
Klustron CDC将数据变更写入kafka
Klustron CDC将数据变更写入kafka
注意:
如无特别说明,文中的版本号可以使用任何已发布版本的版本号代替。所有已发布版本详见: Release_notes。
** 概述 **
Klustron数据库存储节点兼容MySQL binlog dump协议,Klustron从1.2.1开始提供适用于数据同步需求的CDC模块,Klustron CDC已支持多种模式,比如从Klustron集群导出数据(SQL或文件),或支持从开源MySQL导出数据到Klustron集群,目前也默认支持从Klustron将变更数据导出为kafka消息,写出到kafka主题,有其他数据使用需求的下游服务,可从kafka接收消息,完成相关的需求,在本文中,我们将实践CDC数据写出到kafka的配置过程。
01 环境准备
本文所指的测试场景中,涉及使用CDC kafka插件进行Klustron与kafka之间的测试,所以,需要准备一套Klustron的运行环境,理论上,需要至少4台服务器,3台用于Klustron环境,1台用于kafka(单机)服务,受限于资源有限,故使用3台机器搭建整个测试环境,因为使用了不同的服务端口,所以不存在环境冲突。
1.1 Klustron 安装配置
《略》
Klustron 环境说明:
- XPanel: http://192.168.0.152:40180/KunlunXPanel/#/cluster
- 计算节点:192.168.0.152 ,端口: 47001
- 存储节点(shard1):192.168.0.155, 端口:57003 (主)
- Klustron 安装在kl用户下
1.2 Kafka安装配置
《略》
Kafka 环境说明:
- broker0服务IP及端口:192.168.0.153:9092
- topic: CDC kafka会自动创建一个主题,名为:cdc_kafka_<集群名称>
1.3 CDC安装配置
从[http://klustron.cn:14000/dailybuilds/enterprise/kunlun-cdc-1.4.1.tgz 下载文件kunlun-cdc-1.4.1.tgz](http://klustron.cn:14000/dailybuilds/enterprise/kunlun-cdc-1.4.1.tgz 下载文件kunlun-cdc-1.4.1.tgz) 释放到192.168.0.152 / 153/ 155 3台机的kl用户的home目录下,直接用tar -zxvf kunlun-cdc-1.4.1.tgz 解开该文件,在此目录下,会生成名为:/home/kl/kunlun-cdc-1.4.1,及相关的子目录,形式如下:
