
MySQL 8.0的并行 DDL
MySQL 8.0的并行 DDL
本期金句:
MySQL8.0 的并行DDL是该版本中重要的特性之一,它通过多线程并行执行的方式,大幅度优化了部分DDL的执行效率,显著提升了索引创建等DDL操作的性能。
MySQL8.0的并行 DDL特性是该版本的一个重要的新特性,它通过多线程并行执行的方式,大幅度优化了部分DDL的执行效率,大幅提升了create index列等DDL的性能。本次分享将主要介绍并行 DDL的原理及实现方法,以及Klustron后续将在此基础上研发的新特性,期望能让大家在对于这一关键特性有认识的同时,也对Klustron有一个更为深入了解。
01 MySQL DDL简介
首先,我们简单回顾一下MySQL DDL的整个发展历史。
- 在MySQL 5.5之前只支持Copy方式的DDL操作,需要拷贝数据,而且不能并发写正在变更的表;
- MySQL 5.5 开始支持Inplace方式的DDL操作,对于支持inplace的DDL操作,无需拷贝数据,直接在原有的表数据上面进行变更,但仍然不可并发写;
- MySQL 5.6 开始支持Online DDL,实现大部分DDL操作时可并发读写,极大减少了DDL操作对于系统的整体影响;
- MySQL8.0 开始支持并行DDL和instant DDL:并行DDL通过多线程并行的方式加速DDL的执行,而 instant DDL通过只修改数据字典而不修改数据的方式实现诸如增减列之类的DDL操作的瞬时完成。

02 MySQL Instant DDL特性详解
Why?
为什么需要实现Instant DDL,原因主要有以下几点:
- 大表的DDL执行过程太长,尤其是复制场景;(1亿条数据的表创建索引需要几十分钟);
- DDL都是单线程执行,不能充分利用资源,因此存在性能瓶颈;
以下是一个Online DDL的执行过程:(Online DDL流程图:图片来自腾讯云码猿技术专栏)
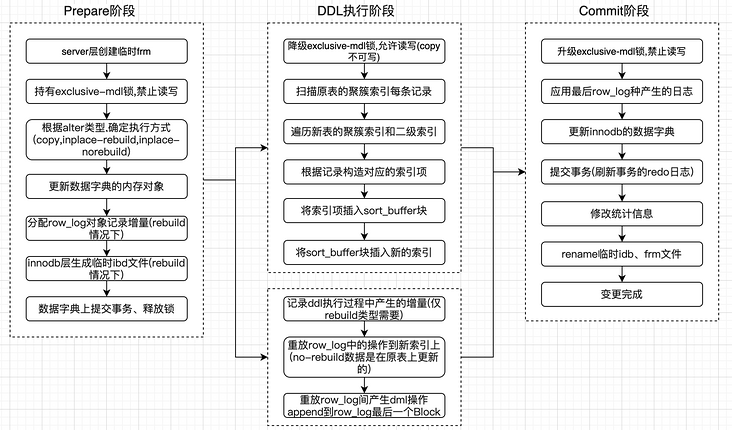
通过上图我们可以看出,在MySQL8.0之前,一个DDL的执行过程需要三个阶段,而其中还涉及到创建新表,将数据导入新表,最后做新旧表切换等比较复杂的过程。这其中的过程都是单线程串行执行,导致DDL的执行效率很低,如果磁盘,内存和CPU资源比较充足的情况下就会导致这些资源的浪费。
并行 DDL的原理:
- 并行 DDL(创建索引)的基本原理主要有以下几点:
- 创建B+树索引的三个阶段,两个阶段采取多线程并行处理;
