
Introduction to KlustronDB Distributed Task Execution Framework
Introduction to KlustronDB Distributed Task Execution Framework
1. Background and Objectives
KlustronDB, as a distributed database product, natively has the requirement for multiple physical devices to work collaboratively. Many cluster-level operations, such as scaling, rollback, adding shards, and data shuffling, need to be performed across different physical devices.
In order to enable this type of distributed collaborative task to be completed efficiently and reliably, the KlustronDB development team, based on the cluster components Cluster_mgr and Node_mgr, has implemented an efficient distributed task execution framework. Its core requirements include, but are not limited to, cluster state maintenance, distributed transaction management, dispatching and execution of multi-node collaborative tasks, and querying and displaying cluster states. The implementation goal is to provide a good abstraction for this type of multi-machine task, achieving high concurrency, observable task states, and controllable task execution.
2. Interactive Model
ClusterManager is the cluster control component of KUNLUN DBMS, responsible for the aforementioned multi-device collaborative tasks. It is an independent functional module that works in coordination with the metashard and NodeManager, running statelessly on any physical device within the cluster.
Below, the process of a cluster expansion task is used to describe the front-end and back-end interaction model of the distributed task execution framework.
_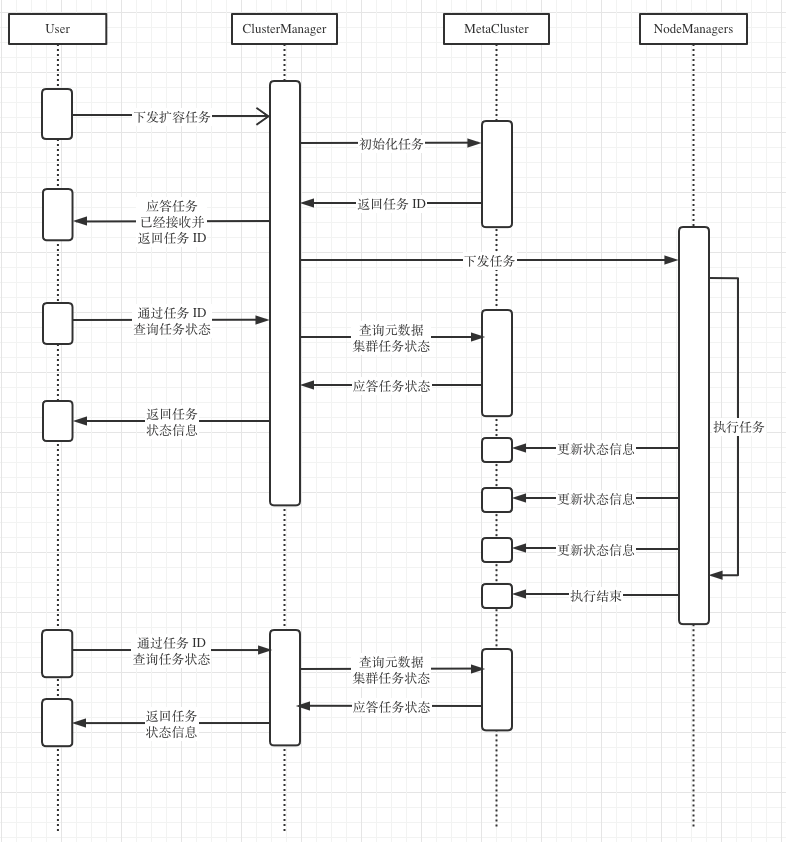
- After the user sends a scaling task to ClusterManager through the Web console, they will immediately receive a response, including the ID of the currently sent task and whether the task has been accepted.
- The frontend, through polling, sends task status query requests containing task IDs to the ClusterManager. The ClusterManager retrieves task information by querying the metashard (MetaCluster) and responds to the frontend.
- After NodeManager receives a task, it starts executing the related operations and updates the task status to the metashard during the process.
- The front desk identifies success or failure flags in the results of the task status polling, thereby ending the polling and marking the current task as complete.
ClusterManager provides HTTP services externally through a RESTful style API, currently mainly focusing on issuing cluster management tasks (creating and deleting clusters, creating and deleting nodes, scaling, rollback) and related status query functions.
ClusterManager provides HTTP services externally, logically offering only two service functions: task distribution and task status query. Accordingly, it only handles two HTTP request methods: GET and POST.
GET Specify a unique task ID in the HTTP body using JSON text to obtain the task status. It does not perform any other functions. The response includes task status information.
POST In the HTTP body, task-related types and parameters are specified through JSON text to issue tasks. The response includes whether the task was accepted and the global task ID assigned after acceptance. The frontend can use this ID to poll for the task execution status.
All HTTP responses from the ClusterManager are sent immediately, without any blocking. As for the URL part, the ClusterManager only provides a unique identifier externally: http://ip:port/HttpService/Emit, and other resource identifiers are not processed.
