
HTAP数据库能力系列分享:Online DDL能力探秘
HTAP数据库能力系列分享:Online DDL能力探秘
一、前言
本周开始我们的 【Klustron Tech Talk】 会有一个系列,来探讨 HTAP 数据库相关的问题,主要会探讨 HTAP 数据库的一些关键技术,以及对应的解决方案的选型。
二、HTAP 是"真"的吗?
大家可能在之前的社区讨论中看到过类似的讨论,就是 HTAP 是不是一个真命题。首先我是“站”真的。
从业内这些主流产品的发展趋势也能看出来,原来 TP 能力强的产品在展 AP 能力,反之, AP 型产品也在不断提升自己的事务处理能力,
而且这还真不是这些数据库厂商自己卷出来的需求,而是有着很多真实的应用场景。
像一些商务属性很强的系统,决策很依赖于线上系统的数据分析结果,而这种分析的需求已经从原来的可以等天或者小时的级别,进化到需要分钟级别完成。
另外一个说法是,是不是可以用 AP 加 TP系统组合的方式来实现?
这个架构是能解决挺多问题的,而且我们说,即使有了 HTAP 数据库,这种 AP+TP 的混合架构,依然有它的应用场景,毕竟大型 AP 系统的分析能力,仍然是有很强的不可替代性。
但是 HTAP 数据库要求的一些关键特性,比如事务强一致性的要求,就是说不仅要有分析能力,这个分析查询的结果,还是要满足数据库的 ACID 的要求,混合架构就比较难满足(这个我们在后面的系列展开里,讲 HTAP 数据库的一些关键技术的时候,还会有所体现)。
三、HTAP 数据库需要的哪些必要的能力?
首先作为一个要面向分析能力的产品,要有水平扩展的能力,因为单机跟这个需求背景显然是不符合的。
同时要具备完备的TP属性,也就是分布式事务能力要支持。
分析型查询对系统的性能消耗高,因此读写分离也是一个必备的技术。
有了水平扩展能力后,就能假设资源充足情况下,如何最大化性能。并行查询的能力也就呼之欲出了。
因此,分布式事务、水平扩展、读写分离、并行查询,是一个 HTAP 系统的必备能力,还会有一些加分能力,后续我们在系列展开中再来展开,HTAP 数据库还有一个挑战是 Online DDL 能力,这个问题一开始是在集中式数据库场景下被提出和演进的。
3.1 Online DDL 能力
毕竟在线业务都希望数据库能够 7*24 小时连续工作,而表结构变更可以认为是一定会存在的例行操作,最常见的需求就是加字段、加索引和改字段属性了。
在很久以前,加字段都是锁表的,我们也偶尔能从研发老师傅那里听到这样的经验,一看就是“深受其害”的。比如设计表结构的时候留个 reserverd 字段,如果 reserverd1 不够,就加到 reservedN。
数据库产品和社区的解决方案,也都在迭代和演进。
DDL 之所以有 Online 的需求,是因为 DDL 往往涉及到重做整张表,对于大表来说,这个时间就很长。
再加上 DDL 期间要锁表,无法对表做写入操作,就会长时间影响业务。
最早的 MySQL 版本,连改个字段名都要锁全表,这个阶段持续了挺长时间,期间社区里也出现了一些解决方案。
当然在 MySQL 5.x 以后,专门花很多版本对 DDL 的使用体验做了改进,比如把加字段改进成虽然还是需要重做数据,但是在重做数据的大部分时间里,这个表还能正常的读写,只是在语句执行的最后阶段很短的一段时间有一个锁表操作,这个体验就有很大提升了。
在 HTAP 数据库场景里,还有一类虽然是 DML,但是也是需要对大量数据做操作的场景,就是数据重分布。
比如扩容操作,随着项目数据量增加,可能需要增加服务器来。这就需要将原来的数据,按照新的分布规则,重新分配到集群里。这个期间的操作,对于业务来说,最好能是 Online 的。