- 扫描聚簇索引阶段,多线程并行扫描,并生成相应的多个中间文件;
- 二级索引记录排序阶段,多线程并行排序,实现中间文件内记录有序,文件间记录还是无序的。
- 建立二级索引B+树阶段,单线程多路归并排序并生成新从B+树。
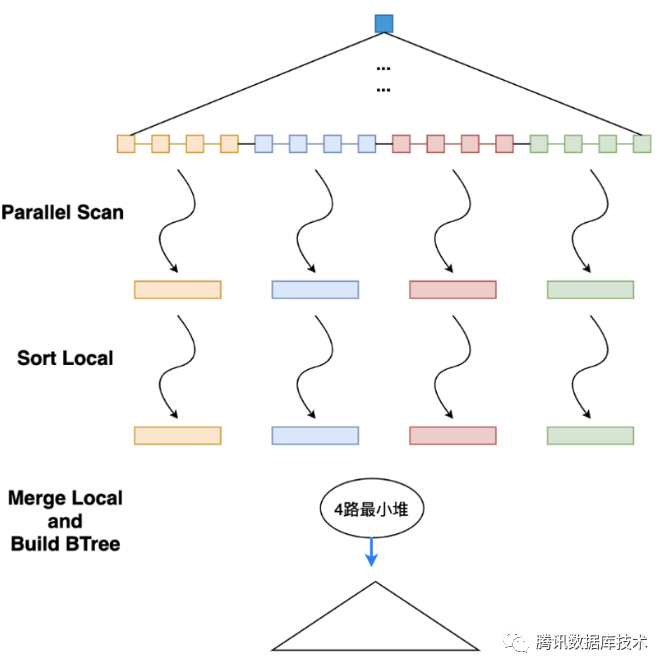
上图(图片来自腾讯数据库技术)是并行DDL的一个示意图,我们可以看出,在创建索引的前两个阶段即:扫描和排序阶段都是多线程并行执行的,而最后一个阶段是单线程的归并排序和生成新的B+树。
并行DDL的流程及效果:
并行DDL的流程如下:
- 设置并行扫描聚簇索引线程innodb_parallel_read_threads个数;
- 设置并行索引记录排序线程innodb_ddl_threads个数;
- 设置DDL缓存innodb__buffer_size;
- 执行DDL语句
下面这张是并行DDL的执行过程:


上图是不同配置的并行DDL的执行效果,我们可以看到例子中创建索引的DDL执行时间从9分多钟下降到2分多钟,缩短了近80%,非常令人兴奋的提升。
并行 DDL的内部实现:
从内部实现的源码来看,MySQL团队主要利用了8.0中已经实现的并行扫描框架,并在此基础上实现了并行排序及后续的构建B+树。具体是:
- 创建DDL命名空间并在其中包含两个主要类Loader和Builder;
- Loader主要负责创建并行线程,控制DDL的主要流程(并行扫描聚簇索引和调用Builder来完成索引的创建);
- Builder的主要任务是实现创建索引的具体工作(索引记录排序,归并和构建B+树)。
- 可以通过创建多个Builder来完成一次聚簇索引后的多个索引的同时创建。
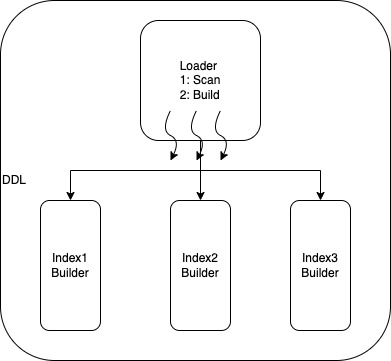
上图是并行DDL内部实现的一个示意图,从图中我们可以看出,Loader可以通过调用不同的Builder来实现不同二级索引的同时创建。
03 Klustron的DDL
首先,简单介绍一下我们泽拓科技的分布式数据产品Klustron的核心架构:
Klustron 的分布式存算分离架构
- 计算层(Klustron-server):多个PostgreSQL实例构成的计算节点负责接受验证应用软件端的连接请求,以及从已经建立的连接中接受SQL查询请求,执行请求,然后返回查询结果;
- 存储层(Klustron-storage): 三个或者更多个MySQL8.0实例构成的存储节点组成一个存储集群(storage shard,简称shard),每个shard 存储着一部分用户表或者表分区;