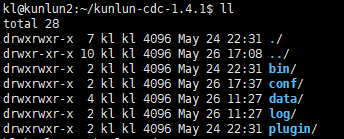
用kl用户进入192.168.0.152 / 192.168.0.153/ 192.168.0.155 的conf目录,编辑参数文件:kunlun_cdc.cnf
cd /home/kl/kunlun-cdc-1.4.1/conf
vi kunlun_cdc.cnf
修改如下参数:
local_ip = 192.168.0.153 #3台机各自的IP
http_port = 18012 #3台机取一致的端口,实际可以不一致,按需定义
ha_group_member = 192.168.0.152:18081,192.168.0.153:18081,192.168.0.155:18081 #3台机组成一个CDC的高可用集群,端口自定义,本例取18081
server_id = 2 #3台机各自定义一个自已的ID号,不唯一即可
保存退出。
进入3台机的CDC bin目录,该目录下有用于启停CDC服务的命令:
start_kunlun_cdc.sh stop_kunlun_cdc.sh
在3台机执行如下指令,启动CDC服务
cd /home/kl/kunlun-cdc-1.4.1/bin
./start_kunlun_cdc.sh
ps -ef |grep cdc
输出如下信息,说明启动CDC服务成功

登陆到XPanel,http:// 192.168.0.152:40180/KunlunXPanel/#/cdc/list,将打开如下页面:
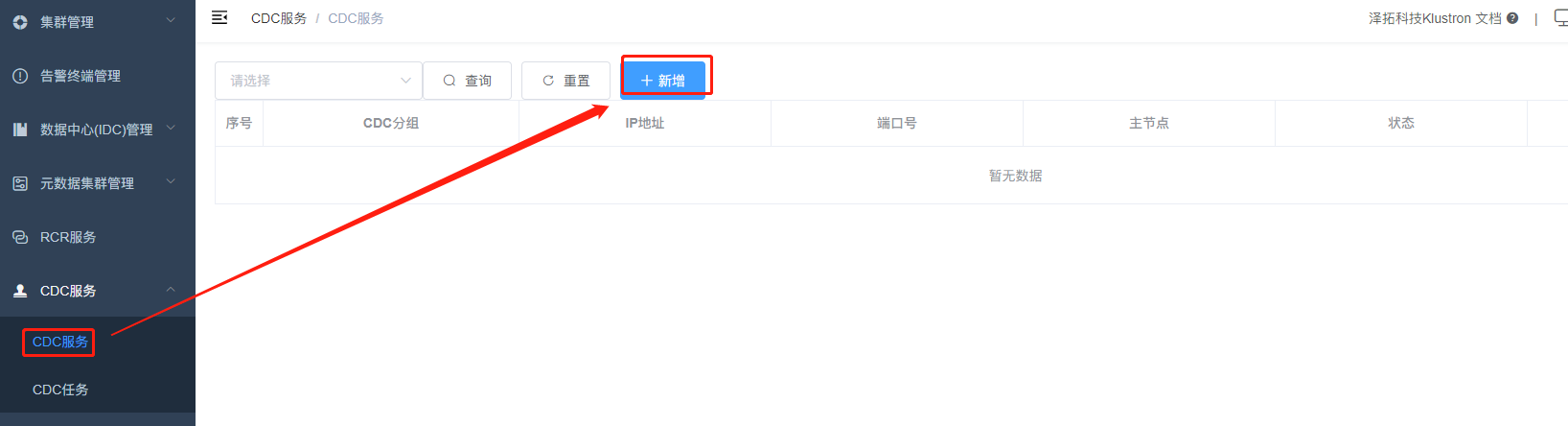
点击“新增”配置“CDC服务”,输入如下相应的参数,
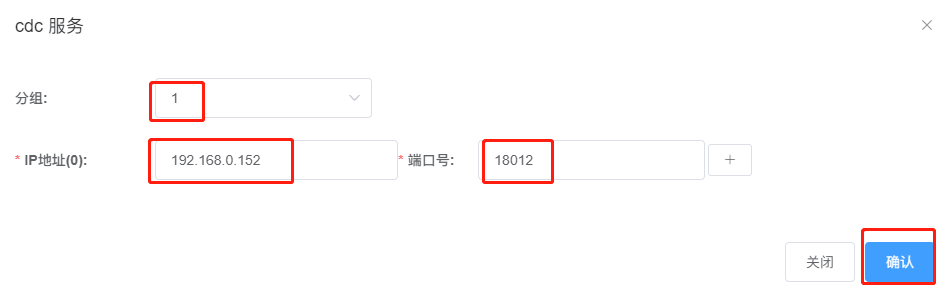
分组号可以自定义,本例中取分组号为1,因为在本例中是配置了3台CDC服务器组成高可用集群,所以,需要点击上图中右侧的“+”号继续完成剩余两个CDC服务的配置信息添加工作,并完成后点击“确认”进行保存。
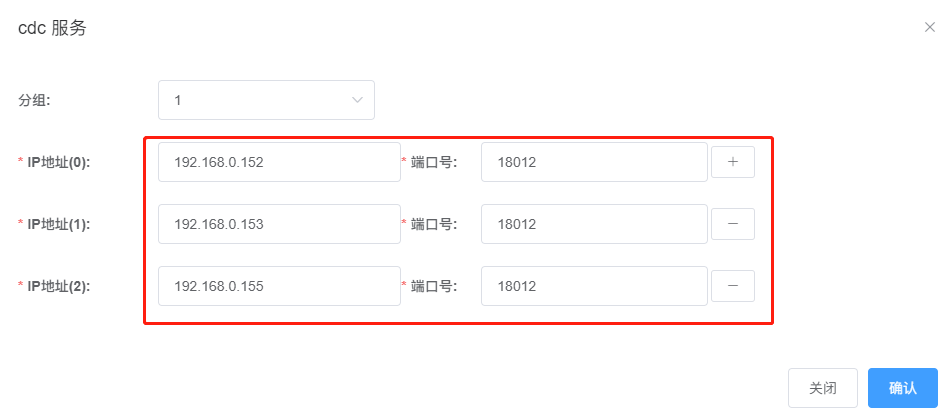
保存后,界面效果如下所示:
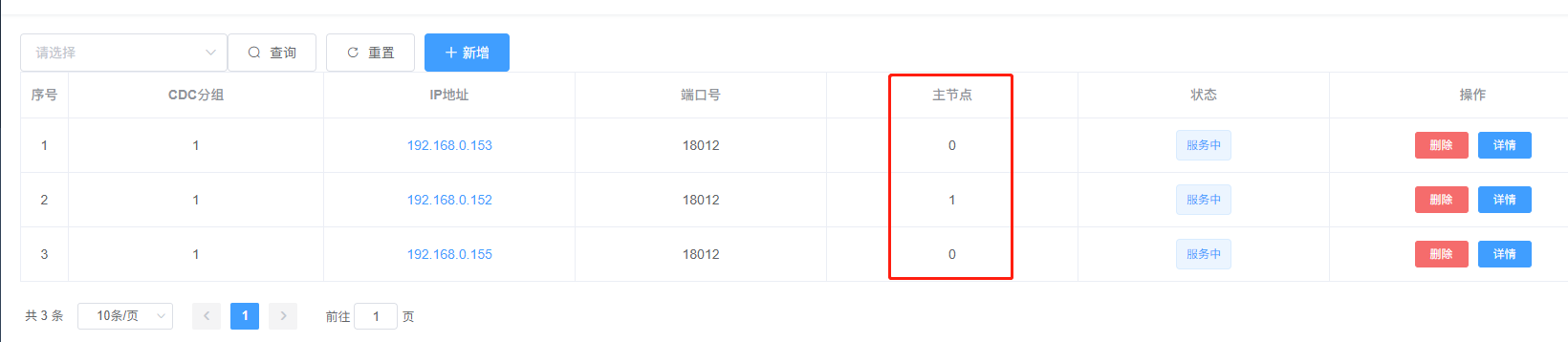
注意一下,其中192.168.0.152在“主节点”字段显示为1,意味着当前承担CDC服务的节点是它,其他两个节点作为备节点,在主节点失效的时候,会选择其中一个升级为主节点,继续服务CDC相关的任务。
