
Global MVCC机制
Global MVCC机制
引言
Klustron作为一款能全面支持金融,证券等强一致性场景的分布式数据库,数据的全局读一致性是其不可缺少的必要特性。Global MVCC就是为了解决分布式环境下读一致性问题的一种全局一致性机制,它通过设置分布式事务的全局数据版本号的方式来获取当前事务的快照,从而实现全局数据的读一致性。
Klustron的Global MVCC特性通过设置全局数据版本号的方式来创建当前事务的快照,进而实现全局数据的读一致性。
为什么需 要Global MVCC?
我们先来看看分布式事务的读一致性问题,如下图所示
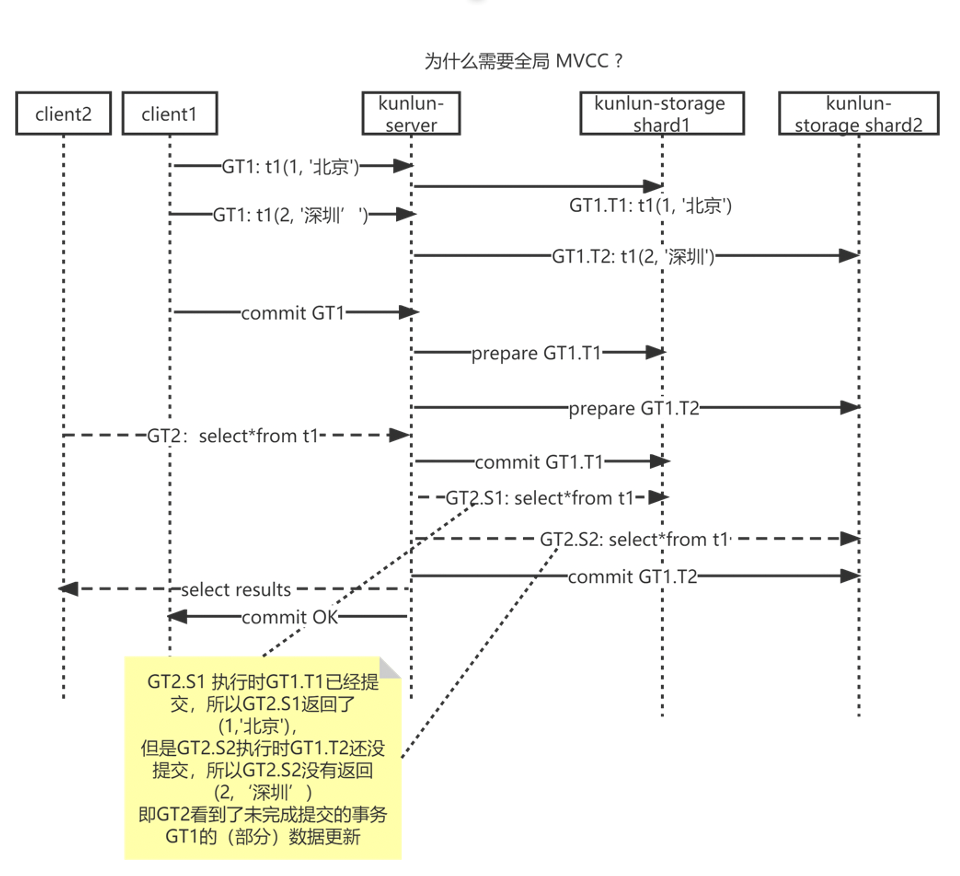
正在提交的分布式事务GT1
- 写入多个 shard (shard1 GT1.t1 & shard2 GT1.t2)
- 分两阶段提交
正在运行的SELECT(GT2)
- 读取到GT1.t1在shard1的更新
- 未读取到GT1.t2在shard2的更新