3. Task Assignment and Execution Model
ClusterManager task processing is a purely asynchronous framework oriented towards both front-end and back-end. The purpose of this implementation is to ensure that ClusterManager can continuously provide cluster management services externally without the server being blocked due to the long execution of sub-tasks.
The asynchronous features of ClusterManager are mainly reflected in the following aspects:
- The reception of tasks and task initialization are asynchronous. For POST tasks sent by the frontend, the ClusterManager will only perform simple legality checks synchronously (the logic is simple and will not cause long-term blocking) and then immediately respond to the frontend via HTTP. The internal initialization and dispatch of specific tasks will be handled asynchronously in the background.
- The dispatch and execution of background tasks are handled asynchronously through coroutines
Although individual RPC calls with NodeManager are still synchronous and blocking, the overall processing flow is asynchronous, so the entire HTTP service will not be blocked. As shown in the figure below: 
4. Abstract Interface of Distributed Tasks
4.1 REQUEST Object - Corresponding Business Request Processing Procedure
Each POST query will generate a REQUEST entity in the ClusterManager. This entity is responsible for executing subtasks, persisting information, and other functions, defined as follows:
class ClusterRequest : public kunlun::ErrorCup {
public:
...
void SetUp();
// Derived class should implament it
// Invoked by SetUp()
virtual void SetUpImpl() = 0;
virtual void DealRequest() = 0;
// the response will be sent in TearDown()
void TearDown();
// Derived class should implament it
// Invoked by TearDown()
virtual void TearDownImpl() = 0;
// getter & setter
void set_status(RequestStatus);
RequestStatus get_status();
std::string get_request_unique_id();
void set_request_unique_id(std::string &);
RequestBody get_request_body();
ClusterRequestTypes get_request_type();
bool ParseBodyToJson(const std::string &);
// forbid copy
ClusterRequest(const ClusterRequest &) = delete;
ClusterRequest &operator=(const ClusterRequest &) = delete;
private:
...
};
For a Request, the process of handling this request is fixed and includes three steps: SetUp() / DealRequest() / TearDown(). Each step corresponds to the task preparation phase, task execution, and task completion phase. 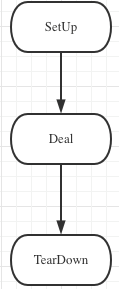
Different tasks require instantiating this interface class and filling in the SetUpImpl/DealRequest/TearDownImpl methods. These custom logics will be called during the task execution process.
SetUp SetUp needs to be lightweight, and here it is executed in a serial single-threaded manner. The purpose of using serial synchronous execution for the SetUp phase is to facilitate handling tasks that require exclusivity. For example, if a task can only exist and execute globally in a unique manner, the task logic can be moved up to the SetUp phase.
Deal This is where the main task logic is executed (of course, if necessary, this logic can be moved up to SetUp). It will be carried out in a coroutine here, but it will not wait asynchronously for the RPC response and will still use a synchronous approach. Because the synchronous wait here does not affect the main logic, a synchronous approach is sufficient to simplify programming complexity. If there is a need for multiple NodeManagers to execute commands asynchronously at the same time, this can be encapsulated in REMOTETASK, and the upper-level call here will still be a synchronous interface.
TearDown This is where the global cleanup work is done, such as notifying compute nodes, updating the metashard, etc. This will also be carried out in a coroutine.
4.2 REMOTETASK Object - Remote Task
Each REQUEST may involve multiple remote tasks, for example, scaling up includes DUMPing data, transferring data, LOADING data, establishing synchronization, verifying results, and disconnecting synchronization.
Each of these processes needs to be executed on different machines, one after another, and each corresponds to an RPC procedure. The REMOTETASK object corresponds one-to-one with the aforementioned remote RPCs. It is defined as follows:
class RemoteTask : public kunlun::ErrorCup {
public:
RemoteTask();
~RemoteTask();
private:
RemoteTask(const RemoteTask &) = delete;
RemoteTask &operator=(const RemoteTask &) = delete;
public:
bool InitRemoteTask(int timeout_sec) ;
bool AddNodeSubChannel(brpc::Channel *sub_channel);
...
// sync run in bthread
bool RunTaskImpl() ;
void RecordeSubChannleReturnValue(const brpc::Controller *cntl, int index) ;
bool AllSubChannelSuccess() ;
void InitPara(std::string &action, std::string ¶s, std::string ¶_tag);
private:
brpc::ParallelChannel remote_channel_;
...
std::string action_;
std::string action_paras_;
std::vector<std::string> sub_channel_return_info_vec_;
rapidjson::Document return_info_json_array_;
// for multi nodemanager action has different paras,
// use this tag to get the right paras
std::string action_paras_tag_;
};
Among them, RunTaskImpl() is a synchronous remote RPC client, executed within a coroutine. Using a synchronous model here does not have adverse effects and does not block external services by itself.