02 CDC kafka 插件测试
2.1 从Klustron向kafka写出数据
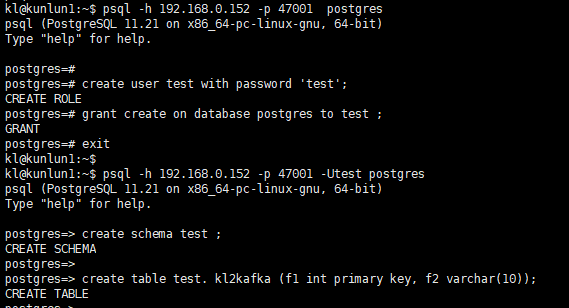
连接Klustron计算节点,建立源库相应用户及表,按如下指令建立相关对象:
kl@kunlun1:~$ psql -h 192.168.0.152 -p 47001 postgres
create user test with password 'test';
grant create on database postgres to test ;
exit
kl@kunlun1:~$ psql -h 192.168.0.152 -p 47001 postgres
create schema test ;
create table test. kl2kafka (f1 int primary key, f2 varchar(10));
打开XPanel:http:// 192.168.0.152:40180/KunlunXPanel/#/cdc/worker ,为Klustron添加CDC任务:
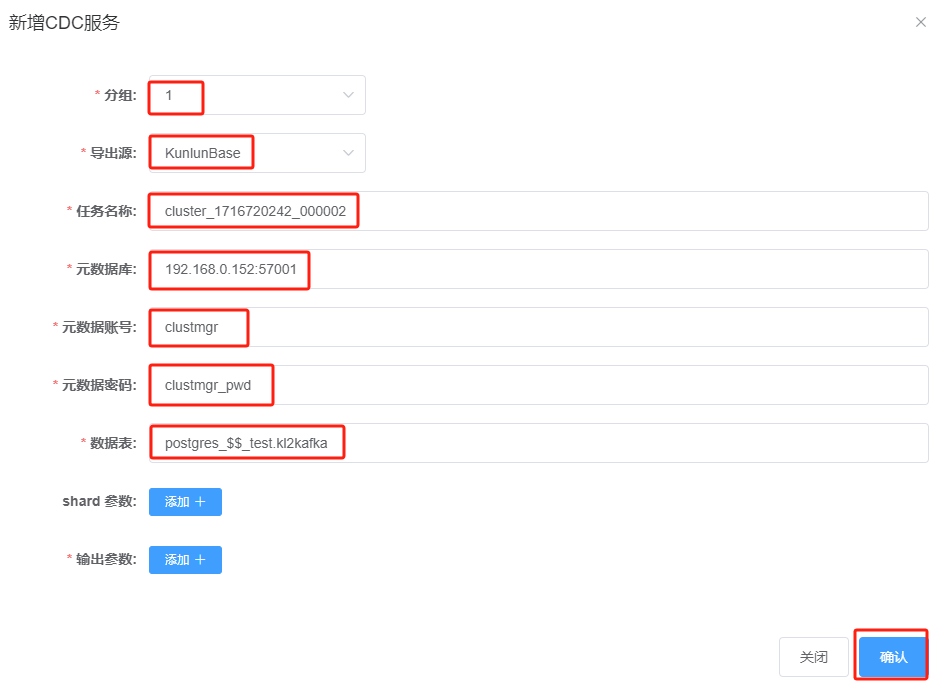
点击“+新增”,输入如下参数:
说明:
- 任务名称:需要查看Klustron集群cluster1的名称,非随意填入;
- 元数据库:Klustron元数据库是一个3节点的MGR,需在XPanel中查看Klustron集群环境中MGR的主节点当前是哪一个,在此处填写主节点信息;
- 数据表:数据表的格式,需要遵循:<database名>$$<schema名>.<表名>的格式,有多个表的话,中间用“,”隔开。
然后,点击 “shard参数:“右侧的“添加+”,弹出如下对话框:

这里,需要连接到存储节点的MySQL分片,获取分片的binlog相关的信息,按如下指令操作:
分片信息:
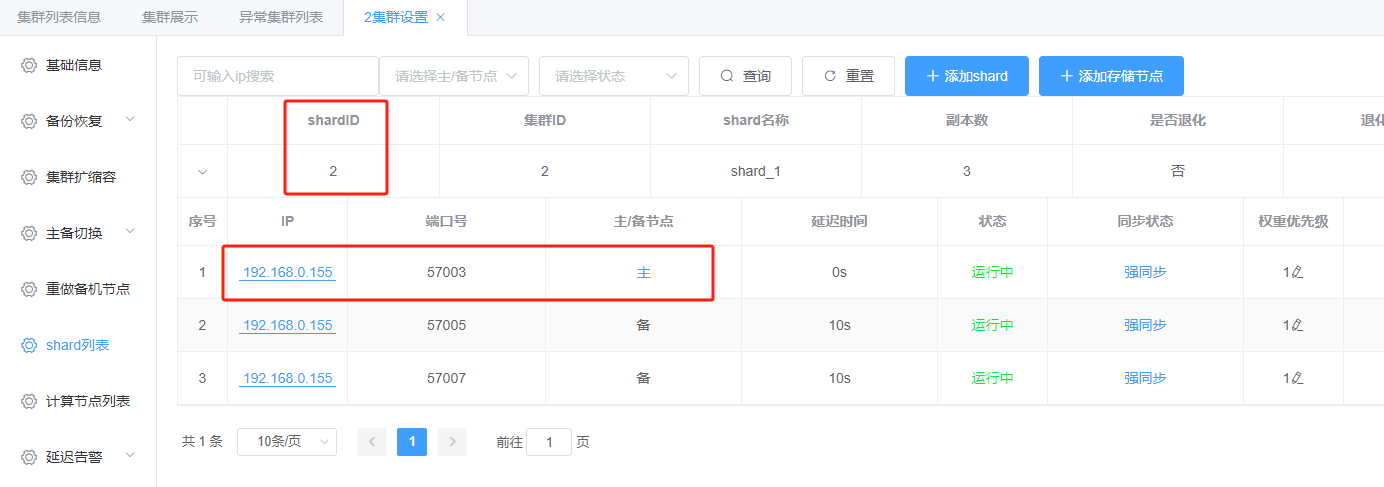
分片1:
kl@kunlun3:~$ mysql -h 192.168.0.155 -P 57003 -upgx -ppgx_pwd
mysql> show master status ;
输出信息如下所示:
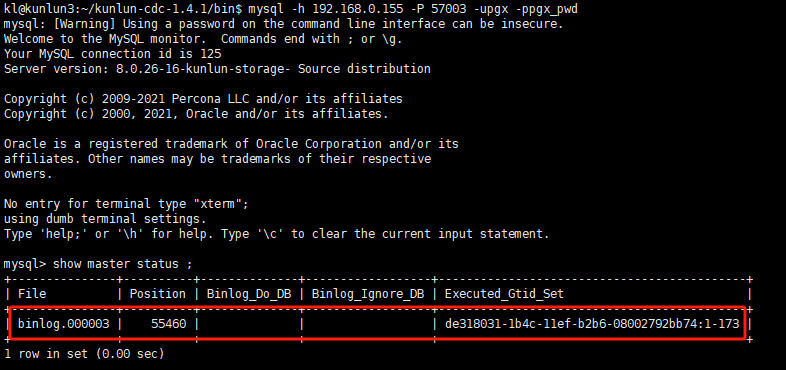
将 上图中file, position, executed_gtid_set 等信息填写至前述shard 配置信息对话框中,如下所示:
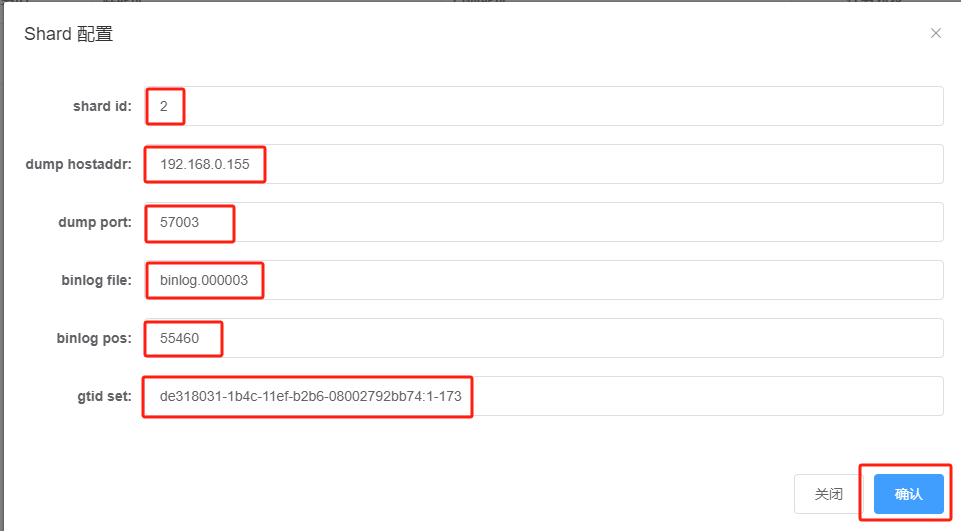