刚刚我们说了官方版本的迭代,社区其他一些分支也对 Online DDL 做了改进,比如加字段,包括 MariaDB 在内,有不少版本就支持了秒级加列,也就是连数据都不需要重做,只需要更改元数据信息。
这个能力还是很价值的,毕竟 DBA 们都知道,改动表结构最多的就是加列和加索引。
当然大多数的DDL还是需要重建数据的。
在社区生态里,比较早将 DDL 的 Online 操作实现工具化的是 Percona 的 OSC。
我们先来介绍一个通用的 OSC(Online Schema Change)的流程,假设要将表 A 上的某个 varchar 字段改成 text 类型,需要有一个临时表 B,按照需要的 DDL 的表结构创建好,一开始是一个空表:
- 全量迁移:将表 A 上的所有数据拷贝到表B中;
- 增量迁移:在步骤 1 的过程中,A 上面会有新的变更,这些变更称为增量数据集,在完成全量迁移后,需要将这个阶段对表 A 做的增量更新也应用到表 B 中。
这个阶段 Percona OSC 是利用了 MySQL 的触发器机制,在增量迁移启动前,给表 A 设置触发器,将表 A 上做的更新都记录到临时表中, 之后将临时表上记录的操作都应用到表 B。
有另一类处理增量迁移的思路,是基于解析 binlog 的,比如 gh-ost 这个工具。
触发器方案相比于 binlog 方案,优势是不需要依赖于 row base的binlog,但是由于需要在原表创建触发器,如果业务中本身使用了触发器,就会有冲突。
另外也是 MySQL 的触发器总有些偶发的未解 bug,因此基于触发器的方案被认为过重,gh-ost 这类基于 binlog 的方案被使用得较多。
三、Klustron Online DDL 能力
Klustron 的 Online DDL 方案也是基于解析 binlog 来完成增量迁移。
核心组件包括 mydumper、Kunlun-loader 和 binlog2sync。(如下图)
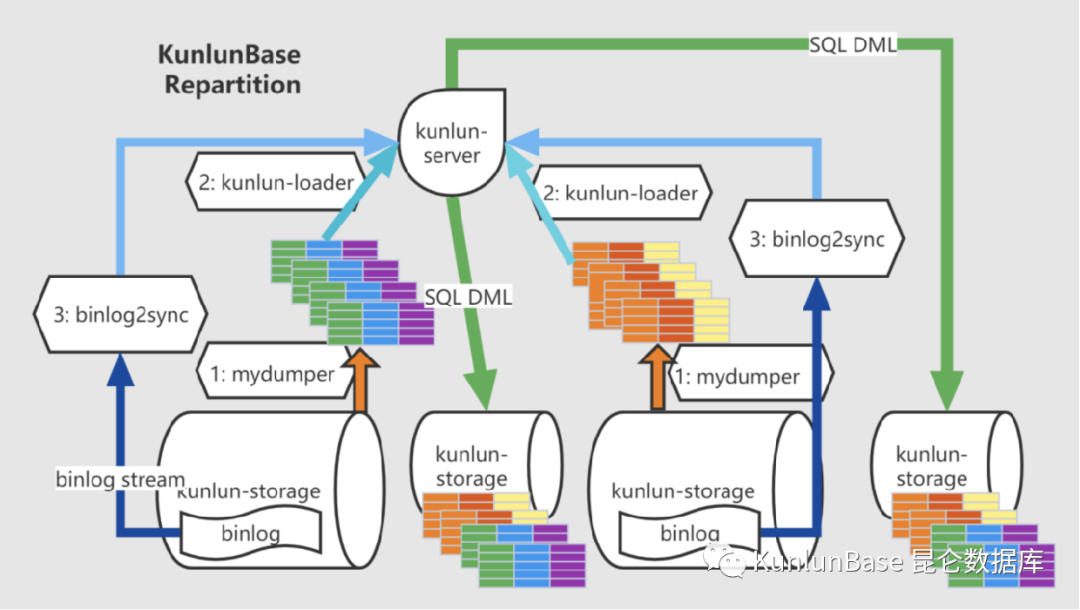
binlog2sync 解析源表的 binlog 后,按照新的表结构构造 SQL 语句,发送给 KunlunSever 的计算节点,再由计算节点分发给对应的存储节点执行。可以看到,对于分片表来说,这个过程默认实现了数据的重分片。也就是说,如果应用升级是需要对数据做重分布,是可以用这个 Online DDL 的功能。
详细文档和案例介绍参看官方文档:http://doc.Klustron.com/repartition.html
四、Q&A 部分
Q1: 这个 Online DDL 的锁表时间是随机的还是可控的?
A:这是个好问题,而且问出这个问题的同学看来是经历过血泪教训。在增量迁移完成后,需要对表做一个短暂的锁操作,来将临时表和源表表名做个交换。
从产品任务执行时间的角度看应该是执行完迁移就尽快锁表;而从对生产环境友好的角度,既然增量迁移过程中表还是 Online 可以正常服务的,那么这个加锁改表名的操作,就希望能够在指定的时间窗口去做,尽量降低对业务的影响。Klustron 的 Online DDL 能够指定切换的时间段。
Q2: 如果源表的写入负载很高,会导致追 binlog 的速度赶不上产生 binlog 的速度吗?
A:这是有可能的,尤其是如果要做 DDL 的表是这个库上更新最频繁的表,那么在增量迁移期间系统就会有两倍的写入压力。
实际上如果工具足够成熟,是应该要控制 Online DDL 这个线程的写入速度,来优先保证业务不受影响。Klustron 的 Online DDL 过程,可以由用户指定增量过程中应用的 binlog 日志量,来实现限速。好在执行期间对源表不会有锁操作,这也是 Online 方案的好处。