这就造成了只能读取事务的部分数据的不一致情况。
为了解决这个问题,Klustron实现了Global MVCC,其原理主要是通过建立全局快照来获取当前事务的可见数据。
03 Global MVCC原理及实现
Global MVCC的实现需要在上层的计算节点和元数据集群,以及下层的存储节点都进行相应修改。
首先是上层计算节点部分,如下图所示,首先需要为所有的分布式事务获取和设置全局版本号,然后再通过全局版本号来建立全局快照。
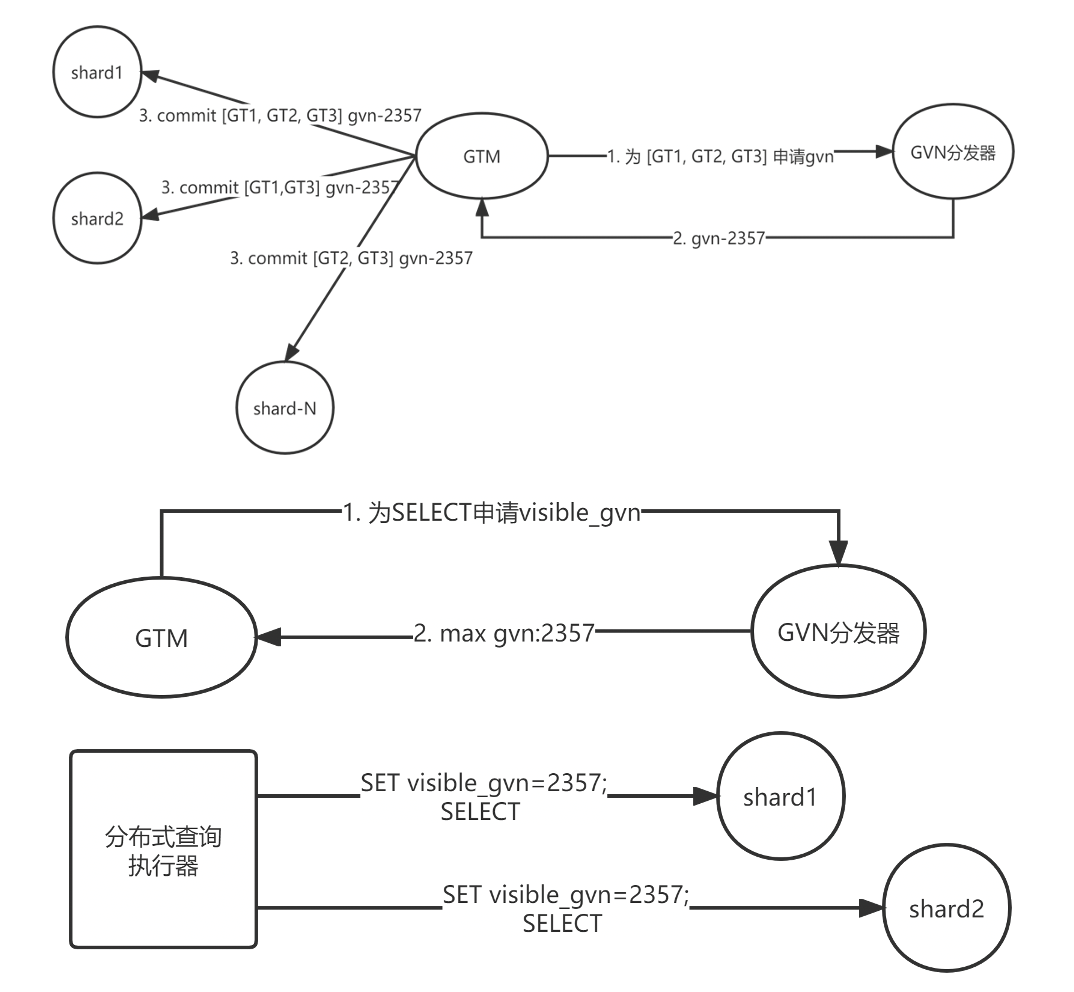
而在下层的存储节点,通过修改MySQL InnoDB存储引擎的相关部分实现对全局快照的支持。如下图所示,我们主要修改了InnoDB的事务可见性判断流程。
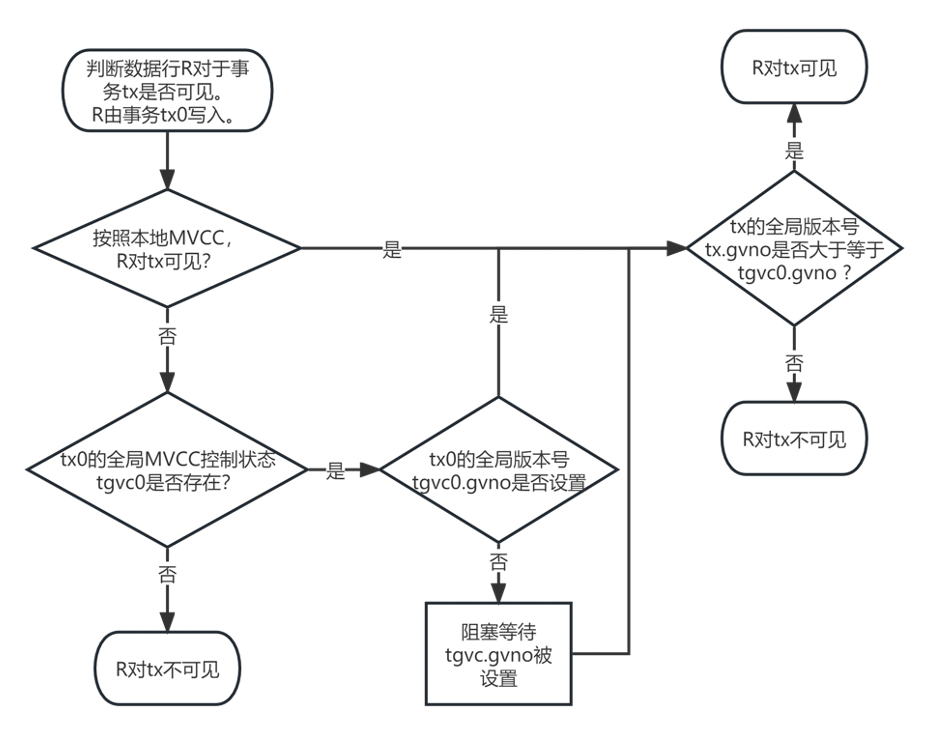
全局可见性判断算法:仅针对XA事务的更新
先做局部可见性判断
局部可见未必全局可见
- 小于local_xmin 的一定可见
局部不可见未必全局不可见
