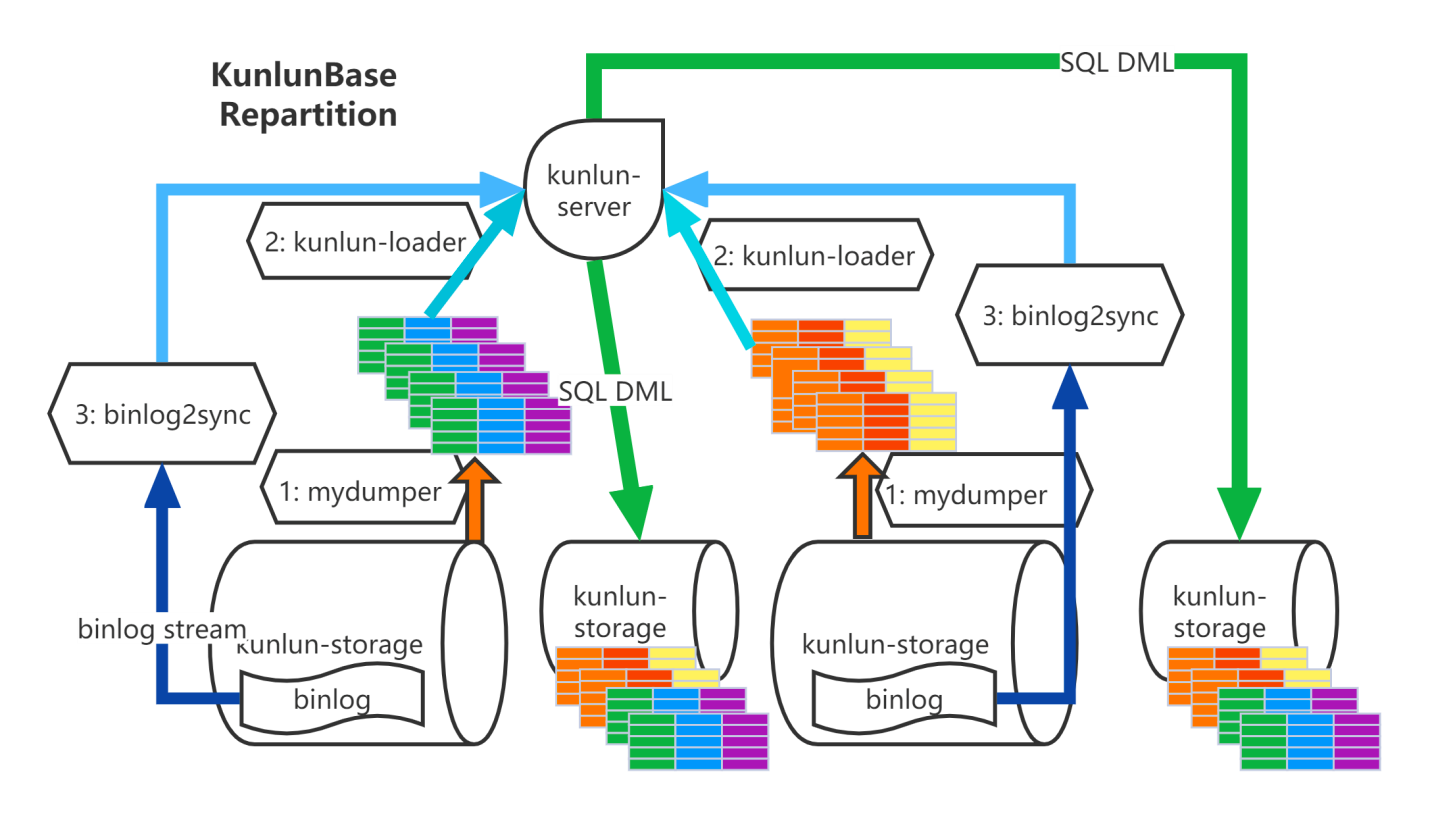
如上图,我们采取的方法是: 把源表数据导出并写入目标表,然后将此期间对源表的更新导入目标表 ,详细步骤:
导出表全量数据:node_mgr 调用mydumper 将源表数据 dump 出来并传输数据文件到计算节点所在服务器;
加载表全量数据:node_mgr调用kunlun_loader工具把源表dump全量数据灌入目标表中;
binlog catch-up:node_mgr根据dump时各个shard上binlog起始位置记录调用binlog2sync工具,binlog2sync 工具从该位置点开始dump binlog事件;
rename 源表和目标表:binlog2sync工具快速将剩余的binlog同步完,然后再将目标表rename成源表名,业务恢复正常使用。
所以,我们可以看出,Klustron 的online ddl整体实现思路和Percona的gh-ost工具的原理有异曲同工之妙。两者都是通过拷贝源表数据,再追binlog的方式来达到不锁表做表结构变更的。
3 More Detail(详细说明)
操作方式:
Klustron的online ddl有两种操作方式:
操作方式一:通过可视化Klustron集群管理工具XPanel
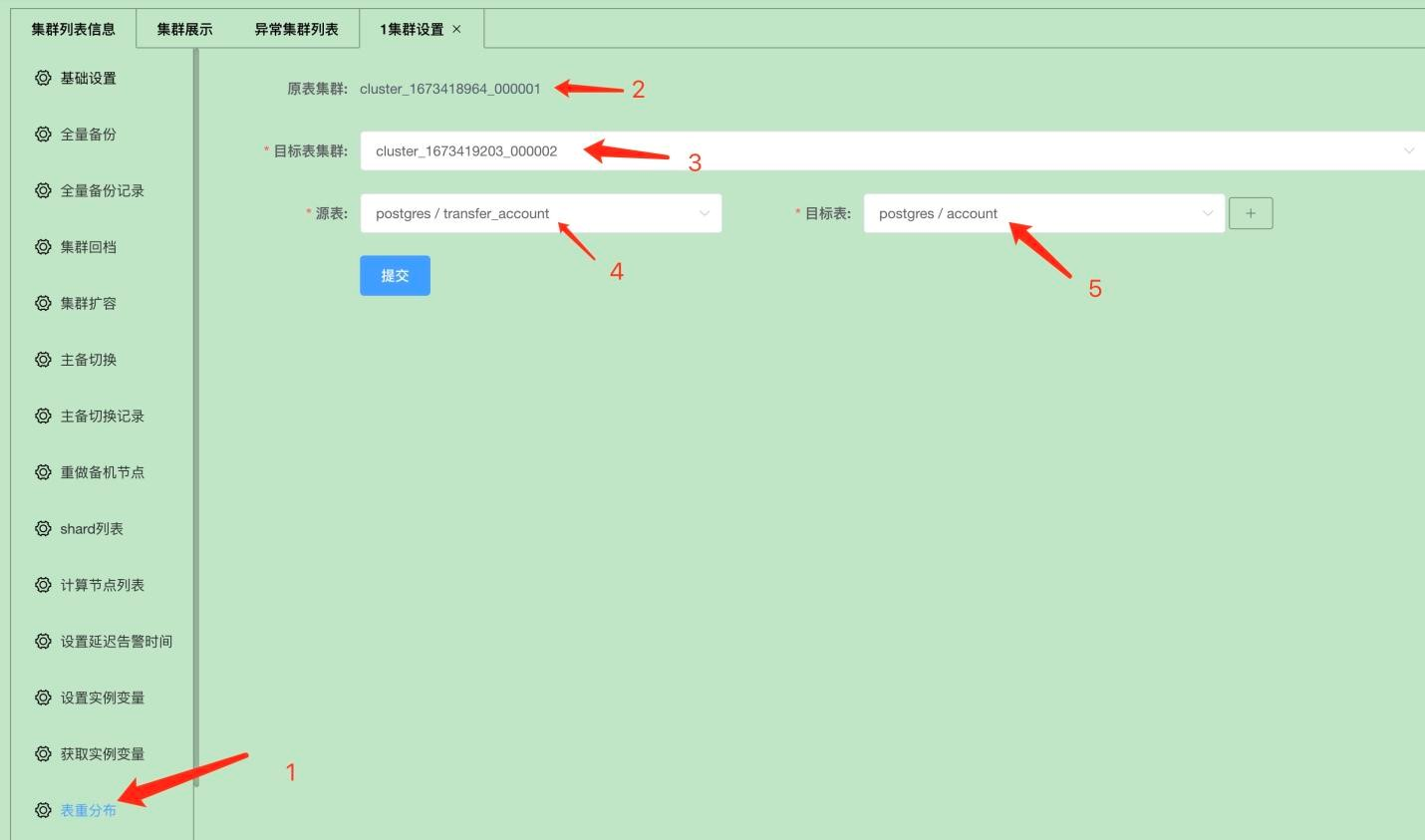

如上图:只需要在XPanel的表重分布界面填入集群,源表,目标表这些相关信息然后提交就可以实现online ddl或表重分布。
操作方式二:通过集群管理cluster_mgr的API
curl -d '
{
"version":"1.0",
"job_id":"",
"job_type":"table_repartition",
"timestamp":"1435749309",
"user_name":"kunlun_test",
"paras":{
"src_cluster_id":"1",
"dst_cluster_id":"3",
"repartition_tables":"postgres_$$_public.transfer_accout=>postgres_$$_public.account"
}
}
' -X POST
http://127.0.0.1:58000/HttpService/Emit
我们通过一个例子来说明表结构变更的情况:
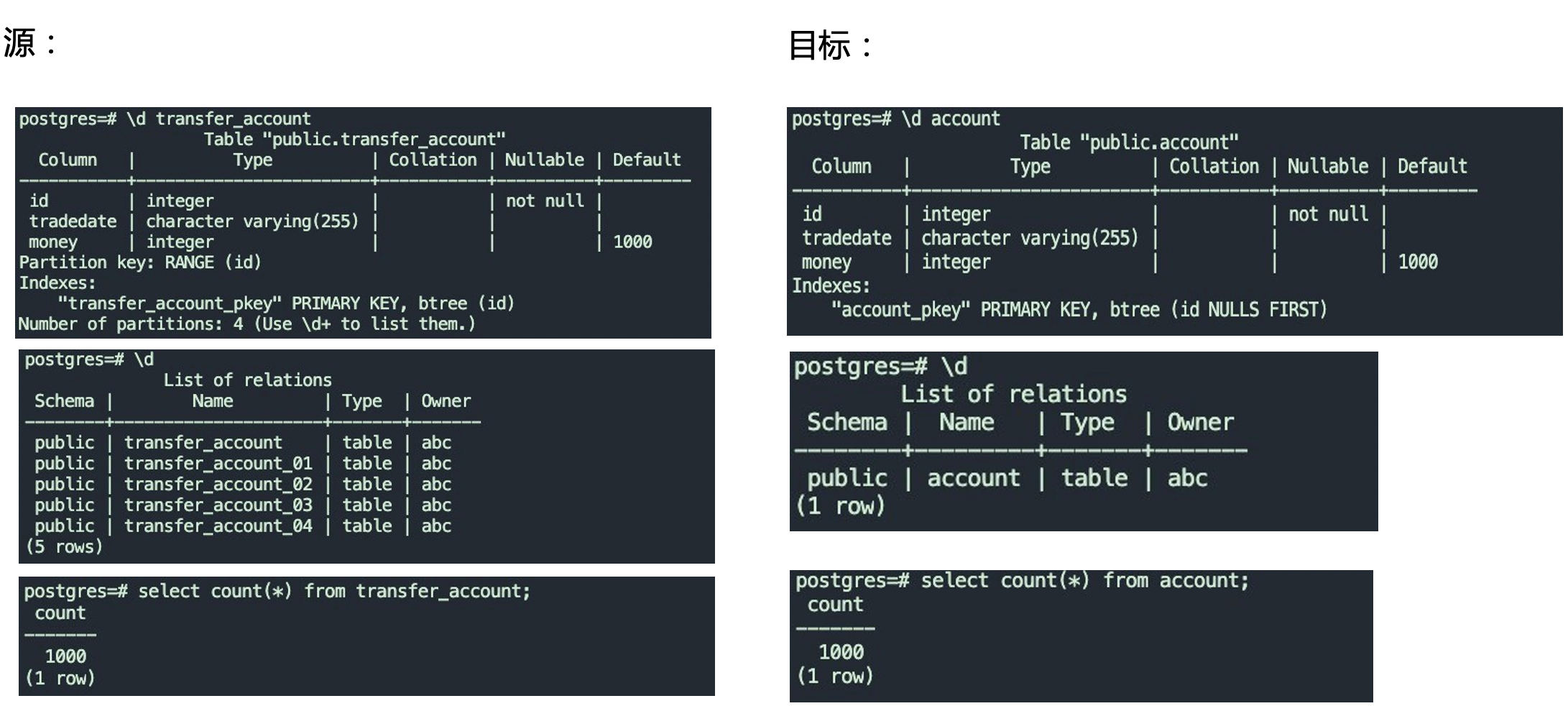