- 元数据集群存储着Klustron 集群的元数据包括拓扑结构、节点连接信息、DDL日志,commit log,和其他集群管理日志等;
- cluster_mgr 集群负责维护正确的集群和节点状态,实现集群管理、集群逻辑备份和恢复, 集群物理备份和恢复、水平弹性伸缩等功能。

接下来介绍一下Klustron的Online DDL特性。
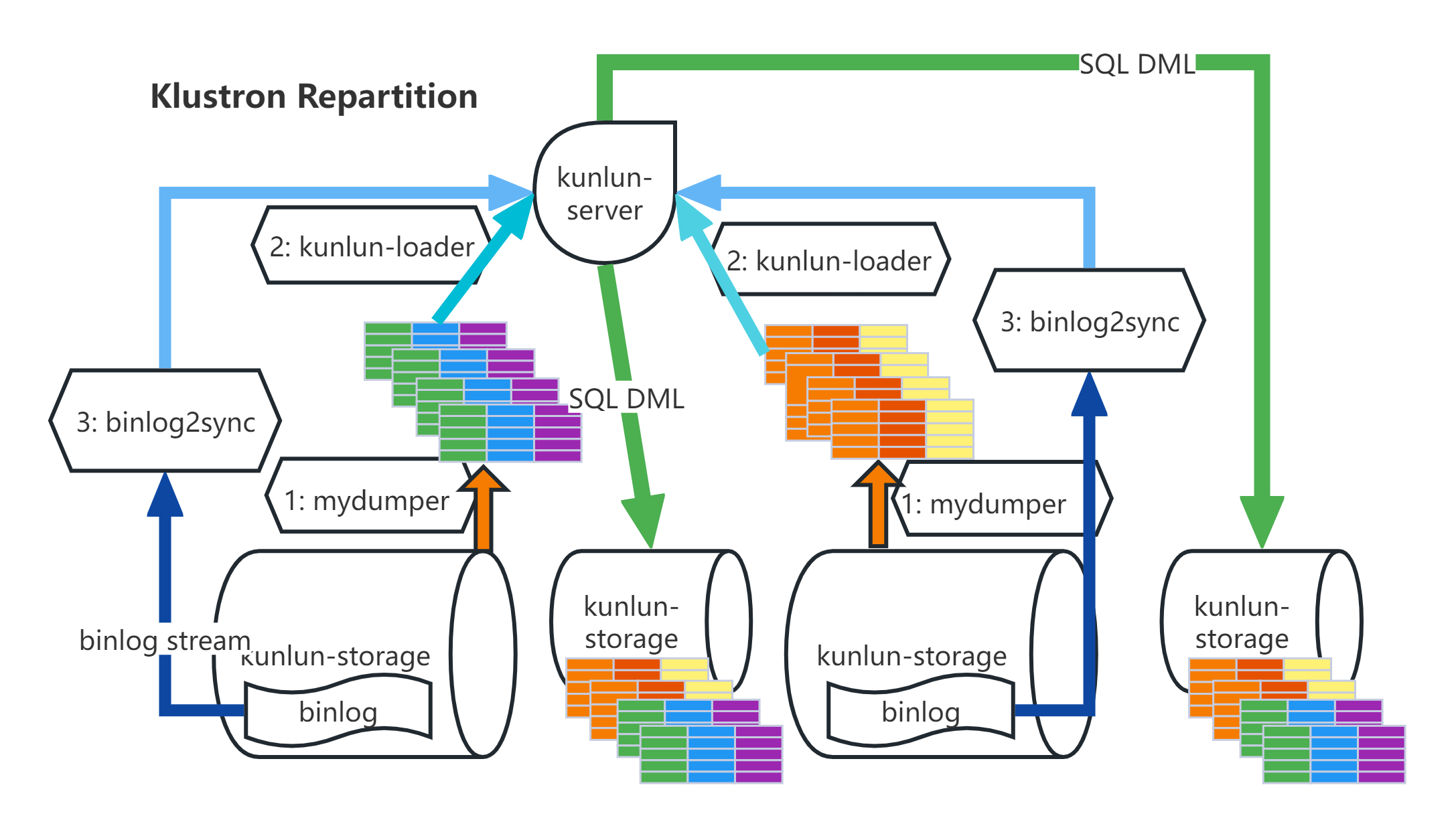
Klustron 的Online DDL(Repartition)
方法: 把源表数据导出并写入目标表,然后将此期间对源表的更新导入目标表 ,详细步骤:
- 导出表全量数据:node_mgr 调用 mydumper 将源表数据 dump 出来并传输数据文件到计算节点所在服务器;
- 加载表全量数据:node_mgr调用kunlun_loader工具把源表dump全量数据灌入目标表中;
- binlog catch-up:node_mgr根据dump时各个shard上binlog起始位置记录调用binlog2sync工具,binlog2sync 工具从该位置点开始dump binlog事件;
- rename 源表和目标表:binlog2sync工具快速将剩余的binlog同步完,然后再将目标表rename成源表名,业务恢复正常使用。
Klustron DDL 的未来:
Klustron不仅实现了Online DDL这一重要的DDL特性,也正在完成并规划其他DDL相关的特性,比如:
- Online DDL的增强和优化(并行化实现性能优化等)
- Transactional DDL(实现DDL的事务性,而不仅仅是原子性)
- Instant DDL的增强与优化(实现更多DDL的Instant方式执行)
- DDL的并行化改造
等等
04 :Q&A
Q1 **:**并行DDL为什么不能做到按线程数线性加速
**A1:**这主要是由于并行DDL并不是全流程并行的。在创建二级索引的时候,扫描聚簇索引和记录排序阶段都是并行的,但最后归并和构建B+树阶段由于中间文件之间记录是乱序的,所以只能单线程执行。要做到线性加速就需要全流程并行,这点我们正在考虑优化,后续的Klustron版本大家就可以看到。
Q2 : 什么地方可以试用Klustron?
A2: 对Klustron感兴趣的小伙伴可以从我们的官网下载试用,根据安装文档部署即可。另外,我们在亚马逊的marketplace和阿里云也提供了Klustron的severless服务,大家感兴趣也可以试用。