- 获取快照时尚未启动的一定不可见
全局版本号对比
全局不可见怎么办?
- 用undo log生成更老的行版本
上述改动完成后,我们再来对比一下修改前后的流程差异,如下图所示,通过全局版本号和全局事务快照,我们就能避免事务的一致性问题。
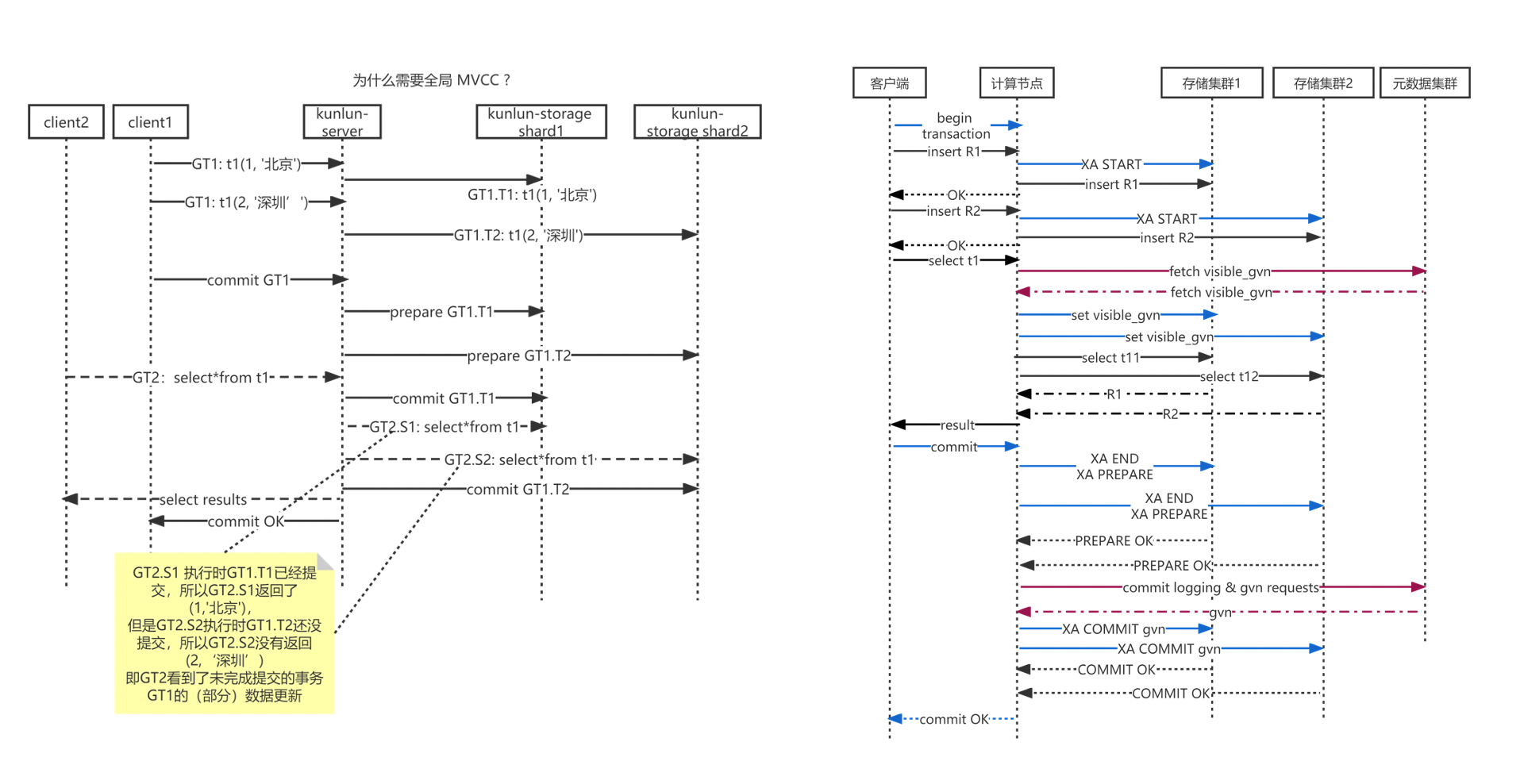
最后,我们来分析一下Global MVCC的性能代价。由于Global MVCC的一些关键流程会带来一定的时间和资源代价,所以,会有一定的性能损失。根据我们的测试和分析,其性能损耗在5% - 10%,属于可以接受的范围。
综合分析如下:
计算节点:
未增加新的已有的时间开销
分配GVNO:随XA COMMIT 语句发放一个整数,存入tgvc_cache中的tgvc
- 忽略不计
获取全局快照:网络收发开销
- 每个SELECT语句(RC)或者每个事务(RR)获取一次
- 从元数据集群sequence取得当前值 select currval(‘global_mvcc_seq’)
分配全局快照:随SELECT语句下发一个整数
- 忽略不计
存储节点:
tgvc管理:忽略不计
Global MVCC 可见性判断逻辑:整数比较
- 少量READ等待设置全局版本号:等待时间通常 < 20ms
覆盖索引查找:页头部max_trx_id:上一次更新本页的事务
以前:readview 可见本页所有行(rv.m_up_limit_id > max_trx_id),则直接返回索引行。
现在:上述成立并且如果max_trx_id > local_xmin, 必须回表以便查找。
- 回表查找的比例略有增加
purge:保留undo log直到global mvcc不再需要由global_xmin 的上升来推动
04 Q&A
**q1:**什么样的场景需要开启Global MVCC?
**a1:**对数据一致性要求比较高的场景需要打开Global MVCC,比如金融,证券等场景,由于开启这一特性会有一定程度的性能损失5% - 10%,所以还是要根据自己的应用场景来判断是否开启。