如上图,我们通过online ddl将一个分区表transfer_account变更到普通表account。
对于online ddl有以下一些需要说明的地方:
列顺序:源表所有列名在新表必须都出现,但是这些列的顺序可以不同。新表可以增加更多的列,但是这些列必须具有default值或者允许NULL值。一个online DDL 可以同时做多个操作,如:新增列(可以加到该表的任意位置),调整列顺序以及调整列的约束和default值。
列数据类型:源表和新表同名的列的数据类型必须完全相同或属于同一个大类,并且目标表的数据类型可以更宽,但不可以更窄。例如,二者都是整形,源表列如果是int, 那么目标表对应列 可以是 bigint,但是不可以是 smallint、tinyint;
索引:源表和新表可以有完全不同的索引定义和主键定义。但是源表的数据必须能够满足新表的所有唯一索引和主键的约束,否则数据导入会失败。例如新表就是为了修改主键,或者增加索引或者唯一索引。
分区:源表和新表可以有完全不同的 表分区规则、表分区参数。源表和新表都可以是 单表、镜像表、分区表 中的某一种。例如源表是单表,未分区,新表按照某种规则分区;
表约束:源表和新表可以有不同的表级 check 约束和触发器定义,但是源表的数据必须能够通过新表的 check 约束否则数据导入会失败。
4 Q&A讨论
直播Q1:MySQL也有online DDL的功能,你们的实现与他有哪些异同,你们有哪些优势?
答:不同之处主要有:
1:MySQL原生的online DDL是通过记录对表的所有修改,然后在新表上重做的方式来实现并发DML的处理的,而Klustron是通过binlog来实现的。
2:MySQL的online DDL是需要存储引擎支持的,Klustron的则不需要。
3:MySQL的online DDL并不能处理所有的DDL,有些DDL,比如删除主键,而Klustron可以处理所有的DDL。
所以,Klustron的online DDL较MySQL原生的online DDL可以应用的范围更广,支持的DDL操作更多。
直播Q2:目标表是不是一个中间表?最后还是会rename成源表的名字吗?最后rename表之前是不是会把旧的源表drop 掉?
答:是的,默认是同步完rename成源表。用户也可以设置为不rename。另外,旧的源表并不会立马被删除,而是先rename成带后缀名为_tb_repartition_${job_id}。默认7天后自动删除。用户也可以通过xpanel点击清理,或指定保留几天后自动删除。
END