4.2.1 Single Device Remote RPC
Each device in the ClusterManager has a Channel representation. This object can be understood as an encapsulation of a remote HTTP server. Therefore, the preparation work required to implement a REMOTETASK for a single device remote RPC only needs to select a Channel that meets the requirements, execute AllSubChannelSuccess(), and then initialize the task parameters. 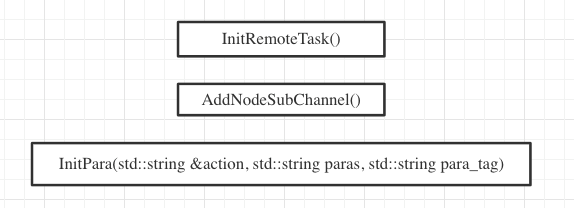
4.2.2 Multi-Device Remote RPC
Some scenarios require executing commands on multiple machines simultaneously and waiting for all devices to succeed or reporting an error and stopping if any failure occurs. This corresponds to the instantiation of a RemoteTask; you only need to add the corresponding channels multiple times. If the parameters for executing tasks on different machines are different, they can be distinguished using tags. 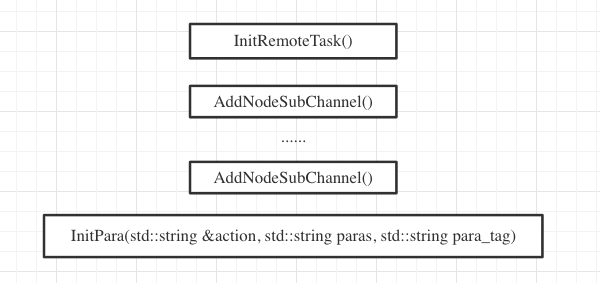
4.3 MissionRequest Object - Complex Task Orchestration and Execution
A complex business request may involve multiple staged tasks; each task may also require multiple physical devices to simultaneously execute related commands through multi-node asynchronous RPC. Therefore, a capability to implement complex remote task orchestration is needed. MissionRequest inherits from ClusterRequest and combines the functionality of REMOTETASK to achieve a unified task execution model and task orchestration model. 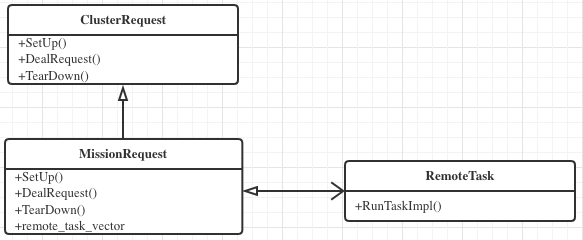
class MissionRequest : public ClusterRequest {
typedef ClusterRequest super;
public:
MissionRequest(google::protobuf::RpcController *cntl_base,
const HttpRequest *request, HttpResponse *response,
google::protobuf::Closure *done)
: super(cntl_base, request, response, done) {
task_manager_ = nullptr;
}
virtual ~MissionRequest();
virtual void SetUpImpl() override final;
// user should add arrange remote task logic
virtual bool ArrangeRemoteTask() = 0;
// user shold add setup logic here
virtual bool SetUpMisson() = 0;
virtual void DealRequest() override final;
virtual void TearDownImpl() override final;
private:
TaskManager *task_manager_;
};
void MissionRequest::SetUpImpl() {
ArrangeRemoteTask();
SetUpMisson();
}
void MissionRequest::DealRequest() {
// do the request iterator vec
auto &task_vec = task_manager_->get_remote_task_vec();
auto iter = task_vec.begin();
for(;iter != task_vec.end();iter++){
bool ret = (*iter)->RunTaskImpl();
if (!ret){
setErr("%s",(*iter)->getErr());
return false;
}
}
return true;
}
void MissionRequest::TearDownImpl() {}
For example, in an expansion scenario, you only need to implement a new Expand instance, which inherits from MissionRequest, and then implement SetUpMission()/DealRequest()/TearDownImpl()/ArrangeRemoteTask(), which can unify the entire expansion task process into the existing task framework.
The logic that ArrangeRemoteTask() needs to implement is simply to instantiate RemoteTask one by one as needed and then put them into the queue. When actually executed, they will be taken out from the queue and executed one by one. 
5. Planning and Outlook
At present, the cluster expansion function has been developed based on the above task coordination framework. In future versions, all cluster management interfaces will be migrated to this framework.
At the same time, in order to better support complex task execution models and meet more cluster management needs, the distributed task scheduling framework is continuously improving. For example, it supports remote subtasks with dependencies and models that automatically orchestrate and manage subtasks using dynamic programming, among others. The goal of the Kunlun team is to simplify the difficulty of implementing complex business logic through more reasonable engineering practice abstractions, laying a solid engineering foundation to provide more stable and reliable cluster management features, enabling KlustronDB to better serve customers and bring greater value to them.