点击“确认”完成分片一的信息配置,显示如下:
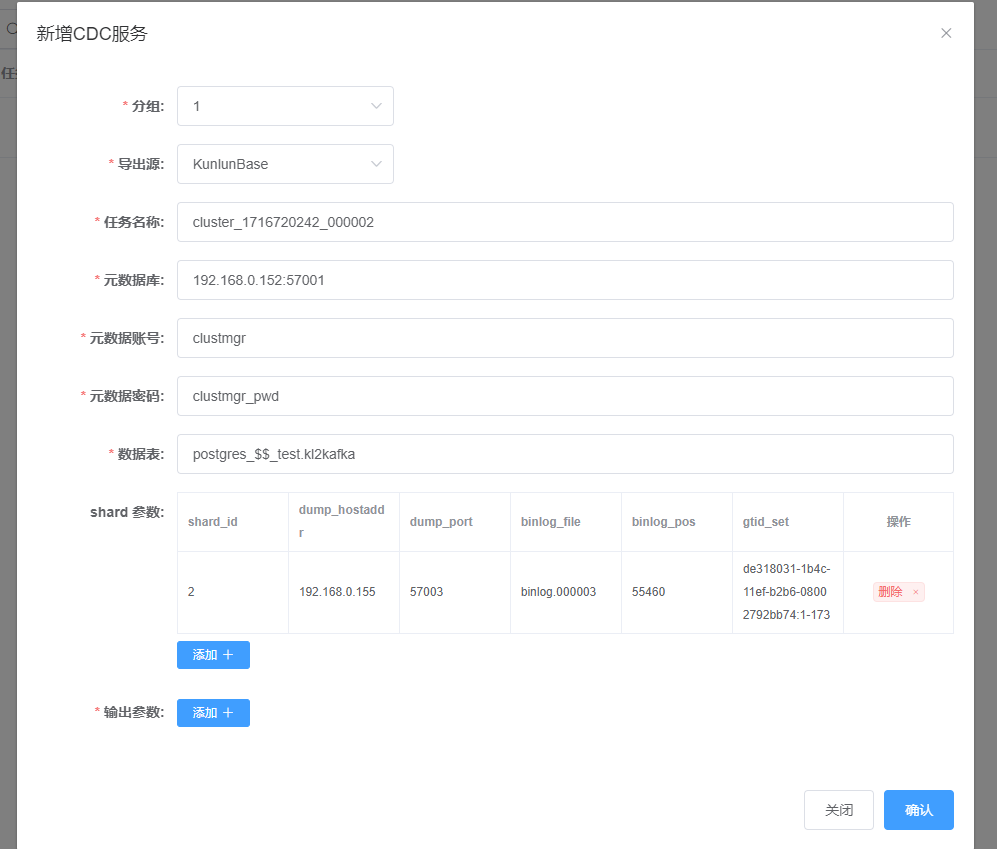
点击“输出参数”旁的“添加+”,如下:
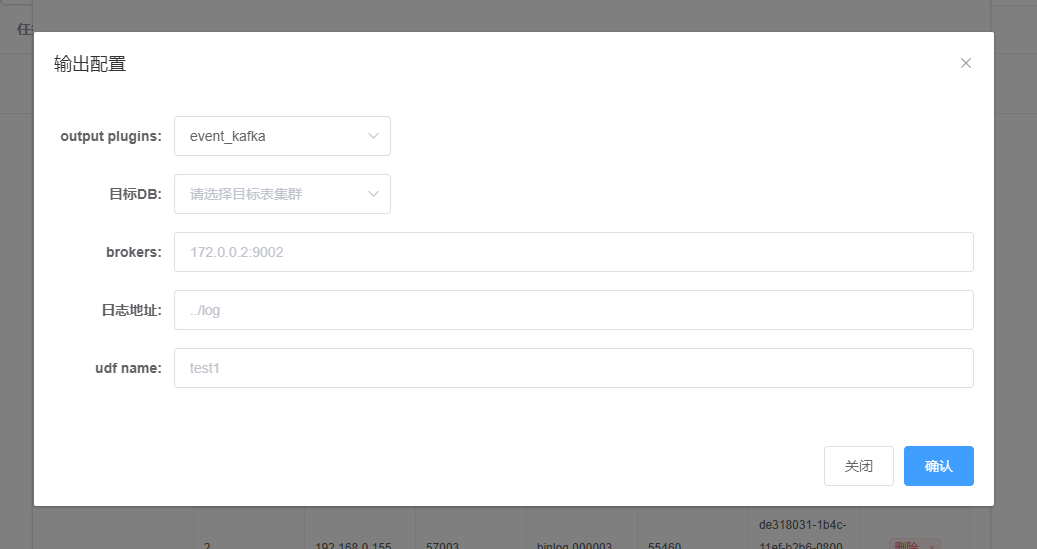
在 output plugins : 这里选 : event_kafka
brokers : 输入 : 192.168.0.153:9092
剩余参数保持默认即可。
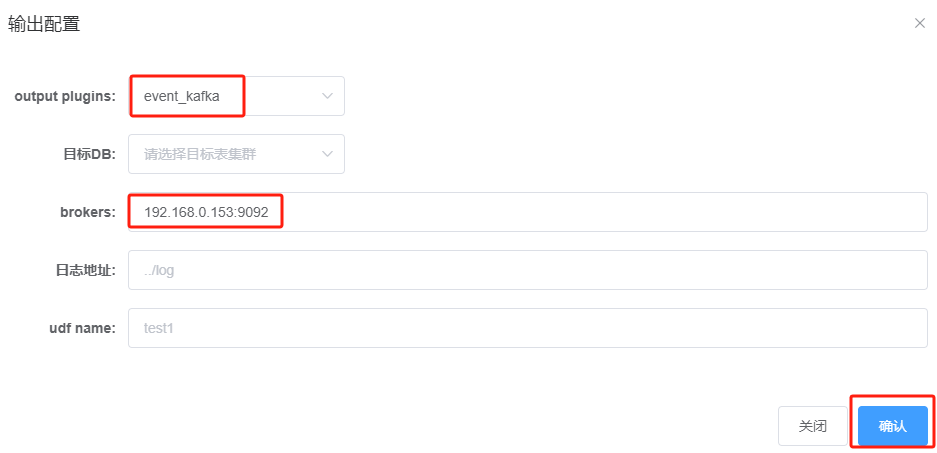
点击“确认”,显示如下:
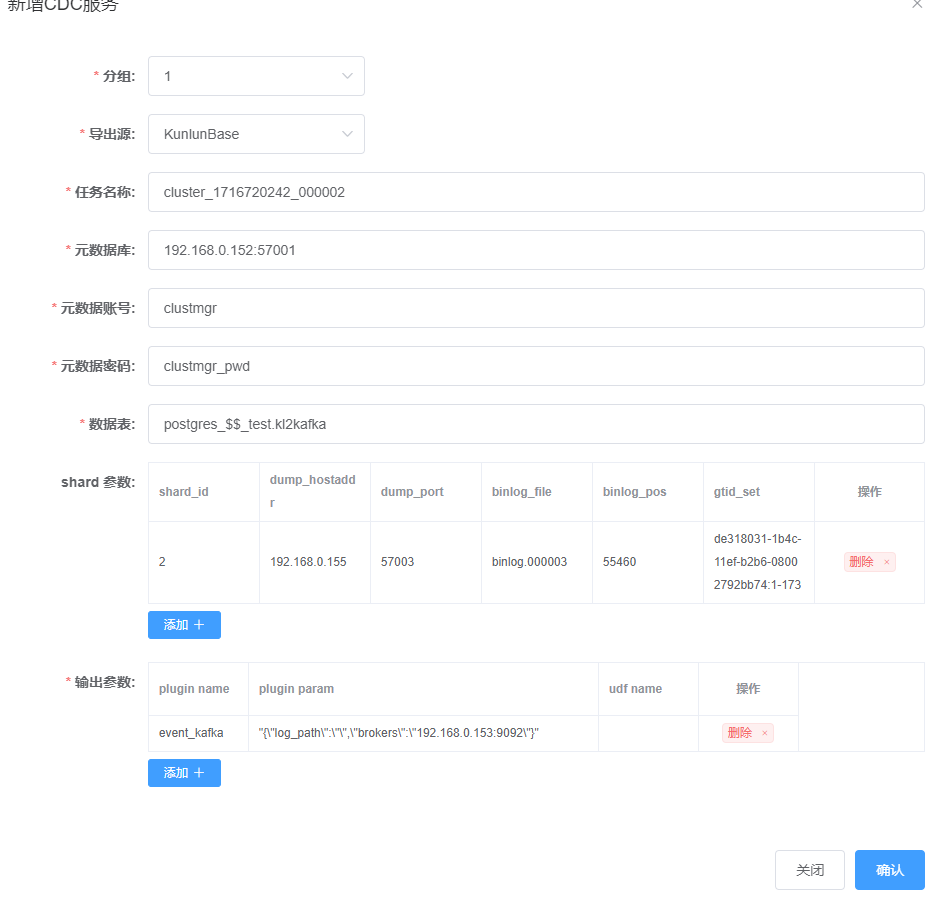
确认无误后,点击“确认”,完成CDC任务上报,显示如下:

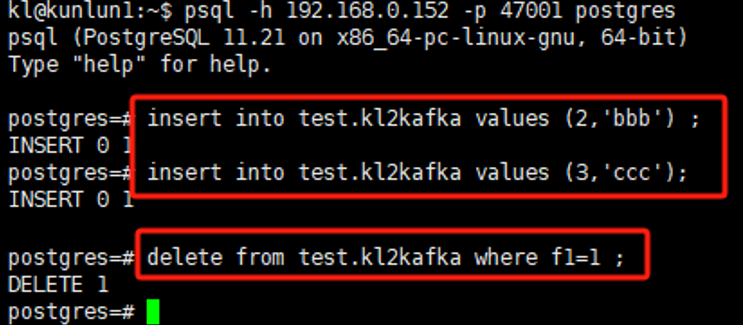
如果同步任务的状态正常,则我们可以接下来进行测试,连接到Klustron集群的计算实例,对kl2kafka表插入记录:
kl@kunlun1:~$ psql -h 192.168.0.152 -p 47001 postgres
postgres=> insert into test.kl2kafka values (2,'bbb');
postgres=> insert into test.kl2kafka values (3,'ccc');
postgres=> delete from test.kl2kafka where f1=1 ;
再连接kafka (192.168.0.153),检查主题上的消息接收情况:
kl@kunlun2:~$ /usr/local/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092
输出topic 列表,其中有一个topic名称为:cdc_kafka_cluster_1716720242_000002 如下所示:

用kafka 自带的消费者客户端连接该topic,读取该topic上的消息,输出消息内容,如下所示:
kl@kunlun2:~$ /usr/local/kafka/bin/kafka-console-consumer.sh --topic cluster_1716720242_000002 --bootstrap-server localhost:9092 --from-beginning

可以看到,kafka的主题上已有之前在Klustron中插入的记录的消息和删除记录的消息,说明CDC kafka插件分发消息到kafka目标topic的任务执行正常。